
패스트캠퍼스_비즈니스_빅데이터_분석가_양성과정_5기_이건우
BDA 5기_워크시트_이건우_220630 본문
5주차 온라인강의 학습범위 및 내방특강 :데이터분석1~35및36~60(220624~220630), 파이썬프로그래밍 2일
KDT(MGS BDA 5기) - 한 번에 끝내는 데이터 분석 초격차 패키지 Online.
Python 프로젝트 실습
Starwars
Introduction 데이터분석 with Python
Python 데이터분석실습
- 반복학습의 시작은 어느 데이터나 같다
- 데이터로 어떤 것을 할 수 있는지 질문하기
- 데이터를 분석하고 그래프로 보여주고 대답하기
- 어떤데이터가 더 있으면 좋을지 더 고민하기
- 배워서 쉽게 적용
- 라이선스가 없어도 무료로 사용가능
- 다양하고 예쁜 팔레트와 그래프 툴
- 질문할 곳이 많아지는 만큼 많이 쓰임
스타워즈Starwars API(SWAP)의 데이터로 스타워즈에 등장하는 캐릭터의 특징을 나타낸다.
Starwars 데이터둘러보기 & 질문만들기








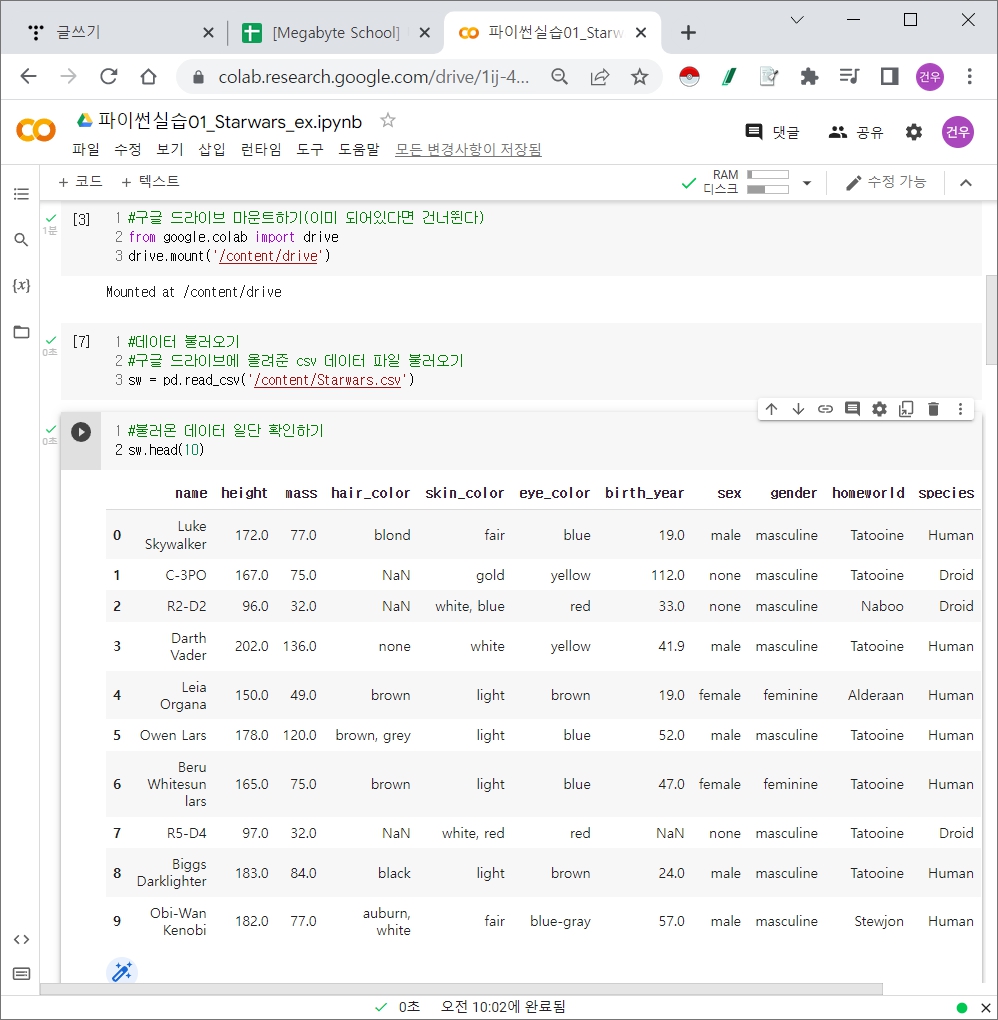





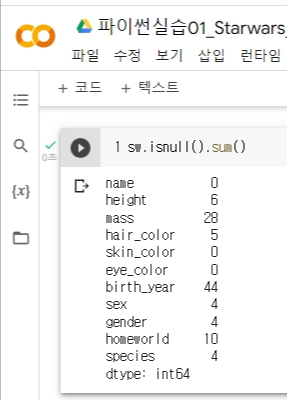


Starwars 데이터 정비하기



Starwars EDA & Visualization
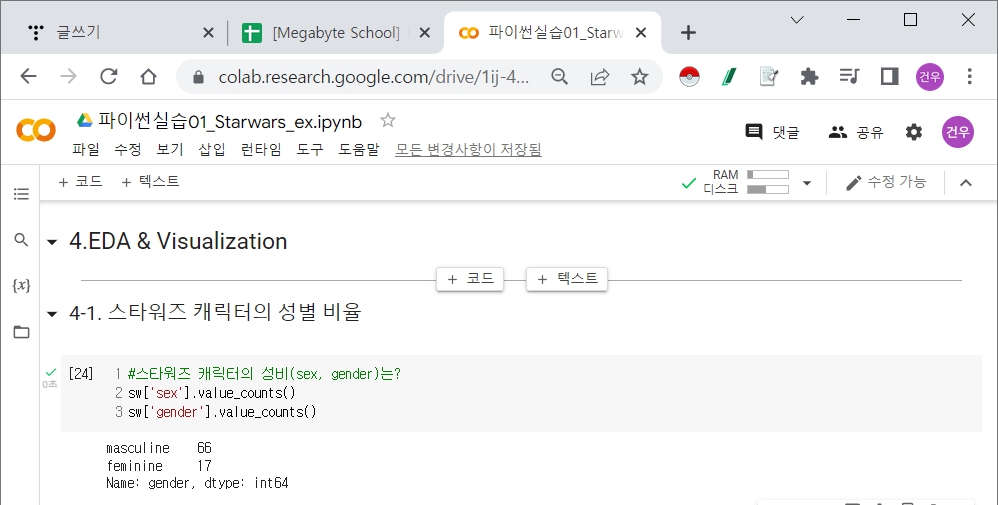











Starwars Review

Lakers
로스엔젤레스 레이커스(LA Lakers)는 미국 캘리포니아주 로스엔젤레스를 연고로 하는 NBA 서부 프로농구팀으로 NBA우승을 여러번 기록한 명문팀이다.
2008-2009시즌의 경기에 대한 기록데이터이다.
Lakers 데이터 둘러보기 & 질문 만들기







