
패스트캠퍼스_비즈니스_빅데이터_분석가_양성과정_5기_이건우
BDA 5기_워크시트_이건우_220616 본문
3주차 온라인강의 학습범위(클립번호 합산기준): UX/UI디자인1~18, SQL패키지1~85, 데이터분석 툴(SQL)1~33(220610~220616)
KDT(MGS BDA 5기) - 한번에 끝내는 UX/UI 디자인 초격차 패키지 Online
Figma를 시작하며
figma란 본인의 생각을 잘 표현하게 해주는 툴이다.
예) 프로젝트
사진공유기능 개발해서 목표클릭수에 기여하자!-->> 이번신규프로젝트 홍보해야하는데 PPT급히구함-->>이번프로모션으로 매출10% 올리자!
예2) 그들의 페인포인트
윈도우에선 디자인파일이 안열린다고? -->> 프로그램다운받아야 디자인파일 볼 수 있다고? -->> 최신파일 받으려면 디자이너 출근할 때까지 기다려야돼? -->> 프로그램쓰려면 대가를 지불해야한다고??
예3) 빠르고 직관적 공유 및 피드백반영
링크확인부탁드립니다 -->> 이 아이콘 색 바꿔주세요 -->> 되었습니다! 링크 다시 확인해주세요
UI드로잉
벡터기반+빠른 비트맵요소렌더링, 독특한 path 컨트롤로
UI를 위한 요소 빠르게 구현
텍스트 도형, 효과, 이미지, 그리드, path, 애니메이션 등 간단한 프로토타이핑 및 애니매이션 신속한 구현이 가능
다양한 목적으로 응용이 가능하며 요소들을 재정의하거나 결합
-> 프레젠테이션, 애니메이션, 일러스트레이션, 브레인스토밍, 태스크매니징 등의 목적으로 응용가능
일단 무상으로 충분한 프로젝트 수행 가능
유료로 제공하는 기능은 프로젝트와 피그마숙련도가 고도화된 이후 더 빛을 발한다.
시스템적 이용
컴포넌트기능은 재사용이나무 수정이 용이한 디자인으로 구성
라이브러리기능은 컴포넌트와 스타일의 고도화된 시스템화 가능
실시간저장
클라우드 기반 자동저장을 Ctrl+S가 피그마에 없는 단축키인데 모든 사용자에게 라이브러리 실시간 배포 가능
배포되면 업데이트버튼을 눌ㄹ 최신 라이브러리의 컴포넌트 적용 가능
버전별 배포로 버전히스토리패널에 현재상태를 저장 가능(무료버전은 시작부터 30일까지)
피그마는 무료지만 유료?
Pricing에서 무료버전 1가지(30일까지)와 더 많은 기능을 사용할 수 있는 유료버전 2가지의 선택지를 제공해요.



링크공유방식
피그마 클라이언트 설치










인터페이스 이해하기
피그마 첫 실행, 새파일 만들기










좌측패널









좌상단 마우스툴

move 및 scale기능

frame 및 slice기능

도형 및 이미지 생성기능

pen 및 pencil기능

텍스트기능

손기능

코멘트기능

상단 가운데 반응형 패널
우측패널 share and viewing
우측패널 design mode
우측패널 prototype mode
우측패널 code mode
자주 사용할 단축키
file & Properties
Ctrl + Alt + S: Save to Version History
Edit
Ctrl + C: Copy(복사)
Ctrl + X: Cut(잘라내기)
Ctrl + V: Paste(붙여넣기)
Ctrl + Shift + V: Paste Over Selection(선택한대로 붙여넣기)
Alt + drag: Resize from Center
(마우스클릭한 상태에서 끌기)
View
Space + drag: Pan
Arrange
Ctrl + ]: Bring Forward
Ctrl + [: Send Forward
Ctrl + Shift + ]: Bring to Front
Ctrl + Shift + [: Bring to Back
Tools
V: Move(이동)
C: Add/Show comments(대화창 추가/보이기)
P: Pen(펜)
R: Rectangle(사각형)
O: Ellipse(원, 구)
L: Line(선)
F: Frame
Text
Ctrl + Shift + V: Paste and Match Style
Object
Ctrl + G: Group Selection(그룹 선택)
Ctrl + Shift + G: Ungroup Selection(그룹 해제 선택)
Ctrl + Shift + L: Lock/Unlock selection(잠금/해제 선택)
Ctrl + E: Flatten Selection
Ctrl + Shift + O: Outline Stroke
Alt + doubleclick: Crop Image
(마우스로 더블클릭)
Components
Ctrl + Alt + K: Create Components
Ctrl + Alt + B: Detach Instance(연동해제)
Align
| top: w | ||
| left: a | horizontal centers: h vertical centers: v |
right: d |
| bottom: s |
More options: t
Opacity
1~0과 상관없이 숫자를 빠르게 두번 누르면 세세한 투명도 조절
스크린샷
빅데이터를 위한 UX/UI특강에도 반영포함
좋은 디자인의 특징과 규칙
좋은디자인은 혁신적이고 제품을 유용하게 하며 아름답고 제품의 이해를 도우며 눈에 띄지 않고 정직하며 오래간다.
마지막 디테일에서 나오는 필연적인 결과이며 환경을 생각하고 가능한 최소한으로 좋은 디자인을 한다.
21세기 디자인 방법론의 공통된 방향성
디자인씽킹, 서미스디자인, 센스메이킹, 파괴적혁신으로 보이지 않는 문제와 욕구를 발견하라.
그렇다면 사용자 경험은 무엇인가?
디자이너의 세계속에서 만들어진 언어: 서비스디자인, 디자인씽킹
사용자 경험(UX)디자인: 인지과학자의 세계속에서 만들어진 언어
UX디자인
이후 UX의 의미를 확장시켰다.
Sense Making, Sevice Design, Design Thinking이다. 이외에도 Userbillity도 포함된다.
UX디자인은 UI를 투영한다.
User Interface가 무엇인가?
face에 inter를 사이에 두고 face이다. 사람들과 서비스가 닿는 곳이 interface이다.
inter가 의미하는 것은? 전기요금고지서, 웹페이지, 법인등록신청서, 메뉴판, 전기밥솥버튼, 소프트웨어의 조작버튼들이다.
좋은 UX의 요소
사건을 디자인하고
부드럽고 깨끗한 사건을 만든다.
손을 잡아주어야 하는 사건속에서 우리가 만드는 이것은 어떤 제품이어야 하는가?
대상과 상황을 분리하지 않는다.
세계에서 이 장비는 좋은장비인가? MRI장비의 다양한 관점은?
두려움이 많은 아이, 조심스러운 수리기사, 검사방법안내에 지친 검사자,수리비용이 부담스러운 병원, 질문에 지친 간호사검사실적에 시달리는 의사
발렌타이데이에 견과규를 판다고?
주관과 객관의 균형으로
유아동코너에서 사골곰탄이 잘 팔리는 이유는 뭘까?
학생만족도 조사는 높은데 학생들은 코딩이 왜 안되는 걸까?
-> 데이터로는 볼 수 없는 것들이다.
관찰 그 생생한 만남
그 아이디어는 어디에서 오는가?
시스템을 디자인하라.
KDT(MGS BDA 5기) - 가장 쉽게 시작하는 데이터 분석, SQL 유치원 Online.
조건에 맞는 데이터 가져오기
우리가 하게 될 데이터요청은
"10번 이상 구매한 특별고객리스트를 뽑아주세요"
"매출 5천만원 이상의 상품리스트를 뽑아주세요"
조건에 맞는 데이터를 가져오는 방법이다.
WHERE[조건식]형식으로 사용하며 조건식이 True(참)이 되는 로우만 선택한다.
SELECT[컬럼이름] FROM[테이블이름] WHERE 조건식;
조건식
작성하는데는 다양한 방식이 있으며, 보통 연산자를 사용하여 작성하고 원하는 데이터의 조건이 True(참)이 되도록 조건식을 만드는 것이다.
True(참) 예시
1=1; 100>10; "A" IN ("A", "B", "C")
False(참)예시
1=2 100<10; "D" IN ("A", "B", "C")
엑셀과 동일
연산자종류
비교연산자-> clip2
=,>,<
비교연산자-> clip3
NOT, AND, OR
비교연산자-> clip4
BETWEEN, IN
비교연산자
| 연산자 | 활용 | 의미 | 예시 |
| = | A=B | A와 B가 같다 | 1 = 1 |
| != | A!=B | A와 B가 같지 않다 | 1 != 2 |
| > | A>B | A가 B보다 크다 | 10 > 1 |
| >= | A>=B | A가 B보다 크거나 작다 | 10 >= 1 |
| < | A<B | A가 B보다 작다 | 10 < 100 |
| <= | A<=B | A가 B보다 작거나 같다 | 10 <= 10 |
=사용예제
피카츄의 number를 찾는 요청
쿼리는 SELECT number FROM mypokemon WHERE name = 'pikachu'; # 테이블 사용(USE) 명시했다고 가정
결과는
| number |
| 25 |
>사용예제
속도가 50보다 큰 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE speed > 50;
!=사용예제
전기타입이 아닌 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE type != 'electric';
조건식에 논리조건을 적용하는 기호, 논리연산자
| 연산자 | 활용 | 의미 |
| AND | A AND B | A와 B 모두 True이면 True |
| OR | A OR B | A와 둘 중 하나만 True이면 True |
| NOT | NOT A | A가 아니면 True |
AND 사용예제
속도가 100이하인 전기타입 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE speed <= 100 AND type='electric';
OR 사용예제
벌레타입이거나 노말타입인 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE type = 'bug' OR type = 'normal';
NOT 사용예제
속도가 100이하이고 벌레타입이 아닌 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE speed <= 100 AND NOT(type = 'bug'); # type != bug와 동일
팁. 동일한 요청에도 쿼리를 만드는 법은 다양하다.
기타주요연산자
특정 범위 내의 데이터를 선택할 때 사용하는 연산자 BETWEEN의 특징은
- [컬럼이름] BETWEEN A AND B 형식으로 사용
- 해당 컬럼 값이 A와 B 사이에 포함되는 값을 가진 로우만 선택 (A <= 컬럼값 <= B)
- [컬럼이름] BETWEEN A AND B 쿼리는 A <= [컬럼이름] AND [컬럼이름] <= B와 동일
BETWEEN 쿼리문법
SELECT [컬럼이름] FROM [테이블이름] WHERE[컬럼이름] BETWEEN [조건1] AND [조건2];
BETWEEN 사용예제
속도가 50과 100사이인 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE speed BETWEEN 50 AND 100;
목적 내 포함되는 데이터를 선택할 때 사용하는 연산자 IN의 특징
- [컬럼이름] IN (A, B, ..., C) 형식으로 사용
- 해당컬럼의 값이 '( )' 내의 값에 포함되는 값을 가진 로우만 선택
- [컬럼이름] IN (A, B) 쿼리는 [컬럼이름] = A OR [컬럼이름] = B와 동일
- 목록에 넣을 값이 여러개일 때, OR 연산자보다 표현 및 이해가 쉽습니다.
IN 쿼리문법
SELECT [컬럼이름] FROM [테이블이름] WHERE [컬럼이름] IN ([조건1], [조건2], ...);
IN 사용예제
벌레타입이거나 노말타입인 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE type IN ('bug', 'normal');
문자형데이터다루기
특정문자열이 포함된 데이터를 선택하는 연산자 LIKE의 특징
[컬럼이름] LIKE [검색할 문자열] 형식으로 사용
해당 컬럼값이 [검색할 문자열]을 포함하고 있는 로우만 선택
[검색할 문자열] 내에 와일드카드를 사용하여 검색조건을 구체적으로 표현
와일드카드(엑셀문법과 유사)
| 와일드카드 | 의미 |
| % | 0개 이상의 문자 |
| _ | 1개의 문자 |
몇개의 문자일까요?
"%": 0개 이상의 문자 = 알 수 없다.
"_": 1개
"__": 2개
"_%": 1개 이상의 문자 = 알 수 없음
% 사용예제
'%e' e로 끝나는 문자열은 e, ee, eevee, apple, pineapple
'e%' e로 끝나는 문자열은 e, ee, eevee, eric
'%e%' e로 끝나는 문자열은 e, ee, eevee, apple, pineapple, aespa
_ 사용예제
'_e' e로 끝나고 e앞에 1개의 문자가 있는 문자열은 ae, ee, ce
'%_e' e로 끝나고 e앞에 1개이상의 문자가 있는 문자열은 ee, eevee, apple, pineapple
'%_e_%' e를 포함하고 e앞 뒤로 각각 1개이상의 문자가 있는 문자열은 eevee, aespa
LIKE 쿼리문법
SELECT [컬럼이름] FROM [테이블이름] WHERE [컬럼이름] LIKE [검색할 문자열];
LIKE사용예제1
이름이 'chu'로 끝나는 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE name LIKE '%chu';
LIKE사용예제2
이름에 'a'가 포함되는 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE name LIKE '%a%';
데이터값이 존재하지 않는다는 표현하며 0이나 공백이 아닌 알 수 없는 값을 의미하는 NULL 데이터를 다루는데...
쿼리는 INSERT INTO mypokemon (name, type) VALUES ('kkobugi', '');
SELECT * FROM mypokemon;
데이터가 NULL인지 아닌지를 확인하는 연산자 IS NULL의 특징
- [컬럼이름] IS NULL 형식으로 사용
- 해당컬럼이 NULL이 있는 로우(행)만 선택
- NULL이 아닌 데이터를 검색한다면 IS NOT NULL을 사용
- [컬럼이름] = NULL 또는 [컬럼이름] != NULL과 같은 표현은 사용하지 않는다.
쿼리문법
SELECT [컬럼이름] FROM [테이블이름] WHERE [컬럼이름] IS NULL;
IS NULL 사용예제
number가 null인 포켓몬의 이름을 찾는 요청
쿼리는 SELECT name FROM mypokemon WHERE number IS NULL; # *number=NULL은 사용불가
IS NOT NULL 사용예제
쿼리는 SELECT name FROM mypokemon WHERE type IS NOT NULL;
주어진조건에 맞는 데이터를 가져오는 실습(WHERE)
테이블에서 데이터를 가져오기
포켓몬정보표와 데이터입력쿼리는 BDA 5기_워크시트_이건우_220609에서 참고
문제1. 이브이의 타입을 가져오기

문제2. 캐터피의 공격력과 방어력을 가져오기

문제3. 몸무게가 6kg보다 큰 포켓몬들의 모든 데이터를 가져오기

문제4. 키가 0.5m보다 크고, 몸무게가 6kg보다 크거나 같은 포켓몬들의 이름을 가져오기

문제5. 포켓몬 테이블에서 공격력이 50미만이거나, 방어력이 50미만인 포켓몬들의 이름을 'weak_pokemon'이라는 별명으로 가져오기

문제6. 노말타입이 아닌 포켓몬들의 데이터를 전부 가져오기


문제7. 타입이(normal, fire, water, grass) 중에 하나인 포켓몬들의 이름과 타입을 가져오기

문제8. 공격력이 40과 60사이인 포켓몬들의 이름과 공격력을 가져오기


문제9. 이름에 'e'가 포함되는 포켓몬들의 이름을 가져오기

문제10. 이름에 'i'가 포함되고, 속도가 50이하인 포켓몬데이터를 전부 가져오기

문제11. 이름이 'chu'로 끝나는 포켓몬들의 이름, 키, 몸무게를 가져오기

문제12. 이름이 'e'로 끝나고, 방어력이 50미만인 포켓몬들의 이름, 방어력을 가져오기

문제13. 공격력과 방어력의 차이가 10이상인 포켓몬들의 이름, 공격력, 방어력 가져오기

문제14. 능력치의 합이 150이상인 포켓몬의 이름과 능력치의 합 가져오기
이 때, 능력치의 합은 'total'이라는 별명으로 가져오기
단, 조건은 능력치의 합이 공격력, 방어력, 속도의 합을 의미함.

