
패스트캠퍼스_비즈니스_빅데이터_분석가_양성과정_5기_이건우
BDA 5기_워크시트_이건우_220609 본문
2주차 온라인 강의 학습범위(클립번호 기준): Excel프로젝트실습1~18, SQL패키지1~19(220603~220609)
데이터해석트레이닝
데이터분석의 맹점의 대표적인 예시
데이터는 거짓말을 하지 않는다?
그렇다기 보다는 예측하는 방식의 한계는 존재한다.
데이터 분석의 불편한 진실 10가지
1. Data is never clean.(데이터는 절대 깨끗하지 않다)
2. You will spend most of your time cleaning and preparing data. (당신은 분석의 대부분의 시간을 전처리 단계에서 보내게 될 것이다.)
3. 95% of tasks do not require deep learning. In 90% of cases generalized linear regression will do the trick.(90%의 경우 일반적인 선형회귀로도 문제를 해결할 수 있을 것이다. (fancy한 머신러닝 모델이 필요하지 않을 수도 있다는 이야기) 실제 분석의 90%는 GLM으로 해결된다.)
4. Big Data is just a tool (빅 데이터는 단지 도구일 뿐이다.)
5.You should embrace the Bayesian approach (당신은 베이지안 접근을 포용해야 한다.)
6. No one cares how you did it. (사용자 입장에서는 네가 어떤 방법을 사용했는가는 중요하지 않다.)
7. Academia and business are two different worlds. (학계와 산업계는 서로 다른 세계이다.)
8. Presentation is key - be a master of Power Point (프리젠테이션이 핵심이다: PowerPoint 의 마스터가 되라.)
9. All models are false, but some are useful. (모든 모델은 틀렸다, 하지만 몇몇은 유용하다)
10. There is no fully automated Data Science. You need to get your hands dirty (완전 자동화된 데이터 과학같은 것은 없다. 인간이 개입되어야 할 부분이 있다.)
인과관계 성립조건
- 선후관계: 원인이 결과보다 시간적으로 앞서야...
- 관련성: 원인과 결과는 관련이 있어야...
- 의존성: 결과는 원인이 되는 변수만으로 설명되어야...
상관관계와 인과관계
예시
- 나이가 어릴수록 자동차 사고율이 높다.
- 불황일수록 핍스틱이 잘 팔린다. (립스틱 효과)
- 패스트푸드를 많이 먹는 청소년이 탈선율이 높다.
- 키가 클 수록 몸무게가 많이 나간다.
기저귀와 맥주 판매량
상관관계-사실(fact)
기저귀구매고객들이 맥주를 함께구매한다는 패턴발견
두가지 상품구매에 상관관계가 있음을 확인
인과관계-통찰(insight)
육아를 하는 남편들이 Pub에 갈 시간이 줄어들어 마트에서 맥주를 구매해서 집에서 마시는 경향확인
일반화의 오류
책 읽는 아이를 만드는 유일한 요인은, 부모가 책을 읽느냐의 여부이다.
부모가 책을 읽으면, 아이들이 책을 읽을 가능성이 커진다.
부모가 책을 읽어야만 아이들도 책을 읽는다.
부모가 책을 읽지 않으면, 아이들도 책을 읽지 않는다.
부모가 책을 읽지 않으면, 아이들이 책을 읽을 리가 없어.
평균의 함정-평균을 의심하기
심슨의 역설?
퍼센트(%), 퍼센트포인트(%p)
Q) 실업률이 3.0%에서 4.5%로 증가했다면?
확률의 함정-확률과 직관
366명이 모여있는 그룹에서 생일이 같은 사람이 최소 2명이상 있을 확률은?
120명이 모여 있을 때 생일이 같은 사람이 최소 2명 이상 있을 확률은?
① 45.4% ② 63.2% ③ 90.8% ④ 99.99999998%
75명이 모여 있을 때 생일이 같은 사람이 최소 2명 이상 있을 확률은?