Lakers 데이터 정비하기




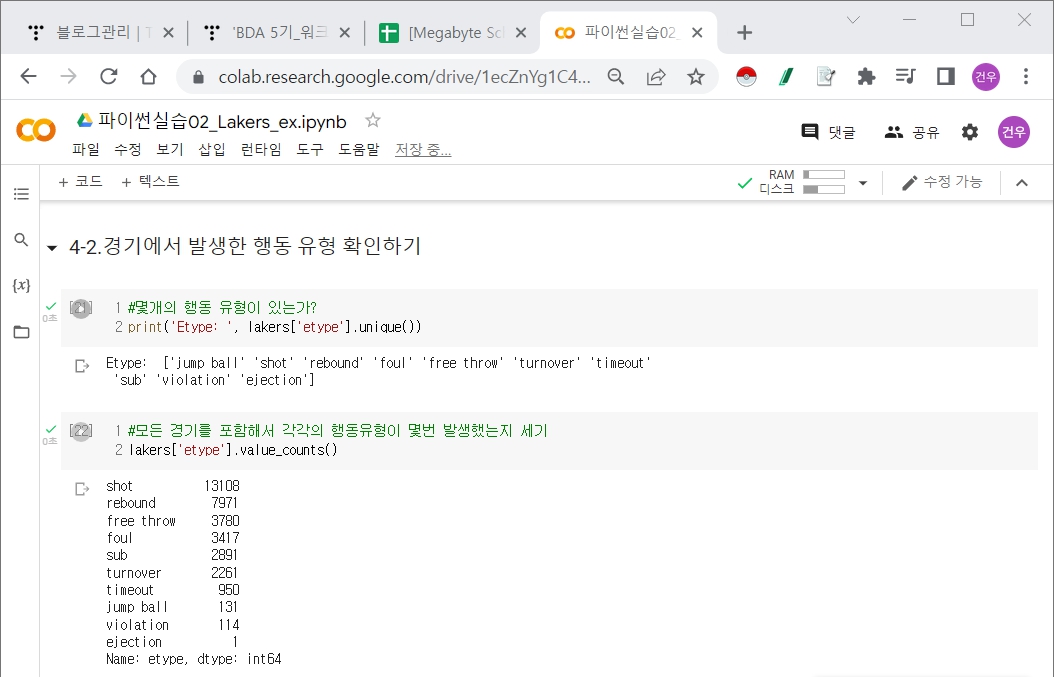
Lakers EDA & Visualization (groupby, barplot)












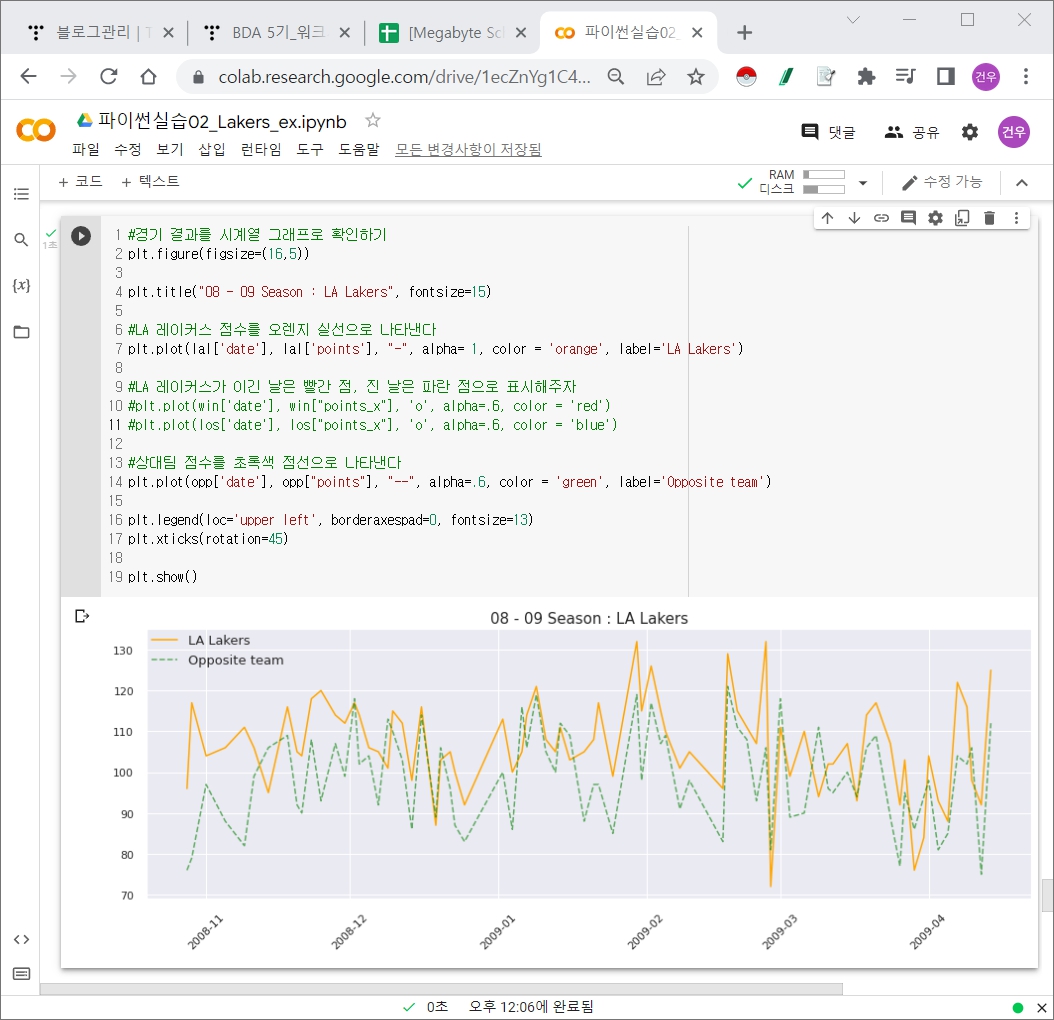
Lakers EDA & Visualization (시계열 그래프, scatter plot)