원하는 데이터 만들기
"10번 이상 구매한 특별고객, 구매금액 순으로 리스트를 뽑아주세요"
"매출 5천만원 이상의 상품, 판매량 순으로 리스트를 뽑아주세요"
데이터 줄세우고 순서를 정해서 원하는 데이터를 가져오기
가져온 데이터를 정렬해주는 키워드 ORDER BY의 특징
- ORDER BY [컬럼이름]형식으로 사용
- 입력한 [컬럼이름]의 값을 기준으로 모든 로우(행)를 정렬
- 기본정렬규칙은 오름차순으로 # ORDER BY [컬럼이름] = ORDER BY [컬럼이름] ASC
- 내림차순정렬을 원할 경우에는 마지막에 DESC키워드를 추가하며 # ORDER BY [컬럼이름] DESC
- 여러컬럼으로 정렬도 가능하며, 키워드 뒤에 [컬럼기름]을 복수갯수를 입력하면 위치한 순서대로 정렬된다.
예시) ORDER BY [컬럼1], [컬럼2]의 경우
# [컬럼1] 기준으로 정렬 -> [컬럼1]값이 동일한 로우(행) 간에 [컬럼2] 기준으로 정렬
- 컬럼번호로도 정렬이 가능하며 이 때, 컬럼번호는 SELECT절의 컬럼이름의 순서를 의미
쿼리문법
SELECT [컬럼이름] FROM [테이블이름] WHERE 조건식 ORDER BY [컬럼이름] ASC;
# 오름차순정렬 ASC쿼리는 생략해도 무방하다.
SELECT [컬럼이름] FROM [테이블이름] WHERE 조건식 ORDER BY [컬럼이름] DESC;
# 내림차순정렬 DESC쿼리는 반드시 기재하자.
ORDER BY 사용예제1
쿼리문은 SELECT number, name FROM mypokemon ORDER BY number DESC; # 테이블을 사용했다고 가정함.
ORDER BY 사용예제2
쿼리문은 SELECT number, name, attack, defense FROM mypokemon ORDER BY attack DESC, defense;
# 테이블을 사용했다고 가정함.
ORDER BY 사용예제3
쿼리문은 SELECT number, name, attack, defense FROM mypokemon ORDER BY 3 DESC, 4;
결과는 사용예제2의 결과와 동일
데이터순위만들기
"10번 이상 구매한 특별고객 중 7번째 고객을 뽑아주세요"
"매출 5천만원 이상의 상품 중 판매량 하위 10번째 상품을 뽑아주세요"
"10번 이상 구매한 특별고객, 구매금액 순으로 BEST 100 리스트를 뽑아주세요"
"매출 5천만원 이상의 상품, 판매량 순으로 WORST 30 리스트를 뽑아주세요"
데이터를 정렬해 순위를 만들어주는 함수 RANK의 특징
- RANK() OVER (ORDER BY [컬럼이름]) 형식으로 사용
- 항상 ORDER BY와 함께 사용
- SELECT절에 사용하며, 정렬된 순서에 순위를 붙인 새로운 컬럼을 보여주며 테이블의 실제데이터에는 영향을 미치지 않는다.
쿼리문법
SELECT [컬럼이름], ..., RANK() OVER (ORDER BY [컬럼이름]) FROM [테이블이름] WHERE 조건식;
# 오름차순 순위를 만들며 (ORDER BY [컬럼이름])옆에 DESC가 있으면 내림차순 순위를 만든다.
RANK사용예제
쿼리문은 SELECT name, attack, RANK() OVER (ORDER BY attack DESC) AS attack_rank
FROM pokemon.mypokemon;
데이터를 정렬해 순위를 만들어주는 함수는?
RANK, DENSE_RANK, ROW_NUMBER
DENSE_RANK사용예제
쿼리문은 SELECT name, attack, DENSE_RANK() OVER (ORDER BY attack DESC) AS attack_rank
FROM mypokemon;
ROW_NUMBER사용예제
쿼리문은 SELECT name, attack, ROW_NUMBER() OVER (ORDER BY attack DESC) AS attack_rank
FROM mypokemon;
데이터순위를 만드는 함수비교
쿼리문은 SELECT name, attack, RANK() OVER (ORDER BY attack DESC) AS rank_rank,
DENSE_RANK() OVER (ORDER BY attack DESC) AS rank_dense_rank,
ROW_NUMBER() OVER (ORDER BY attack DESC) AS rank_row_number
FROM mypokemon;
| RANK | 공동순위가 있으면 다음순서로 건너 뜀 |
| DENSE_RANK | 공동순위가 있어도 다음순위를 뛰어 넘지 않음 |
| ROW_NUMBER | 공동순위를 무시함 |
문자형데이터정복하기
MySQL내의 다양한 타입의 데이터는 '함수'로 변형해서 데이터를 조작할 수 있다.
함수
f(x)=y # x가 input, y가 output으로 f는 함수이름 (x)는 함수를 적용할 값 또는 컬럼이름
input x -> function f: -> output f(x)
문자열의 글자수를 반환하는 함수인 LENGTH("abc") = 3의 특징
함수이름(함수를 적용할 값 또는 컬럼이름)형식으로 사용
결과값을 새로운 컬럼으로 반환
자주사용하는 문자형데이터함수
| 함수 | 활용예시 | 설명 |
| LOCATE | LOCATE("A", "ABC") | "ABC"에서 "A"는 몇번째에 위치했는지 검색해서 위치반환 |
| SUBSTRING | SUBSTRING("ABC", 2) | "ABC"에서 2번째 문자부터 반환 |
| RIGHT | RIGHT("ABC", 1) | "ABC"에서 오른쪽으로 1번째문자까지 반환 |
| LEFT | LEFT("ABC", 1) | "ABC"에서 왼쪽으로 1번째문자까지 반환 |
| UPPER | UPPER("abc") | "abc"를 대문자로 바꿔 반환하면 "ABC" |
| LOWER | LOWER("ABC") | "ABC"를 소문자로 바꿔 반환하면 "abc" |
| LENGTH | LENGTH("ABC") | "ABC"의 글자수를 반환 |
| CONCAT | CONCAT("ABC", "DEF") | "ABC" 문자열과 "CDF"문자열을 합쳐 반환 |
| REPLACE | REPLACE("ABC", "A", "Z") | "ABC"의 "A"를 "Z"로 바꿔 반환 |
LOCATE함수
예시) LOCATE("A", "ABC") # "ABC"에서 "A"는 몇번째에 위치했는지 검색해서 위치반환
- 문자가 여러개라면 가장 먼저 찾은 문자의 위치를 가져온다.
- 만약 찾는 문자가 없다면 0을 가져온다.
쿼리는 SELECT part, LOCATE('i', lyric) FROM bts_music.butter;
결과는
| part | LOCATE('i', lyric) |
| 1 | 9 |
| 2 | 2 |
| 3 | 11 |
| 4 | 6 |
| 5 | 0 |
SUBSTRING함수
예시) SUBSTRING("ABC", 2) # "ABC"에서 2번째문자부터 반환
만약 입력한 숫자가 문자열의 길이보다 크다면 아무것도 가져오지 않습니다.
쿼리문은 SELECT part, SUBSTRING(lyric, 3) FROM bts_music.butter;
결과는
| part | SUBSTRING(lyric, 3) |
| 1 | ooth like butter |
| 2 | ke a criminal undercover |
| 3 | n' pop like trouble |
| 4 | eakin' into your heart like that |
| 5 | ol shade stunner |
쿼리문은 SELECT part, SUBSTRING(lyric, 100) FROM bts_music.butter;
결과는
| part | SUBSTRING(lyric, 3) |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
RIGHT, LEFT함수
예시1) RIGHT("ABC", 1) # "ABC"에서 오른쪽에서 1번째 문자까지 반환
예시2) LEFT("ABC", 1) # "ABC"에서 왼쪽에서 1번째 문자까지 반환
쿼리문은 SELECT part, RIGHT(lyric,3), LEFT(lyric, 3) FROM bts_music.butter;
| part | RIGHT(lyric, 3) | LEFT(lyric, 3) |
| 1 | ter | Smo |
| 2 | ver | Lik |
| 3 | ble | Gon |
| 4 | hat | Bre |
| 5 | ner | Coo |
UPPER, LOWER 함수
예시1) UPPER("abc") # "abc"를 대문자로 변환
예시2) LOWER("ABC") # "ABC"를 소문자로 변환
쿼리문은 SELECT part, UPPER(lyric) FROM bts_music.butter;
결과는
| part | UPPER(lyric) | LOWER(lyric) |
| 1 | SMOOTH LIKE BUTTER | smooth like butter |
| 2 | LIKE A CRIMINAL UNDERCOVER | like a criminal undercover |
| 3 | GON' POP LIKE TROUBLE | gon' pop like trouble |
| 4 | BREAKIN' INTO YOUR HEART LIKE THAT | breakin' into your heart like that |
| 5 | COOL SHADE STUNNER | cool shade stunner |
LENGTH함수
예시) LENGTH("ABC") # "ABC"의 글자수를 반환
쿼리문은 SELECT part, LENGTH(lyric) FROM bts_music.butter;
결과는
| part | LENGTH(lyric) |
| 1 | 18 |
| 2 | 26 |
| 3 | 21 |
| 4 | 34 |
| 5 | 18 |
CONCAT함수
예시) CONCAT("ABC", "DEF") # "ABC"문자열과 "CDF"문자열을 합쳐 반환
쿼리문은 SELECT part, CONCAT(LEFT(lyric, 1), RIGHT(lyric, 1)) AS first_last FROM bts_music.butter;
결과는
| part | first_last |
| 1 | Sr |
| 2 | Lr |
| 3 | Ge |
| 4 | Bt |
| 5 | Cr |
REPLACE함수
예시) REPLACE("ABC", "A", "Z") # "ABC"의 "A"를 "Z"로 변환
쿼리문은 SELECT part, REPLACE(lyric, ' ', '_') FROM bts_music.butter;
결과는
| part | LOWER(lyric) |
| 1 | smooth_like_butter |
| 2 | like_a_criminal_undercover |
| 3 | gon'_pop_like_trouble |
| 4 | breakin'_into_your_heart_like_that |
| 5 | cool_shade_stunner |
숫자형 데이터 정복하기
자주 사용하는 대표 숫자관련함수
| 함수 | 활용 | 설명 |
| ABS | ABS(숫자) | 숫자의 절댓값 반환 |
| CEILING | CEILING(숫자) | 숫자를 정수로 올림해서 반환 |
| FLOOR | FLOOR(숫자) | 숫자를 정수로 내림해서 반환 |
| ROUND | ROUND(숫자, 자릿수) | 숫자를 소숫점자릿수까지 반올림해서 반환 |
| TRUNCATE | TRUNCATE(숫자, 자릿수) | 숫자를 소숫점자릿수까지 버림해서 반환 |
| POWER | POWER(숫자A, 숫자B) | 숫자A와 숫자B의 제곱반환 |
| MOD | MOD(숫자A, 숫자B) | 숫자A와 숫자B로 나눈 나머지반환 |
ABS함수
예시) ABS(숫자) # 숫자의 절댓값 반환
쿼리문은 SELECT name, friendship, ABS(friendship) FROM pokemon.mypokemon;
결과는
| name | friendship | ABS(friendship) |
| caterpie | -1.455 | 1.455000429153442 |
| pikachu | 124.78 | 124.77999877929688 |
| raichu | 30.289 | 30.288999557495117 |
| electabuzz | -10.67 | 10.670000076293945 |
| eevee | 15.988 | 15.98799991607666 |
| porygon | -0.245 | 0.24500000476837158 |
| chikoirita | 67.164 | 67.16400146484375 |
| bayleef | 9.756 | 9.755999565124512 |
| pichu | 872.1 | 872.0999755859375 |
| leafeon | 3.42 | 3.4200000762939453 |
CEILING, FLOOR함수
예시1) CEILING(숫자) # 숫자를 정수로 올림해서 반환
예시2) FLOOR(숫자) # 숫자를 정수로 내림해서 반환
쿼리문은 SELECT name, friendship, CEILING(friendship), FLOOR(friendship) FROM pokemon.mypokemon;
결과는
| name | friendship | CEILING(friendship) | FLOOR(friendship) |
| caterpie | -1.455 | -1 | -2 |
| pikachu | 124.78 | 125 | 124 |
| raichu | 30.289 | 31 | 30 |
| electabuzz | -10.67 | -10 | -11 |
| eevee | 15.988 | 16 | 15 |
| porygon | -0.245 | -0 | -1 |
| chikoirita | 67.164 | 68 | 67 |
| bayleef | 9.756 | 10 | 9 |
| pichu | 872.1 | 873 | 872 |
| leafeon | 3.42 | 4 | 3 |
ROUND, TRUNCATE함수
예시1) ROUND(숫자, 자릿수) # 숫자를 소수점자릿수까지 반올림해서 반환
예시2) TRUNCATE(숫자, 자릿수) # 숫자를 소수점자릿수까지 버림해서 반환
쿼리문은 SELECT name, friendship, ROUND(friendship, 0), TRUNCATE(friendship, 0) FROM pokemon.mypokemon;
결과는
| name | friendship | ROUND(friendship,0) | TRUNCATE(friendship, 0) |
| caterpie | -1.455 | -1 | -1 |
| pikachu | 124.78 | 125 | 124 |
| raichu | 30.289 | 30 | 30 |
| electabuzz | -10.67 | -11 | -10 |
| eevee | 15.988 | 16 | 15 |
| porygon | -0.245 | -0 | -0 |
| chikoirita | 67.164 | 67 | 67 |
| bayleef | 9.756 | 10 | 9 |
| pichu | 872.1 | 872 | 872 |
| leafeon | 3.42 | 3 | 3 |
POWER함수
예시) POWER(숫자A, 숫자B) # 숫자A의 숫자B 제곱반환
쿼리문 SELECT name, friendship, POWER(number, 2) FROM pokemon.mypokemon;
결과는
| name | number | POWER(number, 2) |
| caterpie | 10 | 100 |
| pikachu | 25 | 625 |
| raichu | 26 | 676 |
| electabuzz | 125 | 15625 |
| eevee | 133 | 17689 |
| porygon | 137 | 18769 |
| chikoirita | 152 | 23104 |
| bayleef | 153 | 23409 |
| pichu | 172 | 29584 |
| leafeon | 470 | 220900 |
MOD함수
예시) MOD(숫자A, 숫자B) # 숫자A를 숫자B로 나눈 나머지변환
쿼리문 SELECT name, friendship, POWER(number, 2) FROM pokemon.mypokemon;
결과는
| name | number | MOD(number, 2) |
| caterpie | 10 | 0 |
| pikachu | 25 | 1 |
| raichu | 26 | 0 |
| electabuzz | 125 | 1 |
| eevee | 133 | 1 |
| porygon | 137 | 1 |
| chikoirita | 152 | 0 |
| bayleef | 153 | 1 |
| pichu | 172 | 0 |
| leafeon | 470 | 0 |
날짜형 데이터 정복하기
날짜형 데이터 함수
| 함수 | 활용 | 설명 |
| NOW | NOW() | 현재날짜와 시간반환 |
| CURRENT_DATE | CURRENT_DATE() | 현재날짜반환 |
| CURRENT_TIME | CURRENT_TIME() | 현재시간반환 |
| YEAR | YEAR(날짜) | 날짜의 연도반환 |
| MONTH | MONTH(날짜) | 날짜의 월 반환 |
| MONTHNAME | MONTHNAME(날짜) | 날짜의 월을 영어로 반환 |
| DAYNAME | DAYNAME(날짜) | 날짜의 요일을 영어로 반환 |
| DAYOFMONTH | DAYOFMONTH(날짜) | 날짜의 일을 반환 |
| DAYOFWEEK | DAYOFWEEK(날짜) | 날짜의 요일을 숫자로 반환 |
| WEEK | WEEK(날짜) | 날짜가 해당연도에 몇번째 주인지 반환 |
| HOUR | HOUR(시간) | 시간의 시 반환 |
| MINUTE | MINUTE(시간) | 시간의 분 반환 |
| SECOND | SECOND(시간) | 시간의 초 반환 |
| DATE_FORMAT | DATEFORMAT(날짜/시간, 형식) | 날짜/시간의 형식을 형식으로 바꿔 반환 |
| DATEDIFF | DATEDIFF(날짜1, 날짜2) | 날짜1과 날짜2의 차이반환(날짜1-날짜2) |
| TIMEDIFF | TIMEDIFF(시간1, 시간2) | 시간1과 시간2의 차이반환(시간1-시간2) |
NOW, CURRENT_DATE, CURRENT_TIME함수
예시)
| NOW | NOW() | 현재날짜와 시간반환 |
| CURRENT_DATE | CURRENT_DATE() | 현재날짜반환 |
| CURRENT_TIME | CURRENT_TIME() | 현재시간반환 |
쿼리문은 SELECT NOW(), CURRENT_DATE(), CURRENT_TIME();
결과는
| NOW() | CURRENT_DATE() | CURRENT_TIME() |
| 2021-12-12 00:44:44 | 2021-12-12 | 00:44:44 |
YEAR, MONTH, MONTHNAME함수
예시)
| YEAR | YEAR() | 날짜의 연도반환 |
| MONTH | MONTH() | 날짜의 월 반환 |
| MONTHNAME | MONTHNAME() | 날짜의 월을 영어로 반환 |
쿼리문은 NOW(), YEAR(NOW()), MONTH(NOW()), MONTHNAME(NOW());
결과는
| NOW() | YEAR(NOW()) | MONTH(NOW()) | MONTHNAME(NOW()) |
| 2021-12-12 00:57:15 | 2021 | 12 | December |
DAYNAME, DAYOFMONTH, DAYOFWEEK, WEEK함수
| DAYNAME | DAYNAME() | 날짜의 요일을 영어로 반환 |
| DAYOFMONTH | DAYOFMONTH() | 날짜의 일을 반환 |
| DAYOFWEEK | DAYOFWEEK() | 날짜의 요일을 숫자로 반환 |
| WEEK | WEEK() | 날짜가 해당연도에 몇번째 주인지 반환 |
쿼리문은 SELECT NOW(), DAYNAME(NOW()), DAYOFMONTH(NOW()), DAYOFWEEK(NOW()), WEEK(NOW());
결과는
| NOW() | DAYNAME(NOW()) | DAYOFMONTH(NOW()) | DAYOFWEEK(NOW()) | WEEK(NOW()) |
| 2021-12-12 01:00:47 | Sunday | 12 | 1 | 50 |
HOUR, MINUTE, SECOND함수
| HOUR | HOUR() | 시간의 시 반환 |
| MINUTE | MINUTE() | 시간의 분 반환 |
| SECOND | SECOND() | 시간의 초 반환 |
쿼리문은 SELECT, NOW(), HOUR(NOW()), MINUTE(NOW()), SECOND(NOW());
결과는
| NOW() | YEAR(NOW()) | MONTH(NOW()) | MONTHNAME(NOW()) |
| 2021-12-12 01:01:55 | 1 | 1 | 55 |
DATE_FORMAT함수
| DATE_FORMAT | DATEFORMAT(날짜/시간, 형식) | 날짜/시간의 형식을 형식으로 바꿔 반환 |
쿼리문은 SELECT DATE_FORMAT('1990-11-27 12:34:56', '%Y년 %m월 %d일 %H시 %i분 %s초') AS formatted_date;
결과는
| formatted_date |
| 1990년 11월 27일 12시 34분 56초 |
DATEDIFF, TIMEDIFF함수
| DATEDIFF | DATEDIFF(날짜1, 날짜2) | 날짜1과 날짜2의 차이반환(날짜1-날짜2) |
| TIMEDIFF | TIMEDIFF(시간1, 시간2) | 시간1과 시간2의 차이반환(시간1-시간2) |
쿼리문은 SELECT DATEDIFF('2022-01-01 00:00:00', '2021-12-25 12:00:00') AS DATE_DIFF,
DATEDIFF('2022-01-01 00:00:00', '2021-12-25 12:00:00') AS TIME_DIFF;
결과
| DATE_DIFF | TIME_DIFF |
| 7 | 156:00:00 |
데이터를 요청대로 만들어보는 실습
문제1. 포켓몬테이블에서 포켓몬의 이름과 이름의 글자수를 이름의 글자수로 정렬해서 가져오기(정렬순서는 글자수가 적은 것부터 많은 것 순으로 해주세요.)