① 23.2% ② 51.3% ③ 87.8% ④ 99.972%
데이터 해석 접근법
해석적접근
반대급부적 관점 견지
연봉이 올랐다 <-> 세율도 올랐다
임금으로 태어났다 <-> 직업선택의 자유가 x
좋은 집 <-> 하우스푸어
방문당 페이지뷰와 세션당 체류시간이 높다 <-> 방문자가 헤매고 있다
자연검색의 유입비중은 증가 <-> 자연검색유입량은 그대로지만, 그 외 채널의 유입량은 하락
A매체의 유입성과가 가장 좋거나, 브랜딩에 가장 효과적인 매체
<->
광고비 비중이 절반이상 차지하고 CPA가 가장 높은 수준으로 낮은 효율(단, 유입성과는 유입량으로만 정의되지 않음)
예) 웹사이트 트래픽은 모바일에서 접속시 모바일페이지가 아닌 PC페이지로 연결
비교를 통한 입체화
정답보다 해답(solution)제시에 초점
데이터 분석을 통해 해결하고자 하는 핵심 문제로 데이터 활용의 가치는 정보(데이터) 자체가 아닌, 정보로부터 인사이트를 발굴하여 문제를 해결하기 위한 것이다.
| 과거 | 무슨일이 일어났는지 reporting | |
| 분석지향 | 현재 | 무슨일이 일어나는지 Warning or Alert |
| 미래 | 무슨일이 일어날 것인지 predict | |
| Focus | 분석지향으로 갈수록 데이터 데이터와 인사이트의 사이 '캐즘(chasm)' 해석지향으로 갈수록 인사이트 |
|
| 과거 | 왜, 어떻게 일어났는지 modeling | |
| 해석지향 | 현재 | 차선행동과 전략은 무엇인지 Advice or recommend |
| 미래 | 최악과 최선의 상황은 무엇인지 strategy |
틀리는 것을 두려워 말자 (봉숭아학당 맹구정신!)
아무런 인사이트도 없는 것(예. 팩트만 나열)보다 고민해 볼만한 인사이트는 어떨까?
팩트가 아닌 것에 대한 의견을 제시할 때는 이렇게 하자!
- “~인 것으로 파악됨” (파악:어떤 대상의 내용이나 본질을 확실하게 이해하여 앎)
- “~인 것으로 추정됨” (추정:미루어 생각하여 판정함)
- “~인 것으로 판단됨” (판단:사물을 인식하여 논리나 기준 등에 따라 판정을 내림)
- (Idea) “~을 통한 효과적 유입 확대 가능 예상, 추후 성과 파악을 통해 추가 인사이트 도출하여 지속적 개선코자 함”
분석적 접근
데이터블렌딩(혼합)
예) 포털 검색키워드 대비 자연유입을 분석하면 2개 이상의 데이터를 혼합하여 새로운 관점을 확보할 수 있다.
분석관점도출 시뮬레이션
데이터 Set의 Dimension과 Metric을 조합한 분석 항목 도출
| Dimension (분석관점) | * |
metric | -> |
분석항목 | ||
| •년 • 반기 • 분기 •월 • 월초반 • 월중반 • 월말 • 주차 • 시간 •분 •초 • 요일 |
* | 유입 • 채널별 • 소스별 • 매체별 • 직접유입 • 키워드광고 행동 • 페이지명 • 키워드 • 페이지타이틀 • 랜딩페이지 전환 • url • 지역 • 경로 |
• 세션수 • 방문자수 • 이탈률 • 매출액 • 전환수 • 전환율 • 페이지뷰 • 체류시간 • 페이지별체류시간 • 세션당페이지뷰 • 신규방문자 • 재방문자 • Unique 페이지뷰 |
• 시간대별 자연검색 세션 수 • 요일에 따른 키워드별 전환 수 • 월별 유입 경로에 따른 이탈률 변화 • 주차별 매체 전환율 추이 • 시간대별 신규방문자 세션 추이 • 년도별 경기 지역 방문자의 전환율 • 분기별 직접 유입 방문자수 • 요일별 랜딩페이지 방문자수 ... |
||
Data Modeling 측면에서는, Dimension을 얼마나 확장시킬 수 있느냐가 데이터 분석 범위와 수준을 결정하는데 중요하다.