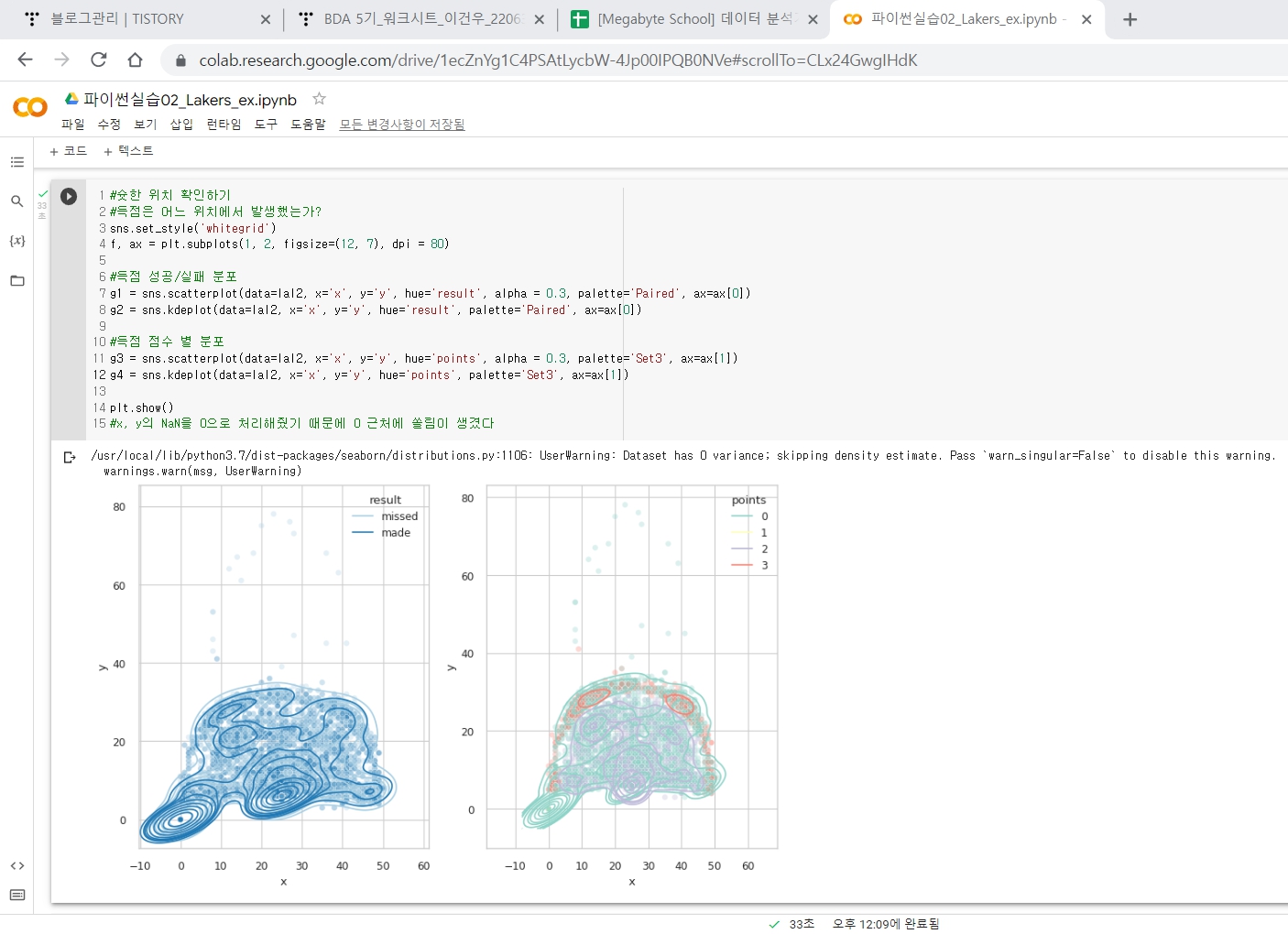
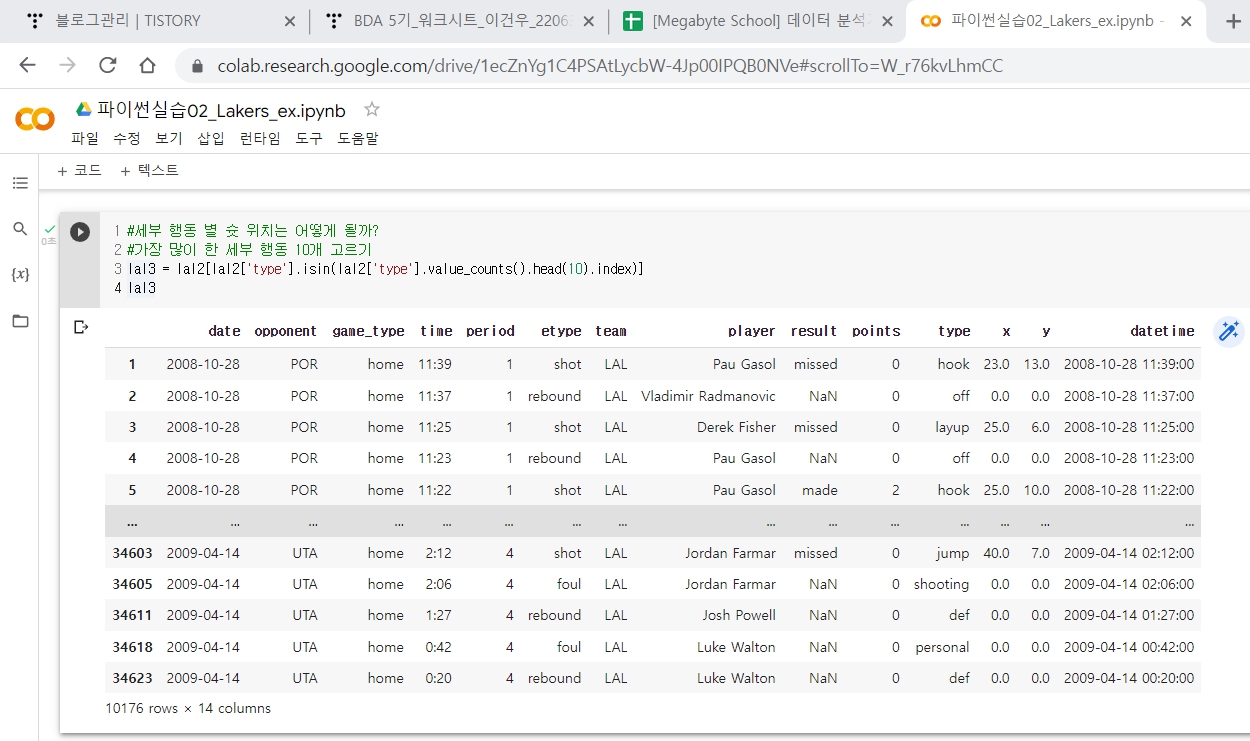

Lakers Review

Commerce (Online retail)
영국에 있는 한 온라인소매점의 2010년1월12일부터 2011년 9월 12일 사이에 발생한 주문내역데이터이다.
Commerce 데이터 둘러보기 & 질문 만들기