문제2. 포켓몬테이블에서 방어력순위를 보여주는 컬럼을 새로 만들어서 'defense_rank'라는 별명으로 가져오자. 이 때, 포켓몬이름데이터도 함께 가져오기
조건1: 방어력순위란 방어력이 큰 순서대로 나열한 순위를 의미
조건2: 공동순위가 있으면 다음순서로 건너뛰기

문제3. 포켓몬테이블에서 포켓몬을 포획한지 기준날짜까지 며칠이 지났는지 'days'라는 별명으로 가져오고 이 때, 포켓몬의 이름도 함께 가져오기
조건은 기준날짜로 2022년 2월 14일이다.

다양한 함수를 사용해보는 실습
문제1. 포켓몬의 이름을 마지막 3개문자만, 'last_char'이라는 별명으로 가져오기

문제2. 포켓몬이름 왼쪽에서 2개문자를 'left2'라는 별명으로 가져오기

문제3. 포켓몬이름에서 이름에 o가 포함된 포켓몬만 모든 소문자 o를 대문자 O로 바꿔서 'bigO'라는 별명으로 가져오기
예시) 이름이 'pokemon'일 경우, 'bigO' 값은 'pOkemOn'이 됨

문제4. 포켓몬타입을 가장 첫글자 1자, 가장 마지막글자 1자를 합치고, 대문자로 변환해서 'type_code'라는 별명으로 가져오기
예시) 타입이 'water'일 경우, 'type_code'값은 'w'와 'r'을 대문자로 바꾼 'WR'이 됨

문제5. 포켓몬이름의 글자수가 8보다 큰 포켓몬의 데이터를 전부 가져오기

문제6. 모든 포켓몬의 공격력평균을 정수로 반올림해서 'avg_of_attack'이라는 별명으로 가져오기

문제7. 모든 포켓몬의 방어력평균을 정수로 내림해서 'avg_of_defense'이라는 별명으로 가져오기

문제8. 이름의 길이가 8미만인 포켓몬의 공격력의 2제곱을 'attack2'라는 별명으로 가져오는데 이름도 함께 가져오기

문제9. 모든 포켓몬의 공격력을 2로 나눈 나머지를 'div2'라는 별명으로 가져오는데 이 때, 이름도 함께 가져오기

문제10. 공격력이 50이하인 포켓몬의 공격력을 방어력으로 뺀 값의 절댓값을 'diff'라는별명으로 가져오는데 이 때 이름도 함께 가져오기

문제11. 현재날짜와 시간을 가져오고 각각 now_date, now_time이라는 별명으로 가져오기

문제12. 포켓몬을 포획한 달(월, MONTH)을 숫자와 영어로 가져오는데 숫자는 month_num, 영어는 month_eng이라는 별명으로 가져오기

문제13. 포켓몬을 포획한 날의 요일을 숫자와 영어로 가져오는데 숫자는 day_num, 영어는 day_eng이라는 별명으로 가져오기
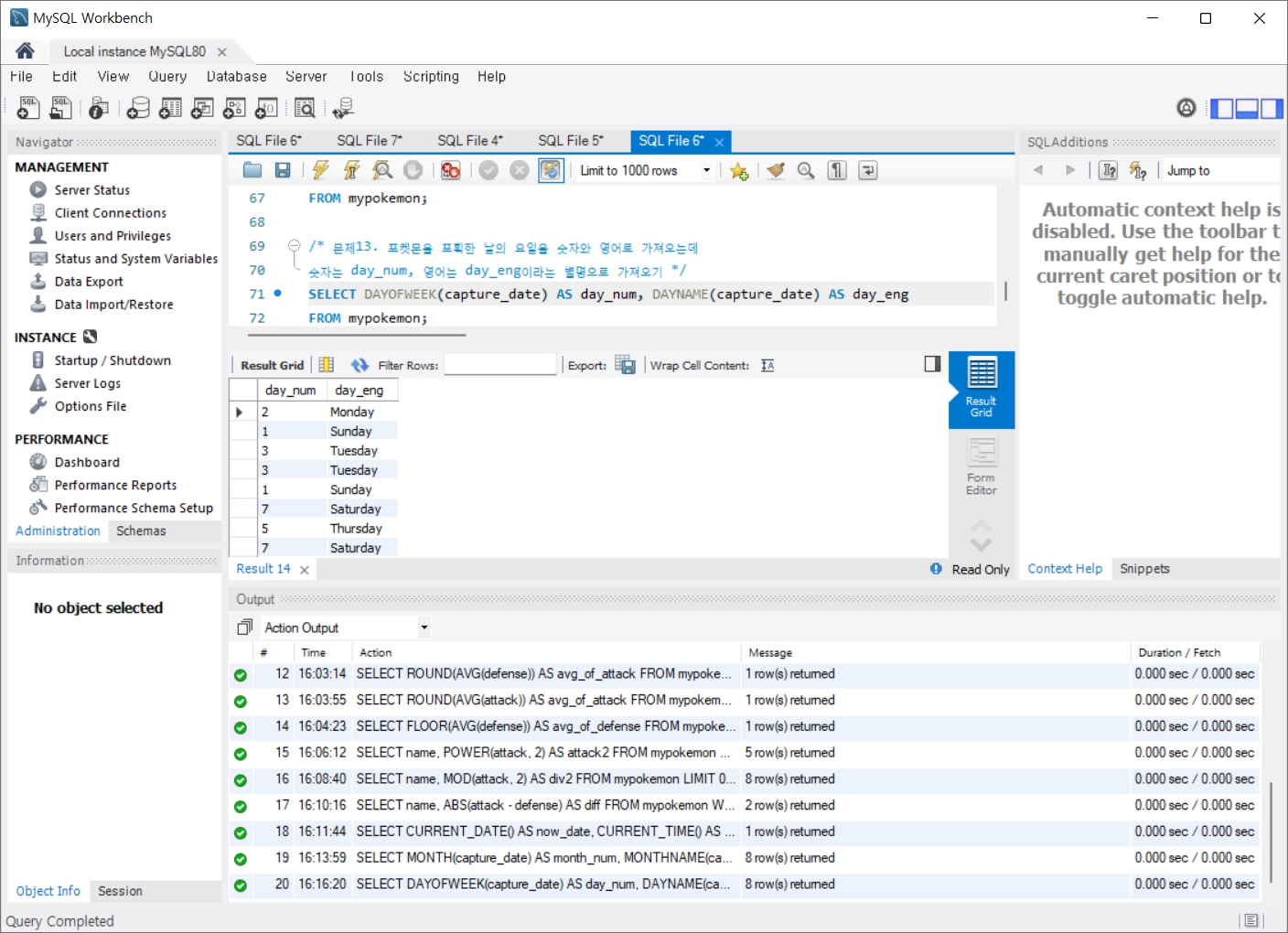
문제14. 포켓몬을 포획한 날의 연도, 월, 일을 각각 숫자로 가져오는데 연도는 year, 월은 month, 일은 day라는 별명으로 가져오기

데이터그룹화하기
데이터를 통계로 낼 때
"고객등급별 매출통계를 뽑아주세요"
"상품카테고리별 실적통계를 뽑아주세요"
그룹화해서 원하는 그룹만 통계를 낸다고 한다.
컬럼에서 동일한 값을 가지는 로우(행)을 그룹화하는 키워드인 GROUP BY의 특징
- GROUP BY [컬럼이름] 형식으로 사용
- 주로 그룹별 데이터를 집계할 때 사용하며, 엑셀의 피벗기능과 유사
- GROUP BY가 쓰인 쿼리의 SELECT절에는 GROUP BY대상 컬럼과 그룹함수만 사용가능하지만, GROUP BY대상 컬럼이 아닌 컬럼을 SELECT하면 에러가 발생
- 여러컬럼으로 그룹화도 가능하며, 키워드 뒤에 [컬럼이름]을 복수개 입력
- 컬럼번호로도 그룹화가 가능하며 컬럼번호는 SELECT절의 컬럼이름의 순서를 의미
쿼리문법
SELECT [GROUP BY 대상컬럼이름], ..., [그룹함수] FROM [테이블이름] WHERE 조건식 GROUP BY [컬럼이름];
GROUP BY사용예제
쿼리문은 SELECT type FROM pokemon.mypokemon GROUP BY type;
결과는
| type |
| bug |
| electric |
| normal |
| grass |
그룹에 조건주기
가져올 데이터그룹에 조건을 지정해주는 키워드 HAVING의 특징
- HAVING 조건식 형식으로 사용
- 조건식이 True(참)이 되는 그룹만 선택
- HAVING절의 조건식에서는 그룹함수를 활용
쿼리문법
SELECT [컬럼이름], ..., [그룹함수] FROM [테이블이름] WHERE 조건식 GROUP BY [컬럼이름] HAVING 조건식;
다양한 그룹함수 알아보기
그룹의 값 수를 세는 함수 COUNT의 특징
- COUNT([컬럼이름]) 형식으로 SELECT, HAVING절에서 사용
- 집계할 컬럼이름은 그룹의 기준이 되는 컬럼이름과 같아도, 같지 않아도 상관없다.
- COUNT(1)은 하나의 값을 1로 세어주는 표현으로 COUNT함수에 자주 사용될 것임.
- GROUP BY가 없는 쿼리에서도 사용가능한데 전체 로우(행)에 함수가 적용
쿼리문법은 SELECT [컬럼이름], ..., COUNT([컬럼이름]) FROM [테이블이름] GROUP BY [컬럼이름} HAVING 조건문;
그룹의 합을 계산하는 SUM의 특징
- SUM([컬럼이름]) 형식으로 SELECT, HAVING절에서 사용
- 집계할 컬럼이름은 그룹의 기준이 되는 컬럼이름과 같아도, 같이 않아도 상관없다.
- GROUP BY가 없는 쿼리에서도 사용가능한데 전체 로우(행)에 함수가 적용
쿼리문법은 SELECT [컬럼이름], ..., SUM([컬럼이름]) FROM [테이블이름] GROUP BY [컬럼이름} HAVING 조건문;
그룹의 평균을 계산하는 함수 AVG의 특징
- AVG([컬럼이름]) 형식으로 SELECT, HAVING절에서 사용
- 집계할 컬럼이름은 그룹의 기준이 되는 컬럼이름과 같아도, 같지 않아도 상관없다.
- GROUP BY가 없는 쿼리에서도 사용가능한데 전체 로우(행)에 함수가 적용
쿼리문법은 SELECT [컬럼이름], ..., AVG([컬럼이름]) FROM [테이블이름] GROUP BY [컬럼이름} HAVING 조건문;
그룹의 평균을 계산하는 함수 MIN의 특징
- MIN([컬럼이름]) 형식으로 SELECT, HAVING절에서 사용
- 집계할 컬럼이름은 그룹의 기준이 되는 컬럼이름과 같아도, 같지 않아도 상관없다.
- GROUP BY가 없는 쿼리에서도 사용가능한데 전체 로우(행)에 함수가 적용
쿼리문법은 SELECT [컬럼이름], ..., MIN([컬럼이름]) FROM [테이블이름] GROUP BY [컬럼이름} HAVING 조건문;
그룹의 평균을 계산하는 함수 MAX의 특징
- MAX([컬럼이름]) 형식으로 SELECT, HAVING절에서 사용
- 집계할 컬럼이름은 그룹의 기준이 되는 컬럼이름과 같아도, 같지 않아도 상관없다.
- GROUP BY가 없는 쿼리에서도 사용가능한데 전체 로우(행)에 함수가 적용
쿼리문법은 SELECT [컬럼이름], ..., MAX([컬럼이름]) FROM [테이블이름] GROUP BY [컬럼이름} HAVING 조건문;
그룹함수사용예제 SELECT절
쿼리문은 SELECT type, COUNT(*), COUNT(1), AVG(height), MAX(weight)
FROM pokemon.mypokemon GROUP BY type;
결과는
| type | COUNT(*) | COUNT(1) | AVG(height) | MAX(weight) |
| bug | 1 | 1 | 0.30000001192092896 | 2.9 |
| electric | 4 | 4 | 0.6500000134110451 | 3 |
| normal | 2 | 2 | 0.550000011920929 | 36.5 |
| grass | 3 | 3 | 1.0333333412806194 | 25.5 |
그룹함수사용예제 HAVING절
쿼리문은 SELECT type, COUNT(*), COUNT(1), AVG(height), MAX(weight)
FROM pokemon.mypokemon GROUP BY type HAVING COUNT(1)=2;
결과는
| type | COUNT(*) | COUNT(1) | AVG(height) | MAX(weight) |
| normal | 2 | 2 | 0.550000011920929 | 36.5 |
쿼리실행순서
6가지 핵심쿼리키워드
SELECT[컬럼이름] 첫번째로 작성하며 5번째로 실행
FROM[테이블이름] 두번째로 작성하며 1번째로 실행
WHERE[테이블이름] 세번째로 작성하며 2번째로 실행
GROUP BY[컬럼이름] 네번째로 작성하며 3번째로 실행
HAVING[컬럼이름] 다섯번째로 작성하며 4번째로 실행
ORDER BY[컬럼이름] 여섯번째로 작성하며 6번째로 실행
쿼리문
- SELECT type, COUNT(1), MAX(weight) # 5번째 실행
- FROM pokemon.mypokemon # 1번째 실행
- WHERE name LIKE '%a%' # 2번째 실행
- GROUP BY type # 3번째 실행
- HAVING MAX(height) > 1 # 4번째 실행
- ORDER BY 3; # 6번째 실행
데이터를 그룹화해서 통계를 내는 첫번째 실습
문제1. 포켓몬테이블에서 이름(name)의 길이가 5보다 큰 포켓몬들을 타임(type)을 기준으로 그룹화하고, 몸무게(weight)의 평균이 20이상인 그룹의 타입과 몸무게의 평균을 가져오는데 결과는 몸무게의 평균을 내림차순으로 정렬하기

문제2. 포켓몬테이블에서 번호(number)가 200보다 작은 포켓몬들을 타입(type)을 기준으로 그룹화한 후에, 몸무게(weight)의 최대밧이 10보다 크거나 같고 최소값은 2보다 크거나 같은 그룹의 타입, 키(height)의 최소값, 최대값을 가져오는데 결과는 키의 최소값의 내림차순을 정렬해주시고, 만약 키의 최소값이 같다면 키의 최대값의 내림차순으로 정렬