데이터 세분화
쪼개고 쪼개고, 나누고 나누기
| 전월 대비 방문수가 늘었다 | ||||||
| L | organic 검색에서의 유입 기여도가 높았다 | |||||
| L | 브랜드 키워드보다 신규 상품 키워드의 유입량이 증가했다. | |||||
| L | organic 검색 유입의 65%가 신규 상품 키워드 Top5개에서 발생했다. | |||||
| L | 신규 상품 키워드 Top5 중 Top1 키워드가 전환수의 40%를 차지한다. | |||||
| L | 전환수가 가장 높게 나타나는 시기는 월말이다. | |||||
| L | 월말에 전환수가 높은 이유는, 급여일이 주로 월말인 이유가 크다. | |||||
"나에게 나무를 벨 8시간이 주어진다면 그 중 6시간은 도끼를 가는데 쓰겠다" -에이브러햄 링컨-
"미래는 데이터를 수집(collect)하고 집계하고 분할하고 통합하고 시각화하고 해석하는 자의 것이다."
- 인터넷의 아버지 Vint Cerf(구글 부사장) -
빅데이터 어젠다
- 통찰을 보는 눈, 데이터시각화
- 빅브라더(권력자들의 사회 감시 및 통제 수단)
- 데이터개방화와 마이데이터
데이터를 보는 매의 눈?
| 경계 / 조심 | 비약 | 논리나 사고방식이 그 차례나 단계를 따르지 않고 뛰어넘기 |
| 편향 | 한쪽으로 치우침 | |
| 왜곡 | 사실과 다르게 해석하거나 그릇되게 함. | |
| 간파 | 조작 | 어떤 일을 사실인 듯이 꾸밈 |
| 날조 | 사실이 아닌 것을 사실인 것처럼 거짓으로... | |
| 사기 | 나쁜 꾀로 남을 속임 |
데이터 리터러시 향상 - 차트 해독력 증대
적절한 차트 선택 방법은 아래 파일을 접속해서 131-140페이지 참조
데이터 활용 역량
빅데이터 활용영역