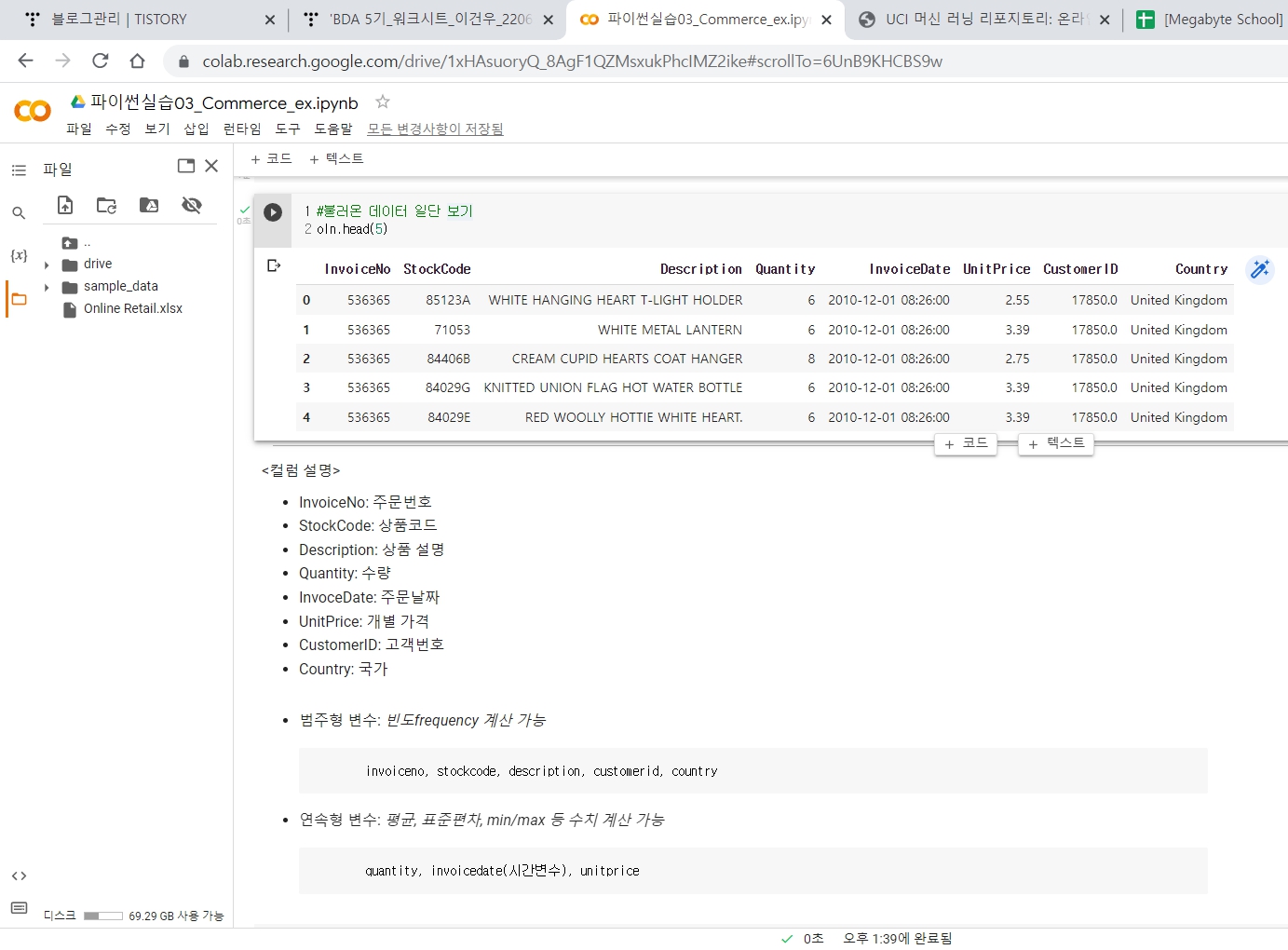


Commerce 데이터 정비하기




Commerce EDA & Visualization (basic plots)



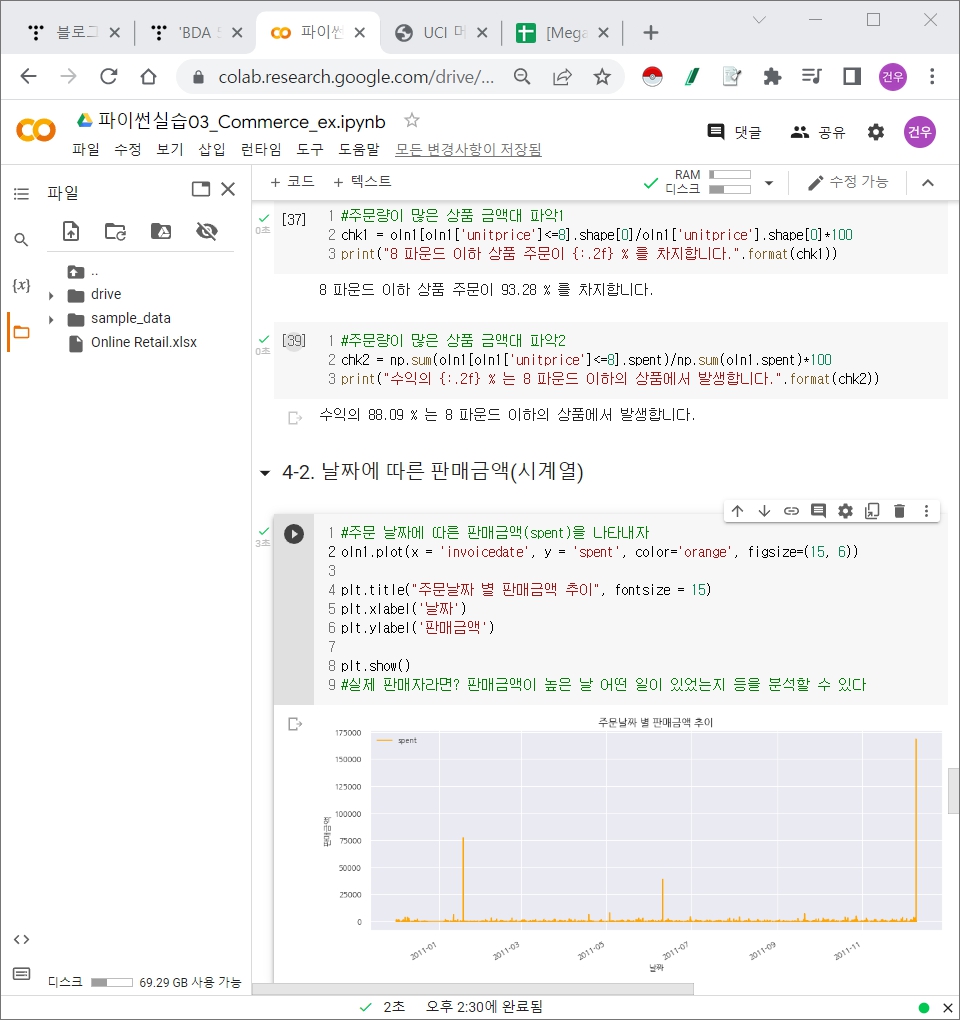





Commerce EDA & Visualization (groupby, wordcloud)