데이터를 그룹화해서 통계를 내는 두번째 실습
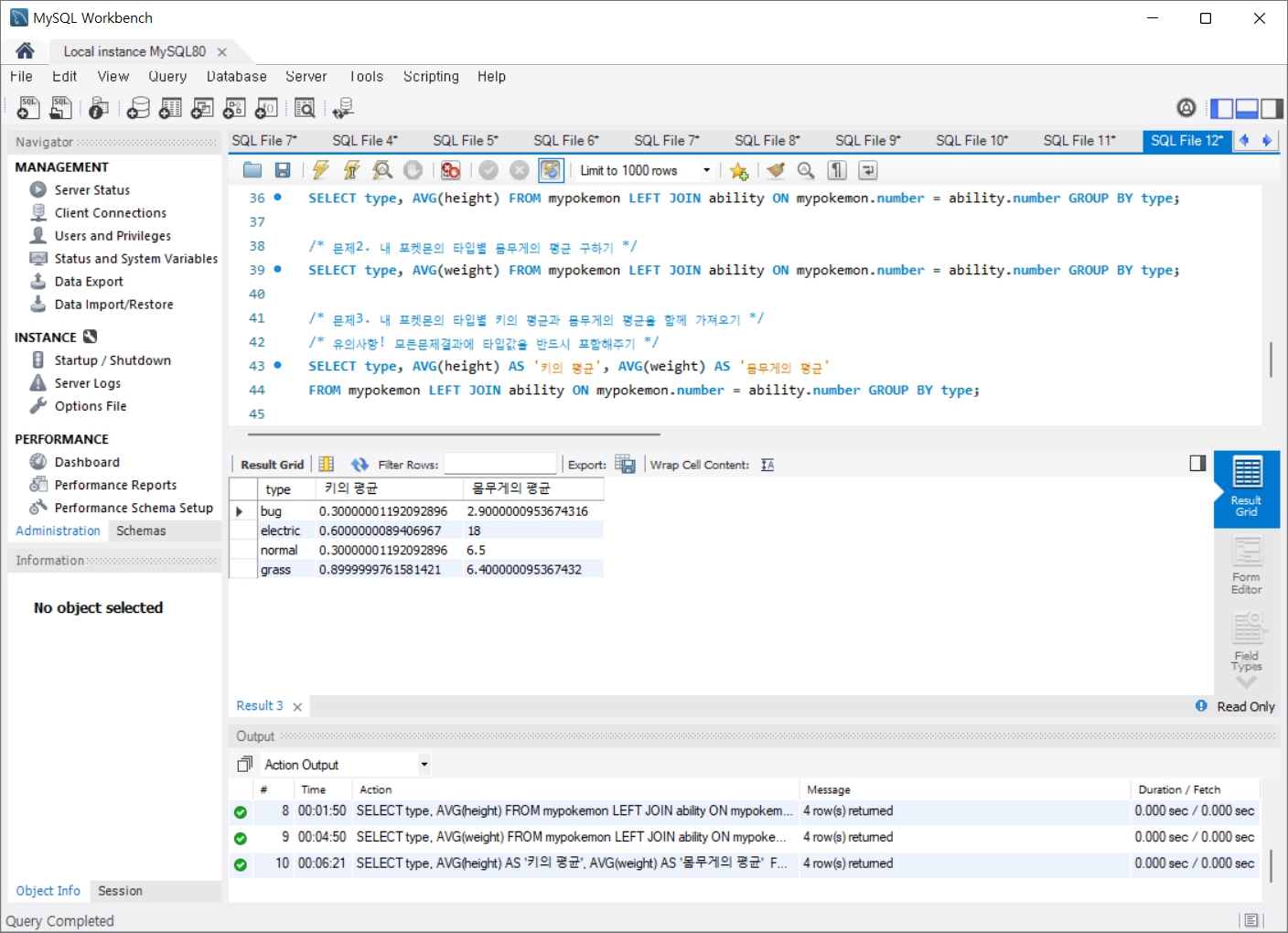
문제1. 포켓몬의 타입별 키의 평균

문제2. 포켓몬의 타입별 몸무게의 평균

문제3. 포켓몬의 타입별 키의 평균과 몸무게의 평균을 함께 가져오기

문제4. 키의 평균의 0.5이상인 포켓몬의 타입을 가져오기

문제5. 몸무게의 평균이 20이상인 포켓몬의 타입을 가져오기

문제6. 포켓몬의 타입별 번호(number)의 합을 가져오기

문제7. 키가 0.5이상인 포켓몬이 포켓몬의 type별로 몇개씩 있는지 가져오기

문제8. 포켓몬타입별 키의 최소값

문제9. 포켓몬타입별 몸무게의 최대값

문제10. 키의 최소값 0.5보다 크고 몸무게의 최대값이 30보다 작은 포켓몬타입을 가져오기

규칙만들기
조건만들기
"구매금액 10억이상 고객은 초특급으로 1억이상이면 특급으로 고객등급을 뽑아주세요"
"상품매출이 1억이상이면 O, 미만이면 X로 데이터를 뽑아주세요"
조건을 만들 때 사용하는 함수 IF의 특징
- IF(조건식, 참일 때 값, 거짓일 때 값)형식으로 사용
- 주로 SELECT절에 사용하는 함수로, 결과값을 새로운 컬럼으로 반환
IF사용예제
쿼리문은 SELECT name, IF(attack >= 60, 'strong', 'weak') AS attack_class FROM pokemon.mypokemon;
결과는
| name | attack_class |
| caterpie | weak |
| pikachu | weak |
| raichu | strong |
| electabuzz | strong |
| eevee | weak |
| porygon | strong |
| chikoirita | weak |
| bayleef | strong |
| pichu | weak |
| leafeon | strong |
데이터가 NULL인지 아닌지를 확인해서 NULL이라면 새로운 값을 반환하는 함수 IFNULL의 특징
- IFNULL([컬럼이름], NULL일 때 값) 형식으로 사용
- 해당컬럼의 값이 NULL인 로우(행)에서 NULL일 때 값을 반환
- 주로 SELECT절에 사용하는 함수로 결과값을 새 컬럼으로 반환
IFNULL사용예제
쿼리문은 SELECT name, IFNULL(name, 'unknown') AS full_name FROM pokemon.mypokemon;
결과는
| name | full_name |
| caterpie | caterpie |
| pikachu | pikachu |
| raichu | raichu |
| electabuzz | electabuzz |
| eevee | eevee |
| porygon | porygon |
| chikoirita | chikoirita |
| bayleef | bayleef |
| null | unknown |
| null | unknown |
여러조건 한번에 만들기
조건을 여러개 만들 때 사용하는 문법 CASE의 특징
| 형식1 | 형식2 |
| CASE WHEN 조건식1 THEN 결과값1 WHEN 조건식2 THEN 결과값2 ELSE 결과값3 END |
CASE [컬럼이름] WHEN 조건식1 THEN 결과값1 WHEN 조건식2 THEN 결과값2 ELSE 결과값3 END |
- 주로 SELECT절에 사용하는 함수로 결과값을 새 컬럼으로 반환
- ELSE문장을 생략할 시 NULL값을 반환
CASE사용예제1
쿼리문은
SELECT name,
CASE
WHEN attack >= 100 THEN 'very strong'
WHEN attack >= 60 THEN 'strong'
ELSE 'weak'
END AS attack_class
FROM pokemon.mypokemon;
결과는
| name | attack_class |
| caterpie | weak |
| pikachu | weak |
| raichu | strong |
| electabuzz | strong |
| eevee | weak |
| porygon | strong |
| chikoirita | weak |
| bayleef | strong |
| pichu | weak |
| leafeon | very strong |
CASE사용예제2
쿼리문은
SELECT name, type
CASE type
WHEN 'bug' THEN 'grass'
WHEN 'electric' THEN 'water'
WHEN 'grass' THEN 'bug'
END AS rival_type
FROM pokemon.mypokemon;
결과는
| name | type | rival_type |
| caterpie | bug | grass |
| pikachu | electric | water |
| raichu | electric | water |
| electabuzz | electric | water |
| eevee | normal | NULL |
| porygon | normal | NULL |
| chikoirita | grass | bug |
| bayleef | grass | bug |
| pichu | electric | water |
| leafeon | grass | bug |
함수만들기
쿼리문법
CREATE FUNCTION [함수이름] ([입력값이름] [데이터타입], ...)
RETURNS [결과값 데이터타입]
BEGIN
DECLARE [임시값이름] [데이터타입];
SET[임시값이름] = [입력값이름];
쿼리;
RETURN 결과값
END
함수지우기
DROP FUNCTION [함수이름]
함수만들기 예시
공격력과 방어력의 합을 가져오는 함수
CREATE FUNCTION getAbility(attack INT, defense INT)
RETURNS INT
BEGIN
DECLARE a INT;
DECLARE b INT;
DECLARE ability INT;
SET a = attack;
SET b = defense;
SELECT a + b INTO ability;
RETURN ability;
END
MySQL Workbench에서 함수생성할 때 주의할 점
SET GLOBA log_bin_trust_function_creators = 1;
DELIMITER // # 함수의 시작 지정
| CREATE FUNCTION [함수이름] ([입력값이름] [데이터타입], ...) RETURNS [결과값 데이터타입] BEGIN DECLARE [임시값이름] [데이터타입]; SET[임시값이름] = [입력값이름]; 쿼리; RETURN 결과값 END |
//
DELIMITER; # 함수의 끝 지정
함수를 만들고 사용하는 실습 (CREATE FUNCTION)
문제. 공격력과 방어력의 합이 120보다 크면 'very strong', 90보다 크면 'strong', 모두 해당되지 않으면 'not strong'을 반환하는 함수 'isStrong'을 만들고 사용하기
조건. attack과 defense를 입력값으로 사용하고 결과값 데이터타입은 VARCHAR(20)



조건문을 만들어보는 실습 (IF, CASE)
문제1. 포켓몬의 번호가 150보다 작으면 값을 'old'로 반환하고, 번호가 150보다 크거나 같으면 값을 'new'로 반환해서 'age'라는 별명으로 가져오기

문제2. 포켓몬의 공격력과 방어력의 합이 100보다 작으면 값을 'weak'로 반환하고, 100보다 크거나 같으면 값을 'strong'로 반환해서 'ability'라는 별명으로 가져오기

문제3. 포켓몬의 타입별 공격력의 평균이 60이상이면 값을 True(1)로 반환하고, 60보다 작으면 False(0)를 반환해 'is_strong_type'라는 별명으로 가져오기

문제4. 포켓몬의 공격력이 100보다 크고, 방어력도 100보다 크면 값을 True(1)로 반환하고, 둘 중 하나라도 100보다 작으면 False(0)를 반환해 'ace'라는 별명으로 가져오기

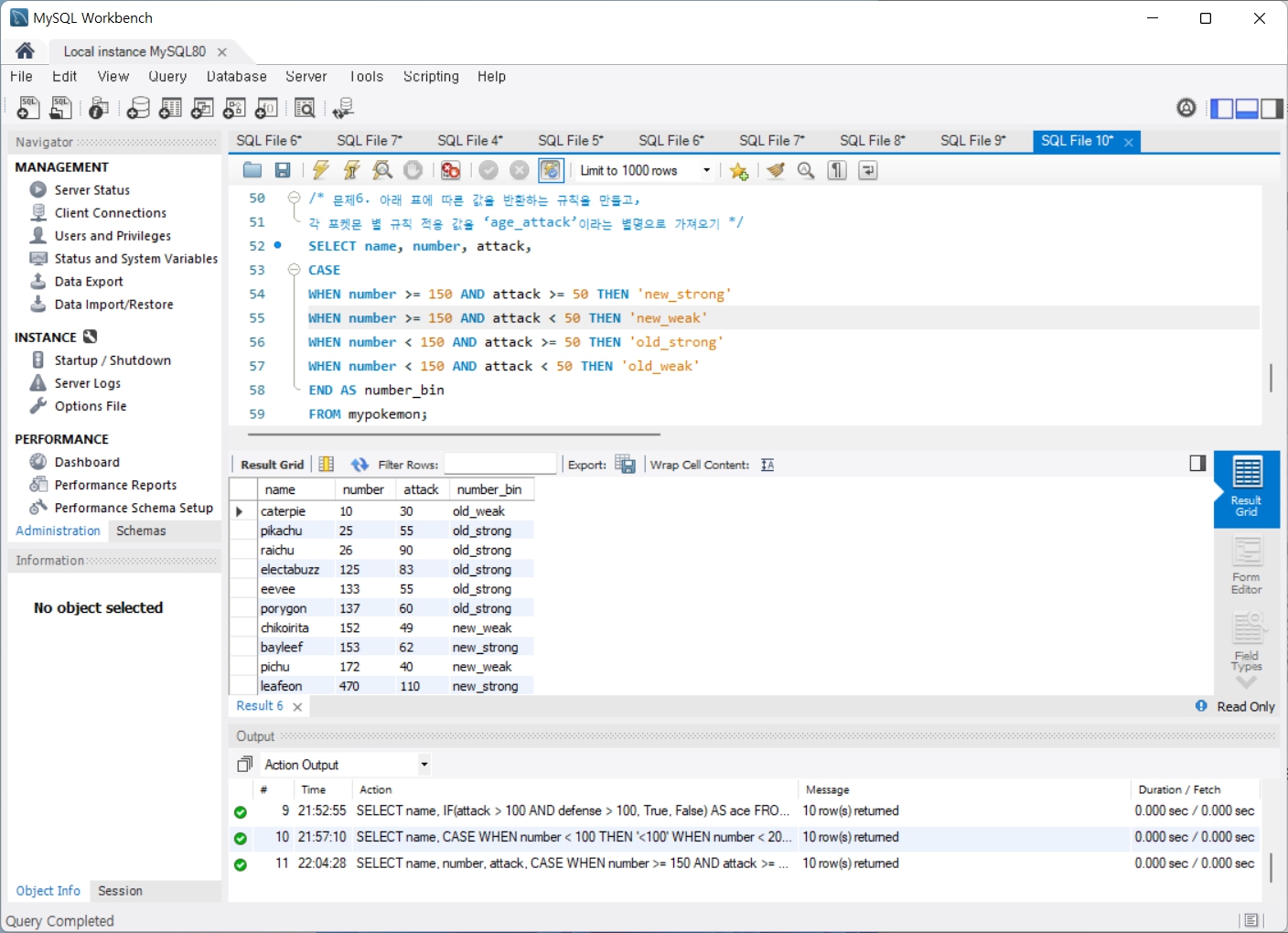
문제5. 포켓몬의 번호가 100보다 작으면 값을 ‘<100’을 반환하고, 200보다 작으면 값을 ‘<200’을 반환하고, 500보다 작으면 값을 ‘<500’을 반환하는 규칙을 만들고, 각 포켓몬 별 규칙 적용 값을 ‘number_bin’이라는 별명으로 가져오기

문제6. 아래 표에 따른 값을 반환하는 규칙을 만들고, 각 포켓몬 별 규칙 적용 값을 ‘age_attack’이라는 별명으로 가져오기
문제7. 타입 별 포켓몬 수가 1개면 ‘solo’, 3개 미만이면 ‘minor’, 3개 이상이면 ‘major’를 반환하고, ‘count_by_type’이라는 별명으로 가져오기

테이블 합치기
내 포켓몬의 키와 몸무게를 가져와달라는 요청을 할 때
원하는 데이터가 항상 같은 테이블에 있지 않을 수 있다.
그러므로 서로 다른 테이블을 합쳐서 봐야 한다.
같은 의미를 가지는 컬럼의 값을 기준으로 테이블을 합칠 때 사용하는 키워드 JOIN의 특징이다.
기준으로 테이블 합치기
두 테이블 모두에 있는 값만 합치는 INNER JOIN
쿼리문법은 SELECT [컬럼 이름] FROM [테이블 A 이름]
INNER JOIN [테이블 B 이름] ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름] WHERE 조건식;
실제로 사용한 쿼리는
SELECT * FROM mypokemon INNER JOIN ability
ON mypokemon.number = ability.number
| number | name | type | number | height | weight | attack | defense | speed |
| 10 | caterpie | bug | 10 | 0.3 | 2.9 | 30 | 35 | 45 |
| 25 | pikachu | electric | 25 | 0.4 | 6 | 55 | 40 | 90 |
| 133 | eevee | normal | 133 | 0.3 | 6.5 | 55 | 50 | 55 |
| 152 | chikoirita | grass | 152 | 0.9 | 6.4 | 49 | 65 | 45 |
한 쪽을 기준으로 테이블 합치기
왼쪽 테이블에 있는 값만 합치는 LEFT JOIN
쿼리문법은 SELECT [컬럼 이름] FROM [테이블 A 이름]
LEFT JOIN [테이블 B 이름] ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름] WHERE 조건식;
실제로 사용한 쿼리
SELECT * FROM mypokemon LEFT JOIN ability
ON mypokemon.number = ability.number
오른쪽 테이블에 있는 값만 합치는 RIGHT JOIN
쿼리문법은 SELECT [컬럼 이름] FROM [테이블 A 이름]
RIGHT JOIN [테이블 B 이름] ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름] WHERE 조건식;
실제로 사용한 쿼리
SELECT * FROM mypokemon RIGHT JOIN ability
ON mypokemon.number = ability.number
다양한 방식으로 테이블 합치기
두 테이블에 있는 모든 값을 합치는 OUTER JOIN이지만 MySQL의 키워드에는 없다.
그러므로 LEFT JOIN과 RIGHT JOIN을 병합하는 UNION이라는 집합 연산자를 활용한다.
UNION의 쿼리문법
SELECT [컬럼 이름] FROM [테이블 A 이름] LEFT JOIN [테이블 B 이름]
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름]
UNION # UNION: 두 쿼리의 결과를 중복을 제외하고 합쳐서 보여주는 집합 연산자
SELECT [컬럼 이름] FROM [테이블 A 이름]
RIGHT JOIN [테이블 B 이름]
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름]
실제로 사용한 쿼리
SELECT * FROM mypokemon LEFT JOIN ability
ON mypokemon.number = ability.number
UNION
SELECT * FROM mypokemon RIGHT JOIN ability
ON mypokemon.number = ability.number;
두 테이블에 있는 모든 값을 각각 합치는 CROSS JOIN의 쿼리문법은?
SELECT [컬럼 이름] FROM [테이블 A 이름] CROSS JOIN [테이블 B 이름] WHERE 조건식;
실제로 사용한 쿼리는 SELECT * FROM mypokemon CROSS JOIN ability;
같은 테이블에 있는 값 합치는 SELF JOIN의 쿼리문법은?
SELECT [컬럼 이름] FROM [테이블 A 이름] AS t1
INNER JOIN [테이블 A 이름 ] AS t2 ON t1.[컬럼 A 이름] = t2.[컬럼 A 이름] WHERE 조건식;
실제로 사용한 쿼리
SELECT * FROM mypokemon AS t1 INNER JOIN mypokemon AS t2 ON t1.number = t2.number;
다양한 방식으로 테이블을 합치는 실습
문제1. 포켓몬 테이블과 능력치 테이블을 합쳐서 포켓몬 이름, 공격력, 방어력을 한번에 가져오기
이 때, 포켓몬 테이블에 있는 모든 포켓몬의 데이터를 가져올 것. 만약, 포켓몬의 능력치 데이터를 구할 수 없다면, NULL을 가져와도 좋다.

유의사항!
같은 이름을 가지는 컬럼이 있다면 SELECT 해 올 때,
어떤 테이블에서 합쳐진 컬럼을 가져올 것인지 명시해 줘야 합니다. 아래는 INNER JOIN 예시 결과
| number | name | type | number | height | weight | attack | defense | speed |
| 10 | caterpie | bug | 10 | 0.3 | 2.9 | 30 | 35 | 45 |
| 25 | pikachu | electric | 25 | 0.4 | 6 | 55 | 40 | 90 |
| 133 | eevee | normal | 133 | 0.3 | 6.5 | 55 | 50 | 55 |
| 152 | chikoirita | grass | 152 | 0.9 | 6.4 | 49 | 65 | 45 |
SELECT number (X) ERROR!
SELECT mypokemon.number 또는 ability.number (O)
문제2. 포켓몬 테이블과 능력치 테이블을 합쳐서 포켓몬 번호와 이름을 한번에 가져오기
이 때, 능력치 테이블에 있는 모든 포켓몬의 데이터를 가져올 것. 만약, 포켓몬의 이름 데이터를 구할 수 없다면, NULL을 가져와도 좋다.


테이블을 합쳐 원하는 값을 가져오는 실습
문제1. 내 포켓몬의 타입별 키의 평균 구하기

문제2. 내 포켓몬의 타입별 몸무게의 평균 구하기

문제3. 내 포켓몬의 타입별 키의 평균과 몸무게의 평균을 함께 가져오기
유의사항! 모든문제결과에 타입값을 반드시 포함해주기
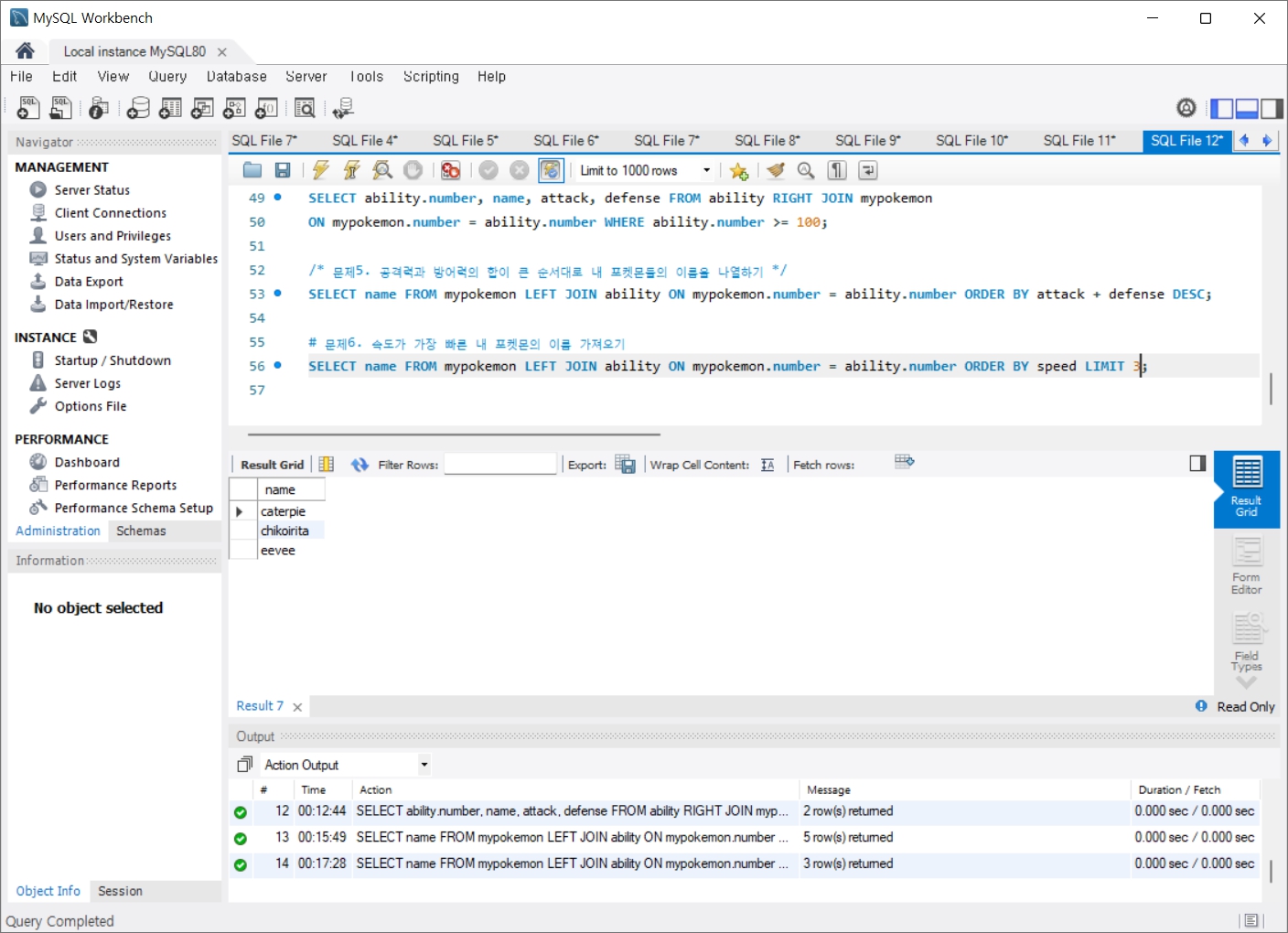
문제4. 번호가 100이상인 내 포켓몬들의 번호, 이름, 공격력, 방어력을 가져오기


문제5. 공격력과 방어력의 합이 큰 순서대로 내 포켓몬들의 이름을 나열하기

문제6. 속도가 가장 빠른 내 포켓몬의 이름 가져오기
여러테이블 한번에 다루기
나와 친구의 모든 포켓몬 데이터를 한번에 가져오기를 요청하면 여러 테이블을 한번에 다룰 수 있어야 한다. 합집합이다.
집합연산의 종류는 합집합, 교집합, 차집합이 있다.
데이터에 데이터더하기
UNION, UNION ALL의 특징
- [쿼리 A] UNION [쿼리B] 또는 [쿼리 A] UNION ALL [쿼리B] 형식으로 사용
- [쿼리 A]와 [쿼리 B]의 결과 값을 합침
- UNION은 동일한 값은 제외하고 보여주며, UNION ALL은 동일한 값도 포함
- [쿼리 A]와 [쿼리 B]의 결과 값의 개수가 같아야 하지만 다르면 에러가 발생
- ORDER BY는 쿼리 가장 마지막에 작성 가능하고, [쿼리 A]에서 가져온 컬럼으로만 가능
쿼리문법
#1.
SELECT [컬럼 이름] FROM [테이블 A 이름]
UNION SELECT [컬럼 이름] FROM [테이블 B 이름]
#2.
SELECT [컬럼 이름] FROM [테이블 A 이름]
UNION ALL SELECT [컬럼 이름] FROM [테이블 B 이름]
UNION ALL사용예제 쿼리
SELECT name FROM mypokemon
UNION ALL
SELECT name FROM friendpokemon;
UNION 사용예제 쿼리
SELECT name FROM mypokemon
UNION
SELECT name FROM friendpokemon;
UNION, ORDER BY 사용예제 쿼리
SELECT number, name, attack FROM mypokemon
UNION
SELECT number, name, attack FROM friendpokemon
ORDER BY number; # ORDER BY는 쿼리 가장 마지막에 작성 가능하고, [쿼리 A]에서 가져온 컬럼으로만 가능
데이터에서 데이터빼기
교집합과 차집합은 MySQL에서 두 표현이 존재하지 않기 때문에 JOIN을 사용해서 표현
교집합 쿼리문법
SELECT [컬럼 이름] FROM [테이블 A 이름] AS A INNER JOIN [테이블 B 이름] AS B
ON A.[컬럼1 이름] = B.[컬럼1 이름] AND ... AND A.[컬럼n 이름] = B.[컬럼n 이름];
# 교집합을 확인 하고 싶은 컬럼은 모두 다 기준으로 두고 합쳐 줘야 함 (단순 INNER JOIN과의 차이점)
교집합예제 쿼리문은?
쿼리문은?
SELECT A.name FROM mypokemon AS A INNER JOIN friendpokemon AS B ON A.name = B.name;
※ 같은 이름을 가지는 컬럼이 있다면 SELECT 해 올 때, 어떤 테이블에서 컬럼을 가져올지 명시하기
두번째 쿼리문은?
SELECT A.name FROM mypokemon AS A INNER JOIN friendpokemon AS B
ON A.number = B.number AND A.name = B.name AND A.type = B.type AND A.attack = B.attack AND
A.defense = B.defense;
차집합 쿼리문법
SELECT [컬럼 이름] FROM [테이블 A 이름] AS A LEFT JOIN [테이블 B 이름] AS B
ON A.[컬럼1 이름] = B.[컬럼1 이름] AND ... AND A.[컬럼n 이름] = B.[컬럼n 이름] WHERE B.[컬럼 이름] IS NULL;
# 차집합을 확인 하고 싶은 컬럼은 모두 다 기준으로 두고 합치기
차집합예제 쿼리문은?
#1. SELECT A.name
FROM mypokemon AS A LEFT JOIN friendpokemon AS B ON A.name = B.name WHERE B.name IS NULL;
#2. SELECT A.name FROM mypokemon AS A LEFT JOIN friendpokemon AS B
ON A.number = B.number AND A.name = B.name AND A.type = B.type AND A.attack = B.attack AND
A.defense = B.defense WHERE B.name IS NULL;
여러테이블의 데이터를 한번에 조회해보는 실습
문제1. 내 포켓몬과 친구의 포켓몬에 어떤 타입들이 있는지 중복 제외하고 같은 타입은 한 번 씩만 가져오기

문제2. 내 포켓몬과 친구의 포켓몬 중에 풀(grass) 타입 포켓몬들의 포켓몬 번호와 이름을 중복 포함하여 전부 가져오기


여러테이블을 다뤄서 원하는 값을 가져오는 실습
문제1. 나도 가지고 있고, 친구도 가지고 있는 포켓몬의 이름을 가져오기

문제2. 나만 가지고 있고, 친구는 안 가지고 있는 포켓몬의 이름을 가져오기

조건에 조건 더하기
하나의 쿼리 내 포함된 또 하나의 쿼리 서브쿼리의 특징
- 서브 쿼리는 반드시 괄호 안에 있어야 합니다.
- SELECT, FROM, WHERE, HAVING, ORDER BY 절에 사용 가능합니다.
- INSERT, UPDATE, DELETE 문에도 사용 가능합니다.
- 서브쿼리에는 ; (세미 콜론)을 붙이지 않아도 됩니다.
| 메인쿼리 | SELECT | 서브쿼리 SELECT FROM WHERE GROUP BY HAVING ORDER BY |
| FROM | ||
| WHERE | ||
| GROUP BY | ||
| HAVING | ||
| ORDER BY |
SELECT절의 서브쿼리
- 스칼라 서브쿼리라고도 합니다.
- SELECT절의 서브 쿼리는 반드시 결과값이 하나의 값 이어야 합니다.
쿼리문법
SELECT [컬럼 이름],
( SELECT [컬럼 이름] FROM [테이블 이름] WHERE 조건식 )
FROM [테이블 이름] WHERE 조건식;
SELECT절의 서브 쿼리 예제
피카츄의 번호, 영문이름, 키를 가져오는 요청 쿼리
SELECT number, name,
(SELECT height FROM ability WHERE number = 25) AS height
FROM mypokemon WHERE name = ‘pikachu’;
# SELECT절의 서브 쿼리는 반드시 결과 값이 하나의 값
| number | name | height |
| 25 | pikachu | 0.4 |
FROM절의 서브쿼리
- 인라인 뷰 서브쿼리라고도 합니다.
- FROM절의 서브 쿼리는 반드시 결과값이 하나의 테이블이여야 합니다.
- 서브 쿼리로 만든 테이블은 반드시 별명을 가져야 합니다.
쿼리문법
SELECT [컬럼 이름] FROM
( SELECT [컬럼 이름] FROM [테이블 이름] WHERE 조건식 )
AS [테이블 별명]WHERE 조건식;
FROM절의 서브쿼리예제
키순위가 3순위인 포켓몬의 번호와 키순위를 가져오는 요청쿼리
SELECT number, height_rank FROM
(SELECT number, rank() OVER(ORDER BY height DESC) AS height_rank FROM ability)
AS A WHERE height_rank = 3;
| number | height_rank |
| 152 | 1 |
| 26 | 2 |
| 25 | 3 |
| 10 | 4 |
| 133 | 4 |
WHERE절의 서브쿼리
- 중첩 서브쿼리
- WHERE절의 서브 쿼리는 반드시 결과값이 하나의 컬럼 이어야 하지만 EXISTS는 제외
- 하나의 컬럼에는 여러 개의 값이 존재하며 연산자와 함께 사용
- 보통 WHERE [컬럼 이름] [연산자] [서브 쿼리] 형식으로 사용
쿼리문법
SELECT [컬럼 이름] FROM [테이블 이름] WHERE [컬럼 이름] [연산자]
( SELECT [컬럼 이름] FROM [테이블 이름] WHERE 조건식 );
WHERE절의 서브쿼리예제1
키가 평균키보다 작은 포켓몬의 번호를 가져오는 요청쿼리
SELECT number FROM ability
WHERE height < (SELECT AVG(height) FROM ability);
| number |
| 10 |
| 25 |
| 133 |
WHERE절의 서브쿼리예제2
공격력이 모든 전기포켓몬의 공격력보다 작은 포켓몬의 번호를 가져오는 요청쿼리
SELECT number FROM ability
WHERE attack < ALL(SELECT attack FROM ability WHERE type = ‘electric’);
WHERE절의 서브쿼리예제3
방어력이 모든 전기포켓몬의 공격력보다 하나라도 큰 포켓몬의 번호를 가져오는 요청쿼리
SELECT number FROM ability
WHERE defense > ANY(SELECT attack FROM ability WHERE type = ‘electric’);
WHERE절의 서브쿼리예제4
bug타입 포켓몬이 있다면 모든 포켓몬의 번호를 가져오는 요청쿼리
SELECT number FROM ability
WHERE EXISTS(SELECT * FROM ability WHERE type = ‘bug’);
서브쿼리로 복잡한 조건을 하나의 쿼리로 만들어 보는 실습
문제1. 내 포켓몬 중에 몸무게가 가장 많이 나가는 포켓몬의 번호를 가져오기

문제2. 속도가 모든 전기 포켓몬의 공격력보다 하나라도 작은 포켓몬의 번호를 가져오기

문제3. 공격력이 방어력보다 큰 포켓몬이 있다면 모든 포켓몬의 이름을 가져오기

서브쿼리로 복잡한 조건을 하나의 쿼리로 만들어 보는 두번째 실습
문제1. 이브이의 번호 133을 활용해서, 이브이의 영문 이름, 키, 몸무게를 가져오기
이 때, 키는 height, 몸무게는 weight이라는 별명으로...