Commerce Review

Superstore
국제배송이 가능한 판매점의 데이터이자 업무를 하면서 가장 많이 만나게 될 데이터
Superstore 데이터 둘러보기 & 질문 만들기





Superstore 데이터 정비하기
Superstore EDA & Visualization (basic plots)
Superstore EDA & Visualization (heat map, pie graph, map)
Superstore Review

Personal Loan
고개을 더 늘리고자 하는 가상의 은행데이터로 이 회사의 경영진은 부채를 가진 고객을 개인대출고객으로 전환하는 방법을 모색하고자 한다. 이 데이터는 금융회사에서 볼 수 있는 목적을 가진 데이터이다.
Personal Loan 데이터 둘러보기 & 질문 만들기




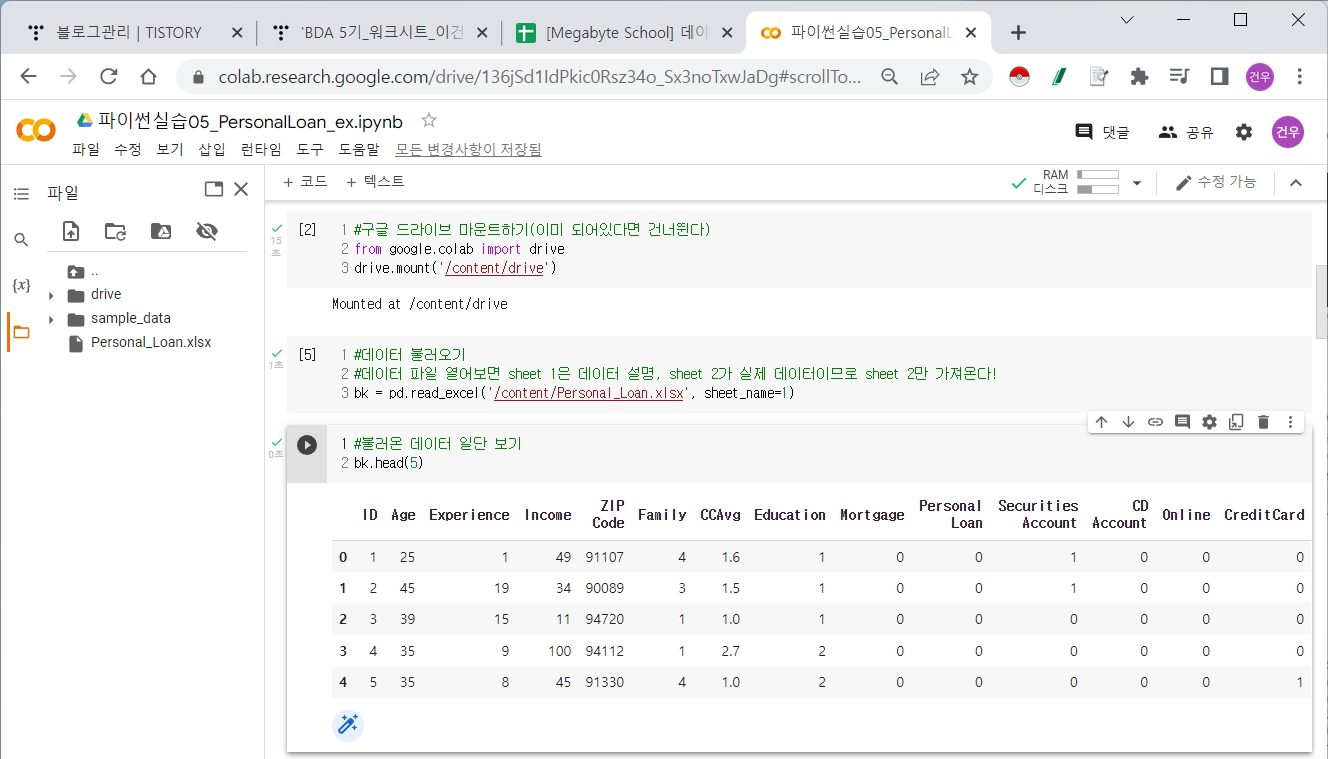





Personal Loan 데이터 정비하기


Personal Loan EDA & Visualization



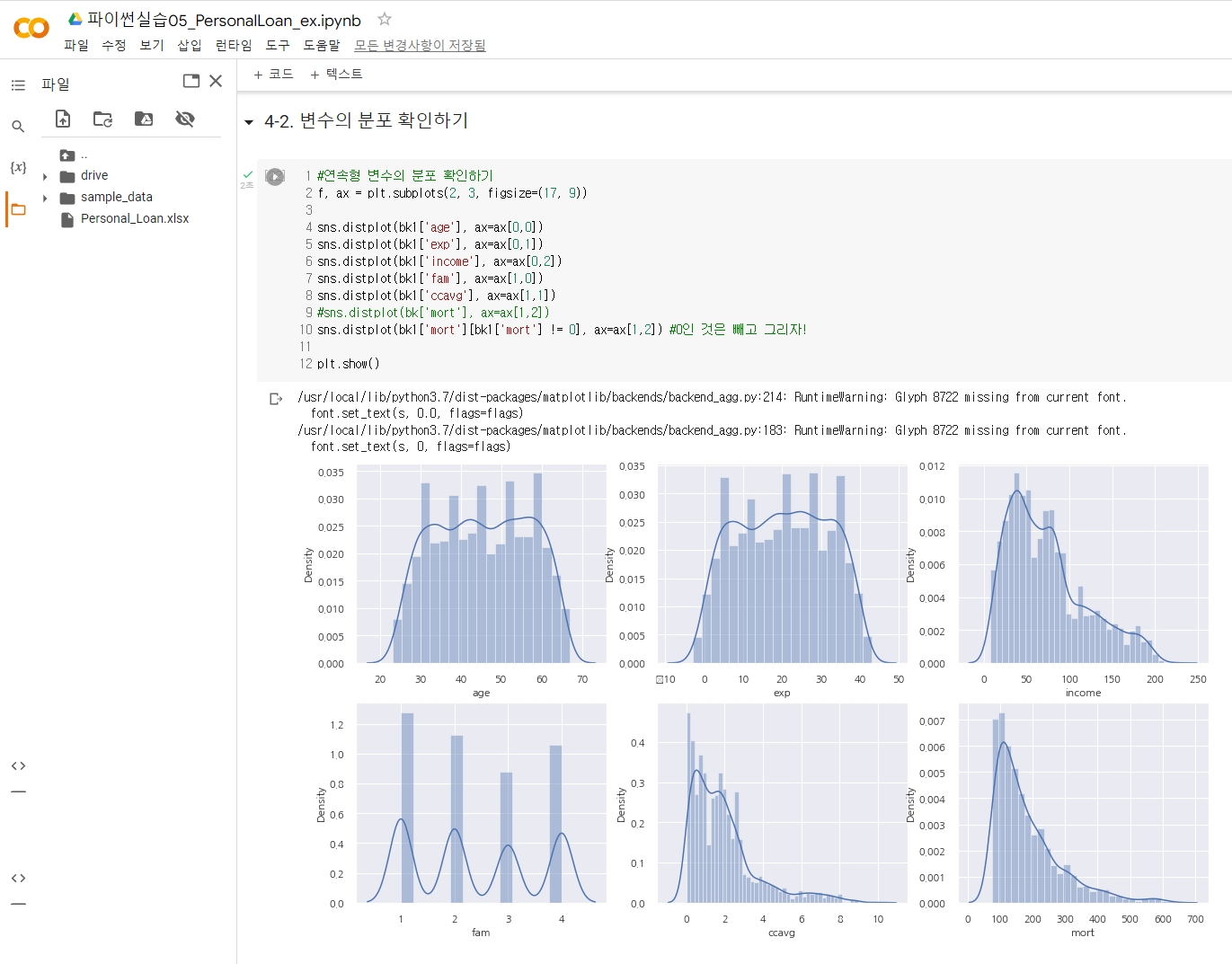






Personal Loan 로지스틱 회귀분석(Logistic Regression) 설명
- 선형회귀분석의 경우 독립과 종속이 비례하지만 로지스틱회귀분석의 경우 비례하지 않고 완만한 S자 형식
- 종속변수와 독립변수 사이의 관계를 함수로 나타내서, 이 사건의 발생가능성을 예측하는 기법
- 독립변수사이의 선형결합으로 종속변수롤 설명하는 것은 선형회귀와 동일
- 종속변수가 범주형데이터를 대상으로 한다는 점
- 범주형데이터를 분류할 수 있기 때문에 분류(classification)기법으로도 분류됨
혼동행렬(Confusion matrix)
예측값
| True(Positive) | False(Negative) | ||