문제2. 속도가 2번째로 빠른 포켓몬의 번호와 속도를 가져오기

문제3. 방어력이 모든 전기 포켓몬의 방어력보다 큰 포켓몬의 이름을 가져오기

알아두면 좋은 고급기능
데이터삭제, 수정하기
데이터삭제하기(Day2 Remind) 쿼리문법
DELETE FROM [테이블 이름] WHERE 조건식;
데이터 삭제하기 예제쿼리
DELETE FROM pokemon.mypokemon WHERE attack > 50;
데이터수정하기(Day2 Remind) 쿼리문법
UPDATE [테이블 이름] SET [컬럼 이름] = [새 값] WHERE 조건식;
데이터 수정하기 예제쿼리
UPDATE pokemon.mypokemon SET type = ‘normal’
WHERE name = ‘chikorita’;
Error Code:1175발생시 해결방안?

제약조건
- 데이터를 입력할 때 실행되는 데이터입력규칙
- 테이블을 만들거나 변경하면서 설정한다. # CREATE TABLE 및 ALTER TABLE 구문
제약조건의 종류
| 제약조건 | 의미 |
| NOT NULL | 이 컬럼에는 NULL 값을 저장할 수 없다. |
| UNIQUE | 이 컬럼의 값들은 서로 다른 값을 가져야 한다. |
| DEFAULT | 이 컬럼에 입력값이 없을 시 기본값이 설정된다. |
| PRIMARY KEY | 이 컬럼은 테이블의 기본 키다. NOT NULL과 UNIQUE 특징을 모두 가진다. |
| FOREIGN KEY | 이 컬럼은 테이블의 외래 키다. 이 컬럼은 다른 테이블의 특정 컬럼을 참조한다. |
테이블만들기 (Day2 Remind) 쿼리문법
CREATE TABLE [테이블 이름] (
[컬럼 이름] [데이터 타입], [컬럼 이름] [데이터 타입], …
);
제약조건과 함께 테이블만들기 쿼리문법
CREATE TABLE [테이블 이름] (
[컬럼 이름] [데이터 타입] [제약 조건], [컬럼 이름] [데이터 타입] [제약 조건], …
);
쿼리예시)
CREATE TABLE new_mypokemon(
number INT PRIMARY KEY,
name VARCHAR(20) UNIQUE,
type VARCHAR(10) NOT NULL,
attack INT DEFAULT 0,
defense INT DEFAULT 100,
FOREIGN KEY(number) REFERENCES mypokemon(number)
); # FOREIGN KEY는 참조하는 테이블의 PRIMARY KEY여야 함.
권한과 DCL
SQL분류
| 분류 | 종류 | 의미 | |
| DDL | Data Definition Language | CREATE ALTER DROP RENAME TRUNCAT |
데이터정의어 |
| DML | Data Manipulation Language | SELECT INSERT UPDATE DELETE |
데이터조작어 |
| DCL | Data Control Language | GRANT REVOKE |
데이터제어어 |
| TCL | Transaction Control Language | COMMIT ROLLBACK SAVEPOINT |
트랜잭션제어어 |
사용자 확인하기 쿼리문법
# MySQL 기본 데이터베이스인 mysql 데이터베이스 선택하기
USE mysql;
# 사용자 목록 조회하기
SELECT user, host FROM user;
사용자생성, 삭제하기 쿼리문법
# 사용자 생성하기
CREATE USER [사용자 이름]@[ip주소];
# 비밀번호와 함께 사용자 생성하기(사용자비밀번호는 문자열이어서 따옴표로 감싸기)
CREATE USER [사용자 이름]@[ip주소] IDENTIFIED BY ‘[사용자 비밀번호]’;
# 사용자 삭제하기
DROP USER [사용자 이름];
권한부여하는 쿼리문법
# 권한 부여하기
GRANT [권한] ON [데이터베이스 이름].[테이블 이름] TO [사용자 이름]@[ip주소];
# 권한 확인하기
SHOW GRANTS FOR [사용자 이름]@[ip주소];
# 권한 삭제하기
REVOKE [권한] ON [데이터베이스 이름].[테이블 이름] FROM [사용자 이름]@[ip주소];
# 권한 적용하기
FLUSH PRIVILEGES;
예시)
# newuser@%에게 mydb.mytb에 대한 모든 권한 부여하기
GRANT ALL PRIVILEGES ON mydb.mytb TO newuser@%;
# newuser@%에게 모든 데이터베이스, 모든 테이블에 대한 SELECT, INSERT 권한 부여하기
GRANT SELECT, INSERT ON *.* TO newuser@%;
트랜잭션과 TCL
데이터베이스의 데이터 상태를 바꾸는 작업 묶음
| INSERT... INSERT... DELETE... INSERT... |
트랜잭션 쿼리문법
#트랜잭션 시작하기
START TRANSACTION;
# 트랜잭션 확정하기
COMMIT;
# 트랜잭션 이전으로 돌아가기
ROLLBACK;
세이브포인트
트랜잭션내 특정한 저장지점을 쿼리문법으로 작성하였다.
# 세이브포인트 만들기
SAVEPOINT [세이브포인트 이름];
# 세이브포인트로 돌아가기
ROLLBACK TO [세이브포인트 이름];
마무리
강의총정리 및 데이터분석로드맵
데이터관련 직무 로드맵
SQL - 비즈니스 애널리스트, 데이터 분석가, 데이터 사이언티스트, 데이터 엔지니어
비즈니스 애널리스트 (SQL->BI)
- 비즈니스 데이터를 분석해 의미를 찾는 직무
- 주로 하는 업무 예시
§ 비즈니스 KPI 정의
§ AB 테스트 - 주로 사용하는 기술
§ SQL
§ 데이터 시각화 (BI)
§ 커뮤니케이션
데이터 분석가 (SQL->Python/R,통계)
- 데이터를 가공하고 분석해 의미를 찾는 직무
- 주로 하는 업무 예시
§ 통계 분석 - 주로 사용하는 기술
§ SQL
§ Python/R
§ 통계
데이터 사이언티스트 (SQL->Python/R,통계->머신러닝)
- 데이터를 활용해 모델, 알고리즘을 개발하는 직무
- 주로 하는 업무 예시
§ 머신 러닝 모델링
§ 예측, 최적화 - 주로 사용하는 기술
§ SQL
§ Python/R
§ 머신 러닝
데이터 엔지니어 (SQL->프로그래밍언어->빅데이터처리프레임워크)
- 데이터를 수집하고 정제하는 직무
- 주로 하는 업무 예시
§ 데이터 처리 시스템 구축, 최적화 - 주로 사용하는 기술
§ SQL
§ 프로그래밍 언어 (Python, JAVA)
§ 빅데이터 처리 프레임워크 (하둡, 스파크, 카프카)
Cheet Sheet


오리엔테이션 & 실무 문제풀이 소개 & 서비스 이해
강의목표
- 다양하고 많은 종류의 SQL문제풀이로 실력을 향상
- 기초문제부터 고급문제까지
- 실무에 접하는 문제를 다뤄서 업무에 SQL활용
- 쿼리 학습용 문제풀이, 취업이나 이직시 필요한 SQL코딩테스트 준비
실습환경구축
MySQL Workbench(Window OS)
https://dev.mysql.com/downloads/workbench/
MySQL :: Download MySQL Workbench
Select Operating System: Select Operating System… Microsoft Windows Ubuntu Linux Red Hat Enterprise Linux / Oracle Linux Fedora macOS Source Code Select OS Version: All Windows (x86, 64-bit) Recommended Download: Other Downloads: Windows (x86, 64-bit), M
dev.mysql.com