| 실제값 | True | True Positive, 실제값도 참 예측값도 참 | False Negative, 실제값은 참 예측값은 거짓 |
| False | False Positive, 실제값은 거짓 예측값은 참 | True Negative, 실제값도 거짓 예측값도 거짓 |
- 분류모델의 성능을 평가하는 지표
- 실제값(actual)과 비교해서 모델(predict)이 얼마나 정확하게 예측했는지 알아볼 수 있도록 한 2*2행렬
- 정확도(Accuracy)는 모델이 바르게 분류한 부분의 비율로, 혼동행렬에서 대각선 부분
Personal Loan 로지스틱 회귀분석 실습



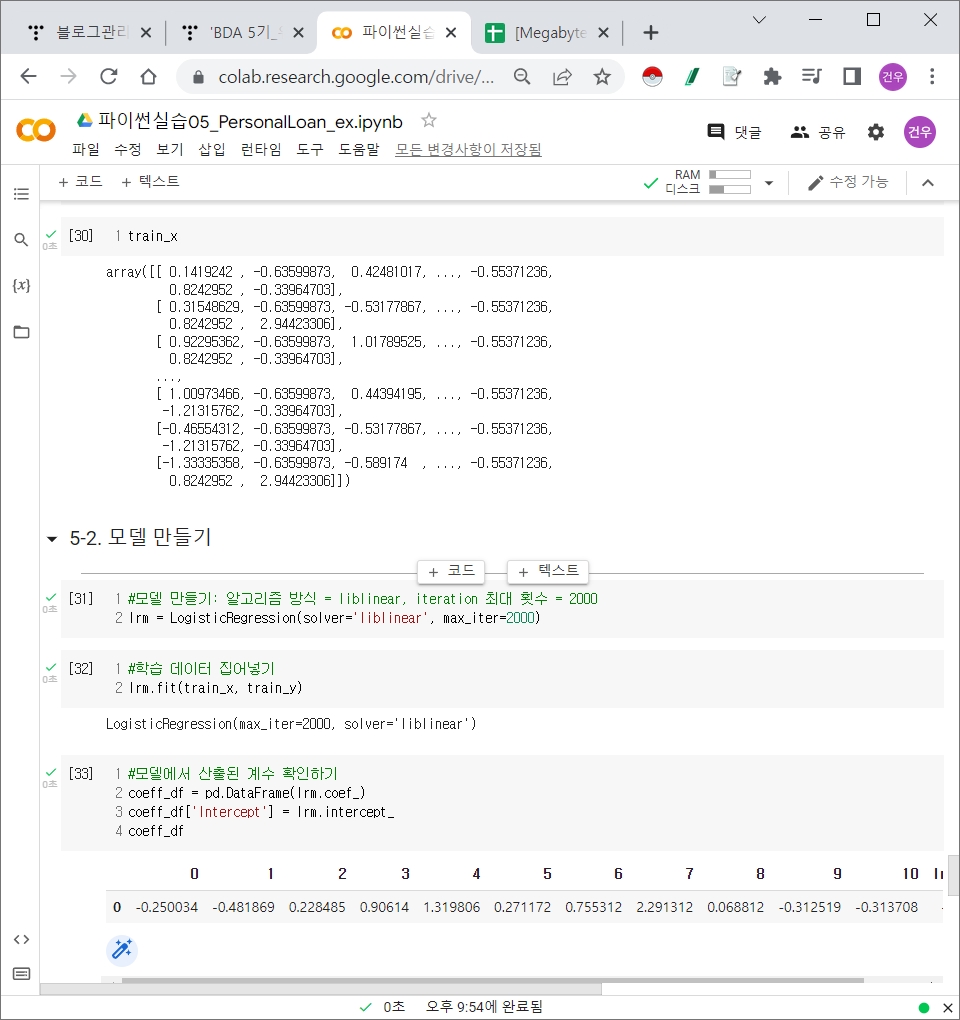



Personal Loan Review

따릉이
- 서울 열린데이터 광장에서 제공하는 서울시 공공자전거 따릉이 이용현황 데이터모음
- 공공자전거대여소정보, 대여소별 이용정보, 시간대별 이용정보 등을 제공함
데이터수집
- 실험, 인터뷰로 직접 생성
- 공공기관에서 개방한 데이터인 공공데이터
- 머신러닝을 연습하기 좋은 데이터 Kaggle
- 스크래핑, 크롤링으로 웹을 수집
서울열린데이터광장
- 서울열린데이터 광장에는 연구, 관리, 서비스제공
- 서울시 시정활동과정에서 수집된 다양한 데이터를 보유
- 보건, 일반행정, 문화 및 관광 등의 다양한 분야의 데이터를 내려받아 활용가능함
Kaggle
- 2010년 설립된 분석 및 예측모델대회 플랫폼
- 머신러닝을 연습하기 적합한 다양한 데이터를 찾을 수 있으며, 다른 개발자들이 제작한 코드도 구경해 볼 수 있다.
스크래핑 및 크롤링
- 웹에서 정보를 가져올 때, 스크래핑 및 크롤링을 사용해서 정보를 추출
- 뉴스기사, 검색어, 주식정보, SNS댓글 등 수집가능
따릉이 데이터 소개 및 데이터 수집방법

따릉이 데이터 둘러보기 & 질문 만들기












따릉이 데이터 정비하기














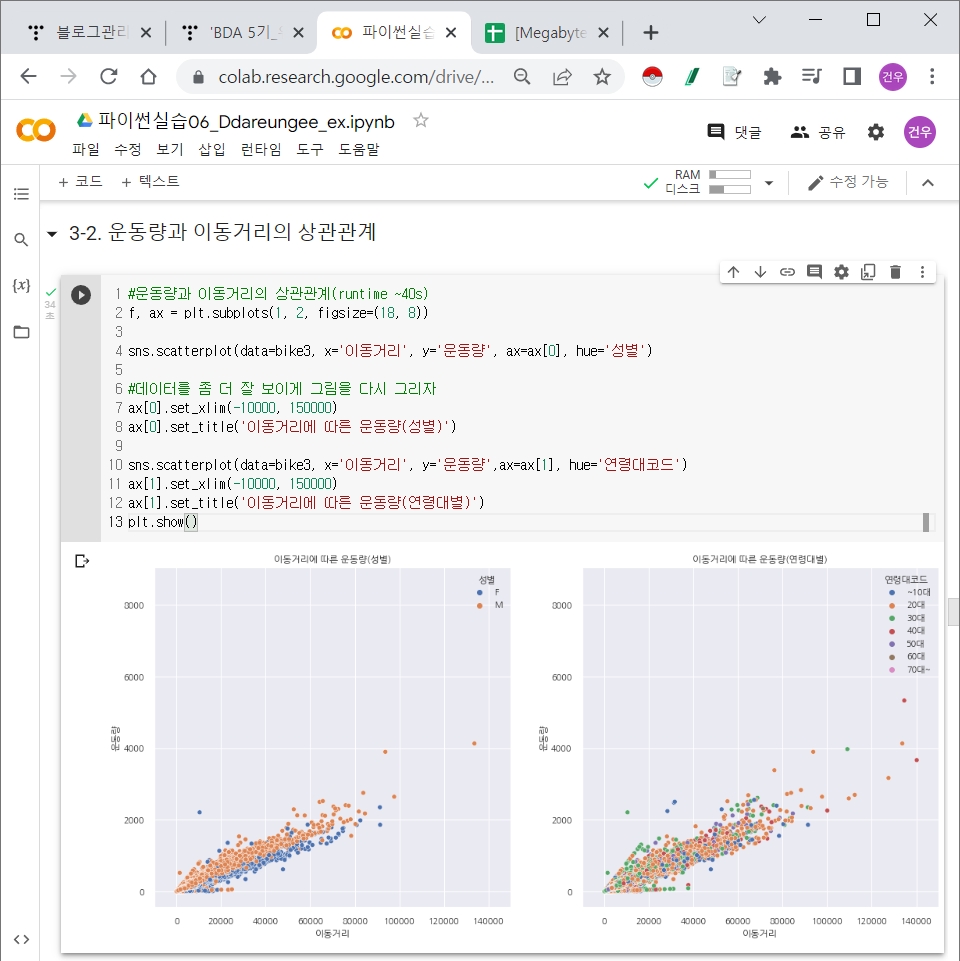
따릉이 EDA & Visualization (basic plots)






따릉이 EDA & Visualization (서울 지도위에 데이터 나타내기)












따릉이 Review

Airbnb
- 2008년 8월 시작된 세계 최대의 숙박 공유서비스
- 자신의 방이나 집, 별장 등 사람이 지낼 수 있는 모든 공간을 임대
- 이 데이터는 2019년 뉴욕에서 업데이트된 에어비앤비 리스트
- 에어비앤비에 등록된 호스트들의 목록이 있는 데이터셋
Airbnb 데이터 둘러보기 & 질문 만들기



Airbnb 데이터 정비하기

Airbnb EDA & Visualization (1)

Airbnb EDA & Visualization (2)


Airbnb 선형회귀분석

Airbnb Review

Wine
- 포르투갈 비노 베르데(Vinho Verde)지역의 레드와 화이트와인의 데이터가 들어있는 데이터셋
- 1980년대까지는 주로 스파클링 레드와인이 생산되다가 이후 상황이 역전되어 현재 모든 비노 베르데의 85%정도가 화이트와인
- 와인에 영향을 주는 요소들과 와인 평점이 있는 데이터셋임
데이터 둘러보기 & 질문 만들기



Wine 데이터 정비하기

WIne EDA & Visualization

Wine Logistic vs. SVM vs. Random Forest (설명)
로지스틱 회귀분석(Logistic Regression) 설명
- 선형회귀분석의 경우 독립과 종속이 비례하지만 로지스틱회귀분석의 경우 비례하지 않고 완만한 S자 형식
- 종속변수와 독립변수 사이의 관계를 함수로 나타내서, 이 사건의 발생가능성을 예측하는 기법
- 독립변수사이의 선형결합으로 종속변수롤 설명하는 것은 선형회귀와 동일
- 종속변수가 범주형데이터를 대상으로 한다는 점
- 범주형데이터를 분류할 수 있기 때문에 분류(classification)기법으로도 분류됨
서포트 벡터머신(support vector machine, SVM)
- 머신러닝 중 하나로 패턴인식, 자료분석을 위한 지도학습모델이며, 주로 분류와 회귀분석을 위해 사용
- 두 분류로 나눠진 집합이 주어졌을 때, SVM알고리즘은 주어진 데이터집합을 학습해서 새로운 데이터가 어느집합에 속할지 판단하는 비확률적 이진선형분류모델을 만듬
랜덤포레스트(RandomForest Classifier)
- 분류, 회귀분석 등에 사용되는 머신러닝의 방법으로 앙상블학습방법의 일종
- 학습과정에서 다수의 결정트리를 만들고, 그 분류를 집계해서 최종분류결과를 만듬
- 랜덤하게 트리를 구성함으로써 오버피팅을 피함
예측값
| True(Positive) | False(Negative) | ||
| 실제값 | True | True Positive, 실제값도 참 예측값도 참 | False Negative, 실제값은 참 예측값은 거짓 |
| False | False Positive, 실제값은 거짓 예측값은 참 | True Negative, 실제값도 거짓 예측값도 거짓 |
(예측값*실제값)
Accuracy(정확도) =(True Positive=True*True)*(True Negative=False*False)
- 모델이 바르게 분류한 부분의 비율로 혼동행렬에서 대각선 부분
Precision(정밀도)=(True Positive=True*True)*(False Positive=True*False)
- 모델이 positive로 분류한 것 중 실제값이 positive인 비율
Recall(재현도)=(True Positive=True*True)*(False Negative=False*True)
- 실제값이 positive인 것 중 모델이 positive라고 분류한 비율
F1 Score=(True Positive)/(False Positive)&(False Negative)
- Precision과 Recall의 조화평균 데이터가 불균형할 때 F1 Score를 사용
Wine Logistic vs. SVM vs. Random Forest (실습)