Sample DB
Google Drive Link


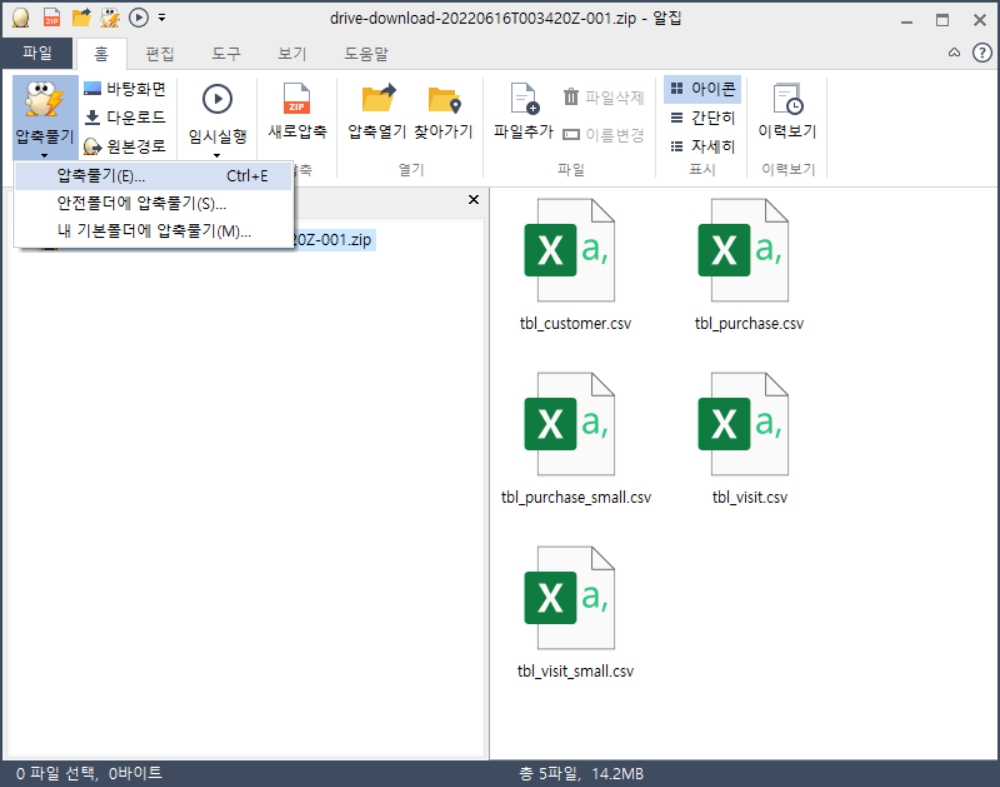


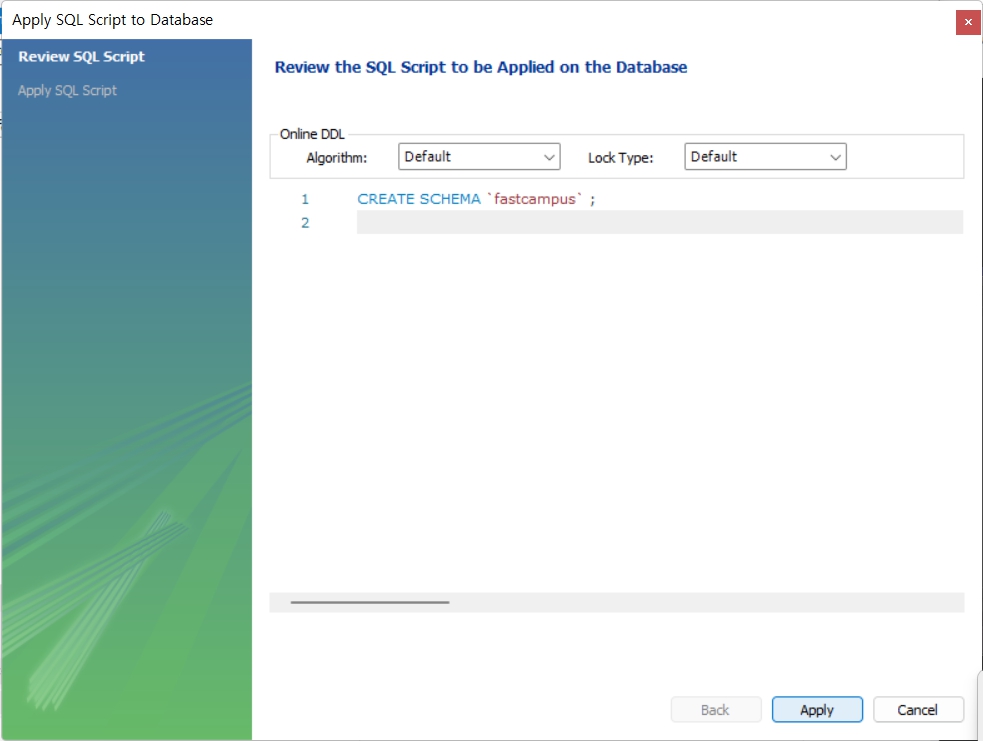

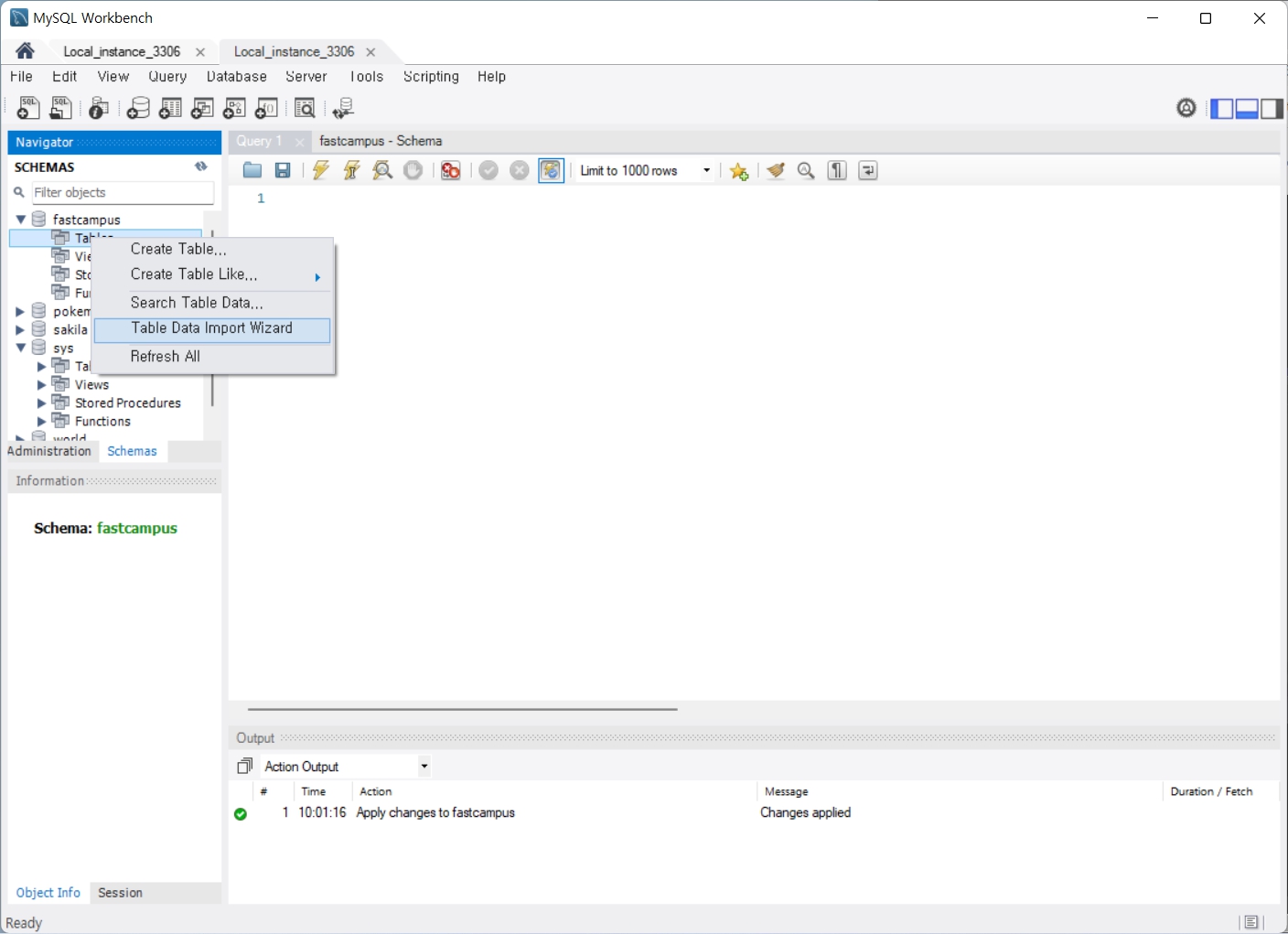


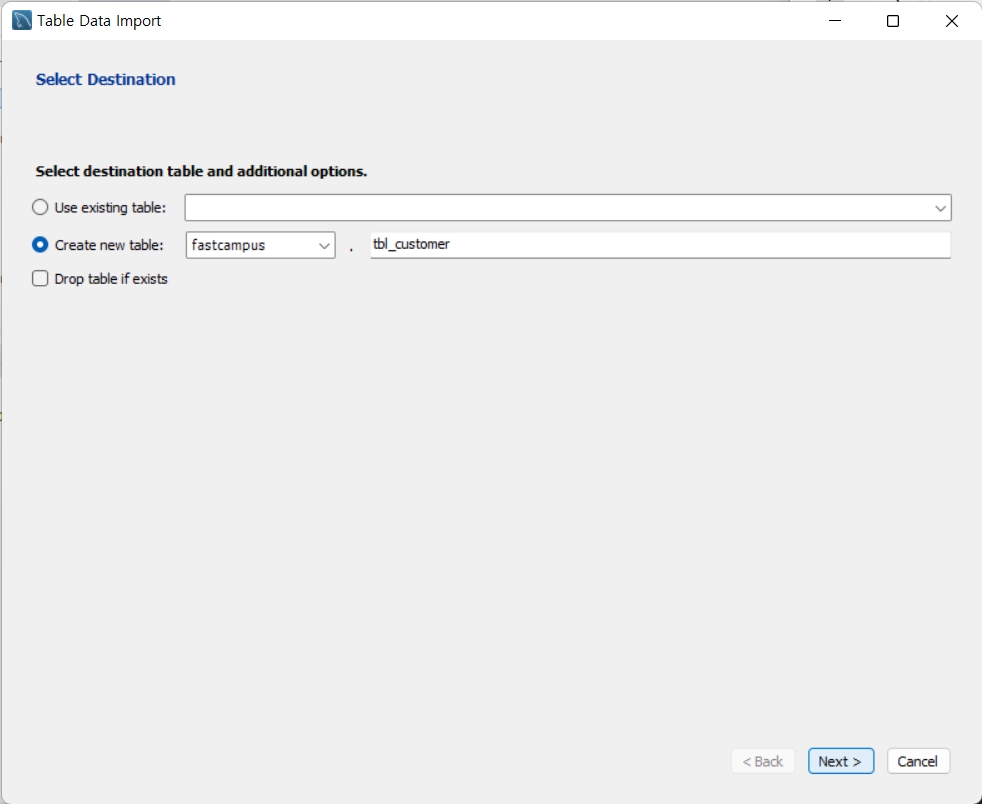














!!!유의사항!!!
테이블을 두개이상 동시에 만든다? 데이터를 두개 이상 동시에 임포트하면 log화면에 failed메세지가 뜨게 된다.
failed의 의미는 데이터를 임포트하는 과정에서 일부를 불러오지 못하고 테이블 내부의 데이터에 손실을 초래하게 된다는 것이다. 그러므로 가급적이면 한개씩 데이터를 임포트해야 failed없이 성공적으로 모두 불러올 수 있다.
실무문제풀이
21문제로 Section별 강의 전 직접 풀어보고 고민하는 것이다.
서비스이해
1. 2020년 7월의 총 Revenue를 구하기
집계함수 사용, WHERE절에 Date필터(속도향상), SQL문 실행순서: 구분분석>FROM>WHERE>SELECT 순

2. 2020년 7월의 MAU을 구하기
Active User, count함수 이해
- count(*): 모든 rows 카운팅
- count(customer_id): customer_id의 null값 제외 카운팅
- count(distinct customer_id): unique customer_id 카운팅

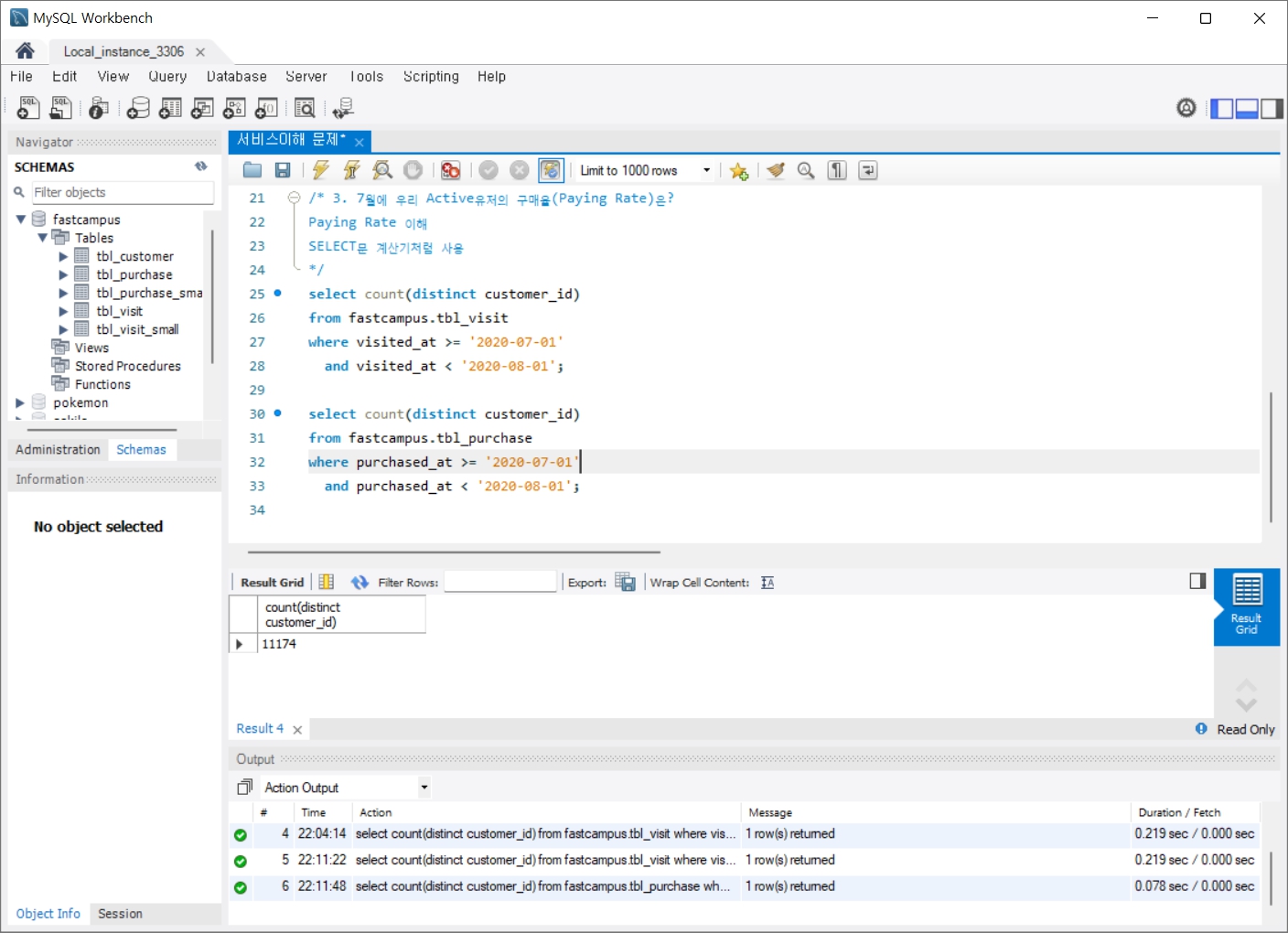
3. 2020년 7월에 우리 Active유저의 구매율(Paying Rate)은?
- Paying Rate 이해
- SELECT문 계산기처럼 사용


4. 2020년 7월에 구매유저의 월 평균 구매금액은?
- ARPPU(Average Revenue per Paying user) 이해
- Group By, 서브쿼리(인라인 뷰) 사용

5. 2020년 7월에 가장 많이 구매한 고객 top3와 Top10~15 고객은?
- ORDER BY 사용
- LIMIT, OFFSET 사용
- SQL문 실행순서: From → Where → Group by → Select → Order by


날짜 및 시간별 분석
Date Format
- formatting parameter에 원하는 규칙대로 입력
- ex. date_format(visited_at, '%Y-%m-%d'): 2020-08-01
| Format | Description | Format | Description |
| %j | n번째 일(100, 365) | %M | Month 월(Janeary, February ...) |
| %H | Hour 시(00, 01, 24) 24시간 형태 | %m | Month 월(01, 02, 03 ...) |
| %h | Hour 시(01, 02, 12) 12시간 형태 | %W | Day of Week 요일(Sunday, Monday ...) |
| %T | hh:mm:ss | %D | Month 월(1st, 2nd, 3rd ...) |
| %S,%s | Second 초 | %Y | Year 연도(1990, 2010, 2021) |
| %p | AP, PM | %y | Year 연도(90, 10, 21) |
| %w | Day Of Week (0, 1, 2) 0부터 일요일 | %a | Day of Week요일(Sun, Mon, Tue ...) |
| %U | Week 주(시작: 일요일) | %d | Day 일(00, 01, 02 ...) |
| %u | Week 주(시작 월요일) |
1. 2020년 7월의 평균 DAU를 구하고, Active User 수가 증가하는 추세인가?
- Daily Active Users 이해
- Date Format 함수 사용, 시간대 바뀌지 않는지 체크
- 추세확인


2. 2020년 7월의 평균 WAU을 구하기
- Weekly Active Users 이해
- 올바른 값을 위해 날짜범위 좁히기

3. 2020년 7월의 Daily Revenue는 증가하는 추세인가? 평균 Daily Revenue도 구하기



4. 2020년 7월의 평균 Weekly Revenue를 구하기
- Weekly Revenue 이해

5. 2020년 7월 요일별 Revenue를 구하고 어느 요일이 Revenue가 가장 높고 어느 요일이 Revenue가 가장 낮은가?
- 정확한 값 계산을 위해 일별 매출 구하기
- 요일별로 포맷팅하기

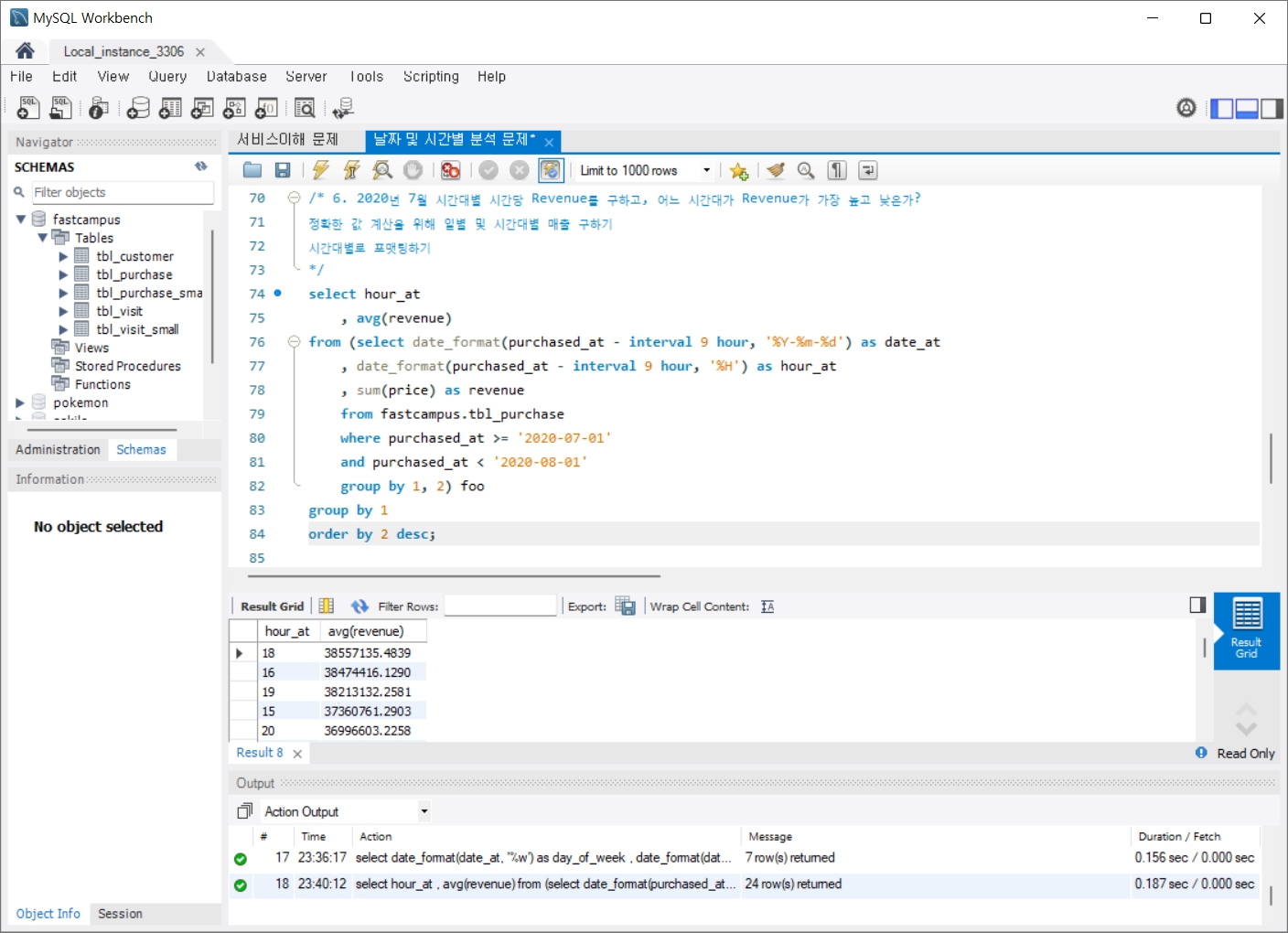
6. 2020년 7월 시간대별 시간당 Revenue를 구하고, 어느 시간대가 Revenue가 가장 높고 낮은가?
- 정확한 값 계산을 위해 일별 및 시간대별 매출 구하기
- 시간대별로 포맷팅하기

7. 2020년 7월 요일 및 시간대별 Revenue(평균)를 구하기?
- 정확한 값 계산을 위해 일별 매출 구하기
- 요일 및 시간별로 포맷팅하기


assignment
- 요일 및 시간대 별 Active User수 계산
유저 세그먼트별 분석
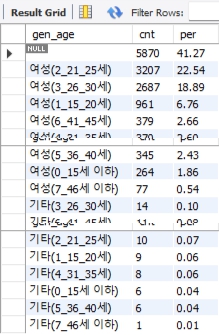
1. 전체유저의 Demographic을 알고 싶다면 성 및 연령별로 유저숫자를 알려주면 어느 세그먼트가 가장 숫자가 많은가? 참고로 기타 성별은 하나로, 연령은 5세 단위로 적당히 묶고 숫자가 높은 순서대로 보여주기
- Case when 사용
- Null값 오류대처
- Group by, Order by 사용



2. 1번 결과의 성 및 연령을 성별(연령)(ex. 남성(25~29세 이하))로 통합하고, 각 성 및 연령이 전체고객에서 얼마나 차지하는지 분포(%)를 알려주면 분포가 높은 순서대로 알려주기
- Concat 함수 사용
- Scala Subquery 사용


3. 2020년 7월의 성별에 따라 구매건수와 총 Revenue를 구하는데 남녀이외의 성별은 하나로 묶기
- Join과 Group by 함께 사용

4. 2020년 7월의 성별/연령대에 따라 구매건수와 총 Revenue를 구하는데 남녀이외의 성별은 하나로 묶기
- Join과 Group by 함께 사용



매출관련 추가분석
1. 2020년 7월 일별매출과 증감폭, 증감률을 구하기
- with문: 서브쿼리를 사용해서 임시테이블처럼 사용할 수 있는 구문으로 옵티마이저가 인라인뷰나 임시테이블로 판단
- window 함수(행 순서 함수) 이해
• lag: 이전 행을 가져오기
• lead: 특정 위치의 행을 가져오기 (default는 1: 다음 행을 가져오기)



2. 2020년 7월 일별로 많이 구매한 고객들한테 소정의 선물을 주려고 한다. 7월에 일별로 구매금액기준으로 가장 많이 지출한 고객 Top3를 구하기
- Rank 함수 이해
• ex. rank() over (partition by c1, c2 order by price desc)
• rank: 동일한 값이면 같은 순위를 매기고, 다음 값에서는 다음 순위를 매김
• dense_rank: 동일한 값이면 같은 순위를 매기고, 동일한 순위를 하나의 rank로 계산
• row_number: 중복허용없음. 동일한 순위에 대해서 고유의 순위 부여



프로덕트 분석심화
1. 2020년 7월 우리 신규유저가 하루 안에 결제로 넘어가는 비율이 어떻게 될까? 그 비율이 어떤지 알고 싶고, 결제까지 보통 몇 분 정도가 소요되는지 알아보기
- Paying Conversion within 1 day 이해
- 최초구매일 찾기
- LEFT JOIN 사용한 이유
- TIMEDIFF 사용



2. 우리 서비스는 유저의 재방문율이 높은 서비스인가? 이를 파악하기 위해 7월기준 Day1 Retention이 어떤지 구하고 추세를 보기 위해 Daily로 추출하기
- N-day Retention 이해
- SELF JOIN 사용

3. 우리 서비스는 신규유저가 많은가? 기존유저가 많은가? 유저들의 가입기간별로 그룹화해서 고객분포가 어떤지 알려주는데 DAU 기준으로 부탁합니다.
- User Age에 따른 DAU 분석
- 마지막 접속일 찾기
- DATEDIFF 사용


Hacker Rank
https://www.hackerrank.com/dashboard
Dashboard | HackerRank
Join over 16 million developers in solving code challenges on HackerRank, one of the best ways to prepare for programming interviews.
www.hackerrank.com
- For Developers로 Sign up > SQL파트
- 16문제로, Section별로 강의 전에 직접 해결해보기
- 영어는 최선을 다해서 직접 풀어보고 고민한다면...