Wine Review

Restaurant
- Zomato는 2008년에 설립된 인도의 다국적 레스토랑 통합 및 음식배달회사
- Zomato사이트에서는 레스토랑에 대한 정보, 메뉴 및 사용자리뷰가 제공
- 2019년 기준 24개국 10000개 이상의 도시에서 서비스를 제공
- 레스토랑리뷰가 포함된 데이터셋
Restaurant 데이터 둘러보기 & 질문 만들기





Restaurant 데이터 정비하기

Restaurant EDA & Visualization




Restaurant 텍스트 클라우드(Wordcloud)

Restaurant 감정분석

Restaurant Review

(Web) Crawling
- 크롤링은 검색엔진을 활용한 데이터수집방법
- 뉴스, SNS, 웹사이트처럼 외부로 공개된 웹문서를 그대로 가져와서 데이터를 추출
웹 스크래핑(Web Scraping)
- 스크린 스크래핑(Screen scraping)은 웹화면 상에 출력되는 데이터 중, 내가 필요한 데이터만 추출하는 기술
- 웹사이트에서 데이터를 수집하고, 변환한 후 적재하는 핵심기술
크롤링과 스크래핑의 차이
- 지속적으로 사이트를 탐색하면서 해당 사이트에서 얻을 수 있는 모든 것을 가져오는 크롤링
- 사용자가 원하거나 지정한 특정정보만 가져오는 스크래핑
HTML
- 웹문서를 만들기 위해 사용하는 기본적인 언어
- 인터넷에서 사용되는 대부분의 페이지는 HTML
- HTML은 웹페이지의 글자크기, 색, 버튼, 이미지 등을 정의하는데 tag라고 불리는 <>를 사용
| <!DOCTYPE html> <!--주석 달기--> <html> <head> W여기에는 제목이 들어갑니다 </head> <body> 여기에는 본문의 내용이 들어가는 부분입니다 </body> </html> |
Crawling BeautifulSoup 활용하기
BeautifulSoup로 웹페이지 긁어오기



네이버 기사제목 긁어오기

'올림픽'




'양궁'


Crawling Selenium 활용하기

Selenium (Jupyter Notebook)













유튜브 댓글 가져오기




데이터분석을 위한 파이썬 프로그래밍 활용 특강
Data의 정의
프로그램을 운용할 수 있는 형태로 숫자화, 기호화된 자료
이론을 세우는데 기초가 되는 사실 혹은 자료
정보 그리고 데이터 (Information, data)
관찰이나 측정을 통해 수집된 데이터를 실제 문제에 도움이 될 수 있도록 해석하고 정리한 지식
정보는 데이터인데 모든 데이터가 정보가 되지 않는다.
Data의 목적
데이터를 통한 정보를 생산하는 것
같은 데이터라도 생산되는 정보는 많다.
데이터과학(Data Science)
데이터를 대상으로 실험하고 연구하는 학문
데이터를 기반으로 실험과 연구를 통해 정보를 생산하는 기술
사회과학, 자연과학, 데이터과학?
데이터는 인류가 문명으로 이룩한 사회과학, 자연과학을 토대로 누적하고 생성
데이터를 대상으로 하기에 특정영역을 넘어서 다양한 필드에서 활용됨
Data Scientist
데이터를 다루고 실험과 연구를 거쳐 정보를 생산하는 자, 그럼 실제로는?
(파이썬)Python?
1991년 발표되었으며 초기 수학자, 과학자들이 수치, 실험용 데이터를 다루기 위해 사용
웹 개발자들이 같은 레이아웃을 가진 페이지의 효율성 부각됨
이후 데이터분석으로 각광받으면서 지금은 머신러닝, 딥러닝의 높은 효율을 갖는 오픈소스 프로그래밍언어
프로그래밍을 처음 접하는 일반인이 배우기 쉽긴 하다.
데이터분석, 웹개발, 프로그램개발, AI모델링 등 다양한 목적으로 활용됨
데이터를 폭발적으로 생산하는 시대
지수적으로 늘어나는 데이터의 생산량
온라인기반활동이 늘며 데이터의 생산 및 누적이 쉬워짐
우리나라의 경우 IT인프라 기준 데이터생산 세계6위
실제 데이터를 기반으로 생산활동은? (SSG.com 일일데이터 4GB추정)
컴퓨팅환경
CPU 및 GPU기반 연산속도 증가
기존 컴퓨팅환경으로 오랜기간이 걸리던 작업들이 가능
Python 등 오픈소스기반의 프로그래밍언어의 대중화
할 일은?
경쟁사가 혹은 타부서에서 데이터를 활용한 잠재고객유치, 혹은 마케팅 툴을 개발
이 소식을 알게 된 이후의 반응은?
우리가 살아남기 위해 할 일은?
필요한 커리큘럼은?
파이썬 기초 프로그래밍
- 데이터 분석에 필요한 기본적인 파이썬 문법을 학습
- if, elif, else, for, breaks, try, functions, class
데이터분석 패키지
- 데이터분석에 필요한 기본적인 패키지를 학습
- numpy, pandas 를 활용하여 추후 커리큘럼에 필요한 사전지식 습득
크롤링 프로젝트
- 프로젝트 기획을 통해 현업프로젝트의 가능성과 방향성을 체크
jupyter notebook 실행 및 셋팅





python basic







python sequence






python controlflow











python function class













'데이터분석_워크시트' 카테고리의 다른 글
| BDA 5기_워크시트_이건우_220721 (0) | 2022.07.15 |
|---|---|
| BDA 5기_워크시트_이건우_220707 (0) | 2022.07.01 |
| BDA 5기_워크시트_이건우_220623 (0) | 2022.06.17 |
| BDA 5기_워크시트_이건우_220616 (0) | 2022.06.10 |
| BDA 5기_워크시트_이건우_220609 (0) | 2022.06.08 |