Hacker Rank 문제
Aggregation
The Blunder에서 집계함수, Replace함수, CEIL함수 사용



Top Earners에서 집계함수, Scalar Subquery 사용



Weather Observation Station 15에서 집계함수, Scalar Subquery 사용


Weather Observation Station 19에서 유클리디안 거리공식 대입, 숫자형 함수 POWER사용



Weather Observation Station 20에서 Median 이해하고 순위함수와 올림, 내림함수 사용



Advanced Select
Type of Triangle에서 CASE WHEN문 사용



The PADS에서 문자형 함수 CONCAT, SUBSTR 사용


Occupations에서 RANK함수를 이용해서 그룹핑 할 컬럼 생성하거나 CASE WHEN문을 사용해서 SQL을 피봇하는 법 학습

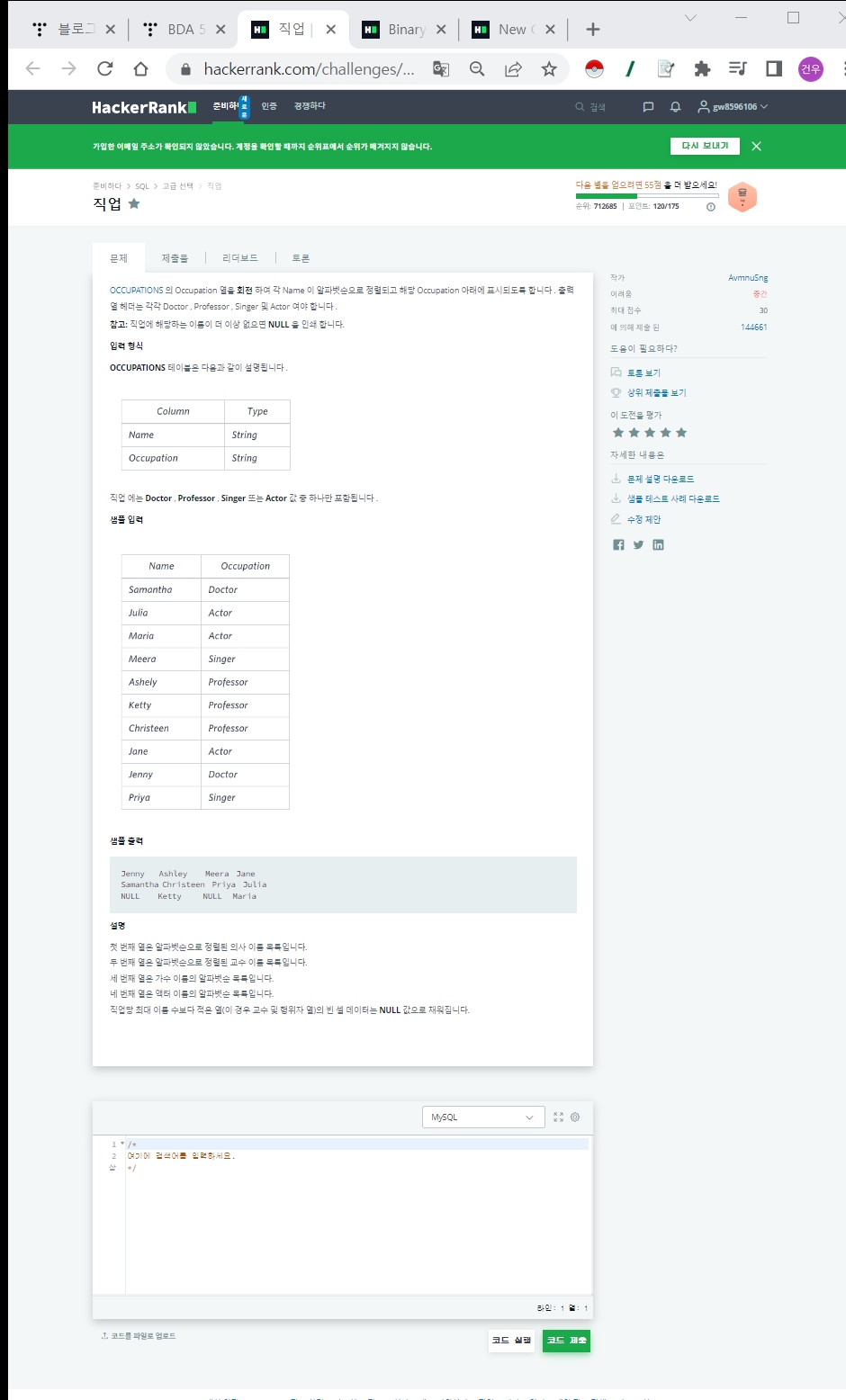

Binary Tree Node의 IN조건에 서브쿼리, CASE WHEN문 사용



New Companies에서 JOIN없이 쿼리문을 작성하고 메인쿼리와 조건을 따지는 스칼라 서브쿼리 사용



Basic Join
Average Population of Each Continent에서 JOIN을 위해 매칭되는 컬럼과 집계할 컬럼찾기



The Report에서 JOIN을 통해 점수마다 정확한 등급을 매핑시키고 우선순위에 따라 ORDER BY절 사용


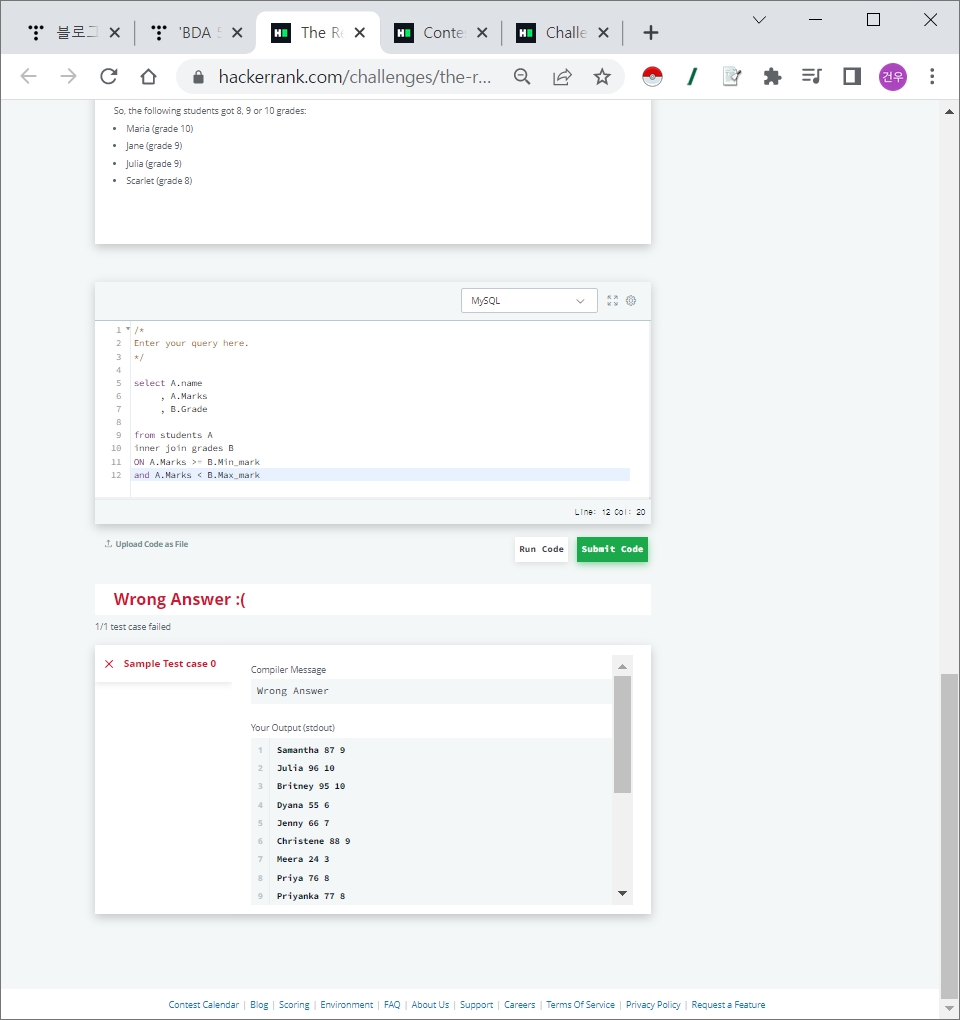

Contest Leaderboard에서 Challenge마다 Submission의 MAX Score, JOIN과 GROUP BY를 사용해서 Total Score를 구한다. 단, HAVING 조건을 사용해야 함.
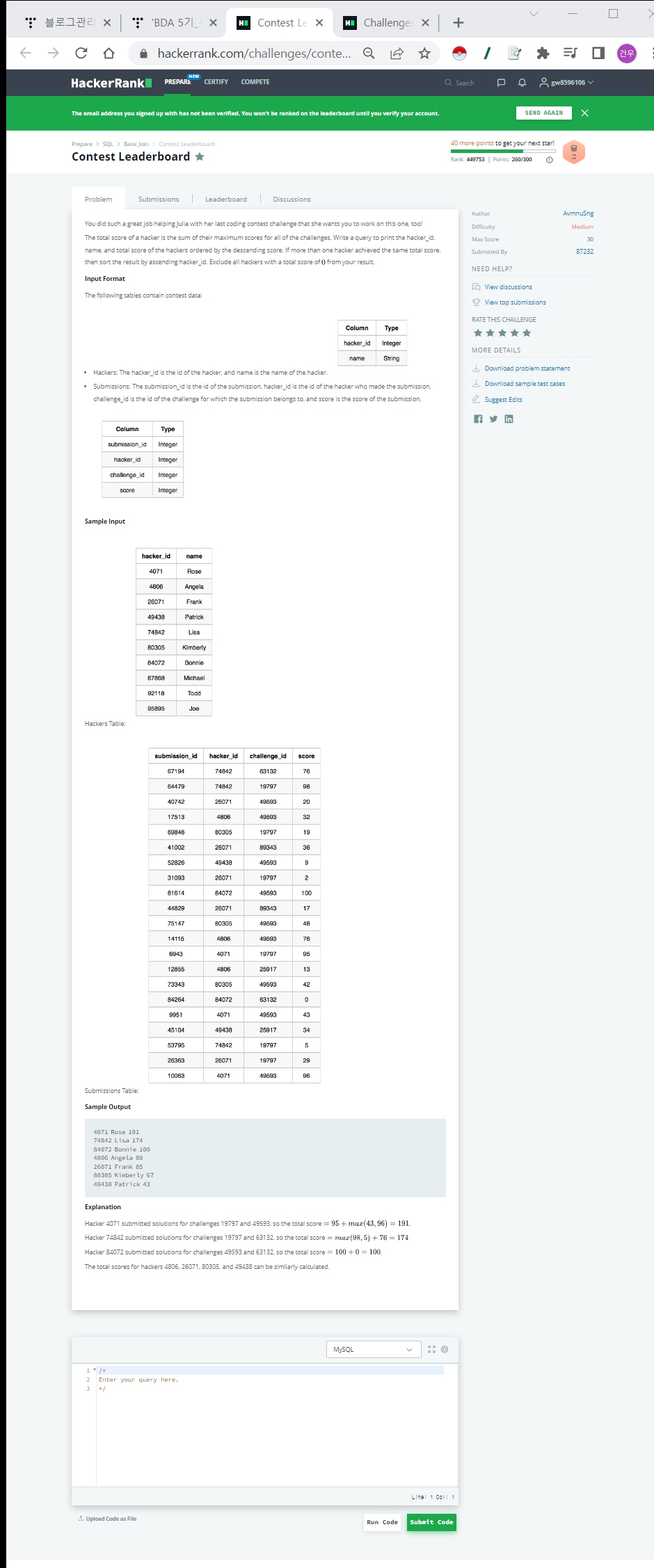


Challenges에서
- Hacker ID별로 제출한 Challenge수를 계산하기
- WHERE절에 서브쿼리 사용해서 조건에 부합한 Challenge수로 필터하기
- 서브쿼리시 Table alias 사용하기



Advance Join
Placements에서 본인과 친구의 Salary를 구하고 JOIN하여 조건(친구보다 Salart가 낮음)에 부합하는 결과 출력



SQL Project Planning에서
- 프로젝트의 Start Date, End Date가 될 수 있는 날짜 추리기
- Start Date가 End Date보다 작은(시점이 이른)조건으로 JOIN
- Start Date 기준으로 그룹핑





KDT(MGS BDA 5기) - 한 번에 끝내는 데이터 분석 툴 초격차 패키지 Online.
Part 4. SQL
실습환경구성
오라클 18c Express Edition 설치
https://drive.google.com/file/d/1fdLyiD_7Dso_sNWua7h-pXdxCk0PEmHz/view











DBeaver 설치
https://drive.google.com/file/d/1JaFsDSnSj6cTDy9iLKvO6iIoiqCY1yKh/view?usp=sharing
























SQL Developer 설치
https://drive.google.com/file/d/1n1weSeQPKkKiNnV7JIJqXN39y6hcQsVd/view







사용자 계정 및 테이블 스페이스 생성
⮚ SQL Developer를 이용하여 system 계정으로 오라클 접속




⮚ SQL Developer를 이용하여 system 계정으로 오라클 접속 - 계속

신규 생성한 사용자 계정으로 오라클 접속 및 SQL 실행



!!!유의사항!!!
SQL Developer와 DBeaver 중 하나만 사용해야 합니다.
왜냐면 전자를 임포트시켰다면 후자를 임포트시킬때 SQL_error 기존의 객체가 이름을 사용하고 있습니다. 라는 경고문이 뜹니다. 이미 전자에서 테이블을 생성했던 것을 후자에서 더 생성하게 되니까요.
DBeaver는 sql문을 기존 SQLdeveloper나 Workbench 같은 툴보다 사용자 입장에서 더 편하게 쓸 수 있게 도와주는 통합 툴이라고 생각하면 돼요.
기온데이터분석
기온데이터다운로드
https://data.kma.go.kr/cmmn/main.do




기온데이터테이블 생성 및 데이터입력
인구데이터분석
인구데이터다운로드
https://drive.google.com/file/d/1EQCWJazOuAPQfKVtVHzgwee51MA8g4XI/view?usp=sharing


인구 데이터 테이블 생성 및 데이터 입력










대중교통데이터분석
01. 대중교통데이터다운로드
https://pay.tmoney.co.kr/index.dev






02. 대중 교통 데이터 테이블 생성 및 데이터 입력










03. 승차, 하차 인원이 가장 많고 적은 역 모두 구하기
04. 출근 시간대 하차인원이 가장 많은 역 구하기
05. 출근 시간대 하차인원이 가장 많은 역 구하기
06. 23시 이후 사람들이 가장 많이 승차하는 역 구하기
07. 수도권 지하철의 각 호선별 승하차인원수가 가장 많은 역 구하기
상권정보데이터 분석
상권정보데이터 다운로드
https://drive.google.com/file/d/1rEu01aJ-s6NtVhE4npYevzdf-V9zu8jT/view?usp=sharing





상권정보데이터테이블생성 및 데이터입력






- 소스 데이터 열에 있는 칼럼과 대상 테이블 열에 있는 칼럼을 매핑 해주는 작업을 해야함
- 소스 데이터의 열 순서와 대상 테이블 열의 열 순서는 동일함 칼럼 하나하나 모두 매핑 해줘야 함
- 오류가 존재하지 않는다면 바로 "다음"으로 넘어가도 됨
- 모든 에러가 사라질때까지 칼럼에 대한 매핑 작업을 진행
- 오류가 존재하지 않는지 확인 후 "다음" 버튼 클릭







'데이터분석_워크시트' 카테고리의 다른 글
| BDA 5기_워크시트_이건우_220707 (0) | 2022.07.01 |
|---|---|
| BDA 5기_워크시트_이건우_220630 (0) | 2022.06.24 |
| BDA 5기_워크시트_이건우_220623 (0) | 2022.06.17 |
| BDA 5기_워크시트_이건우_220609 (0) | 2022.06.08 |
| BDA 5기_워크시트_이건우_220602 (0) | 2022.06.03 |