| Superman | |||||
| Data engineer | Data scientist | Field | |||
| 수집 | 처리 | 분석 | 해석과 이해 | 의사결정 | 실행 및 개선 |
| 데이터 시각화 | |||||
| 기술에 대한 이해 | 비즈니스와 사람에 대한 이해 | ||||
데이터과학의 영역
| 데이터영역 | 융합의 영역 |
| Identity/테크니션(Technician) | 해석과 이해(Understanding) |
| Capability/스킬(Skill) | 관점(Perspective) |
| Field/기술(Technology) | 인문학(Humanities) |
| Focus/정확도,효율성(Accuracy,Efficiency) | 통찰력(Insight) |
| Purpose/분석(Analytics) | 전략가(Strategist) |
빅데이터 도입 및 활용 Check point
| Where 가용 데이터 파악 |
>>> | How 범위 및 방법 기획 |
>>> | What (Goal) 성과 정의 및 관리 |
>>> | Small start |
| Why 기대 효과 정의 |
||||||
| Who 활용 주체 정의 |
||||||
| When |
KDT(MGS BDA 5기) - 한번에 끝내는 데이터분석 초격차 패키지 Online Part3. Excel 프로젝트 실습
공공자전거(따릉이) 데이터분석
데이터탐색하기
피벗테이블 실습









산점도와 박스플롯 실습








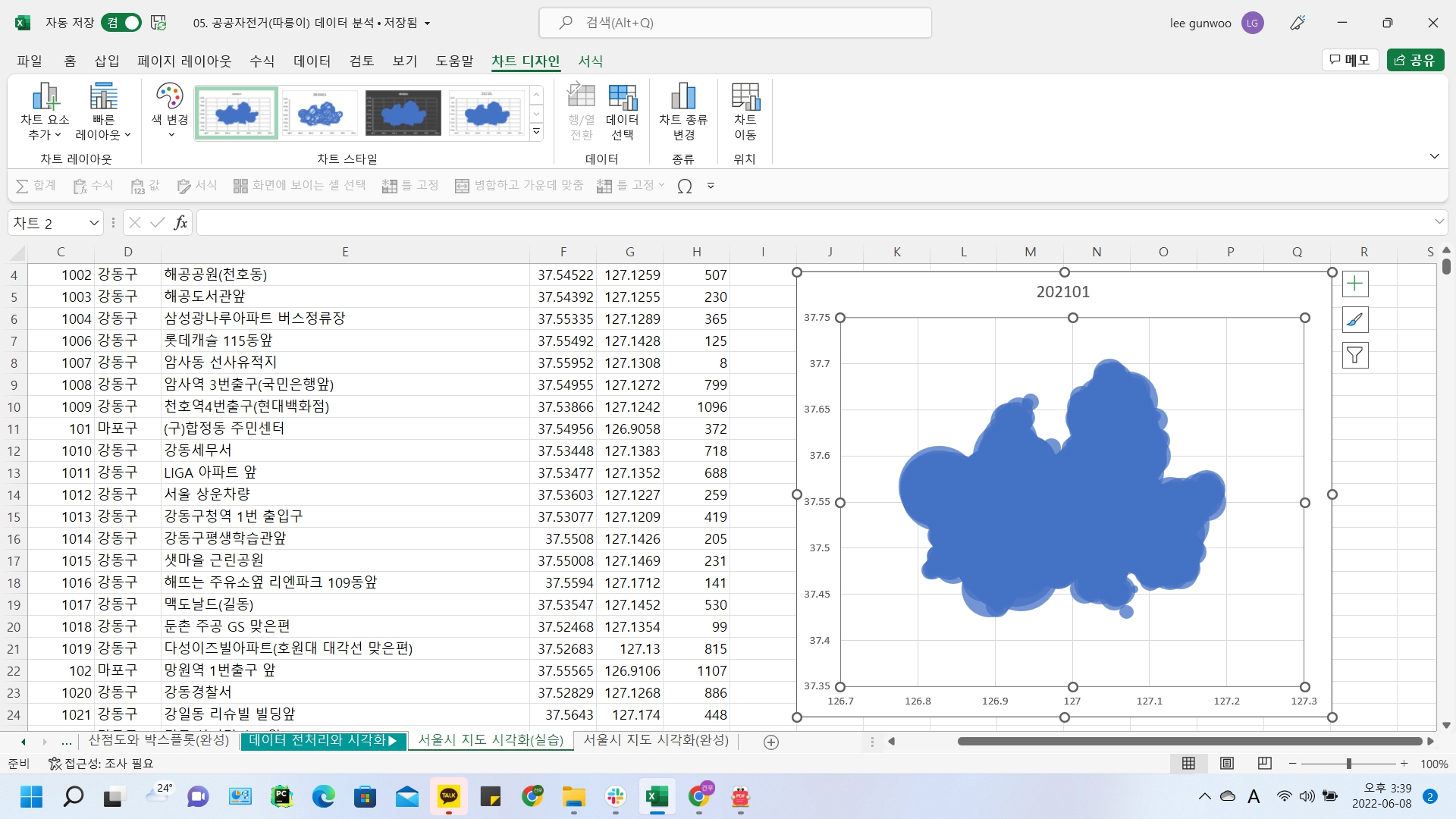
서울시지도에 따릉이 대여량 표현
서울시지도시각화






















Personal Loan 분석
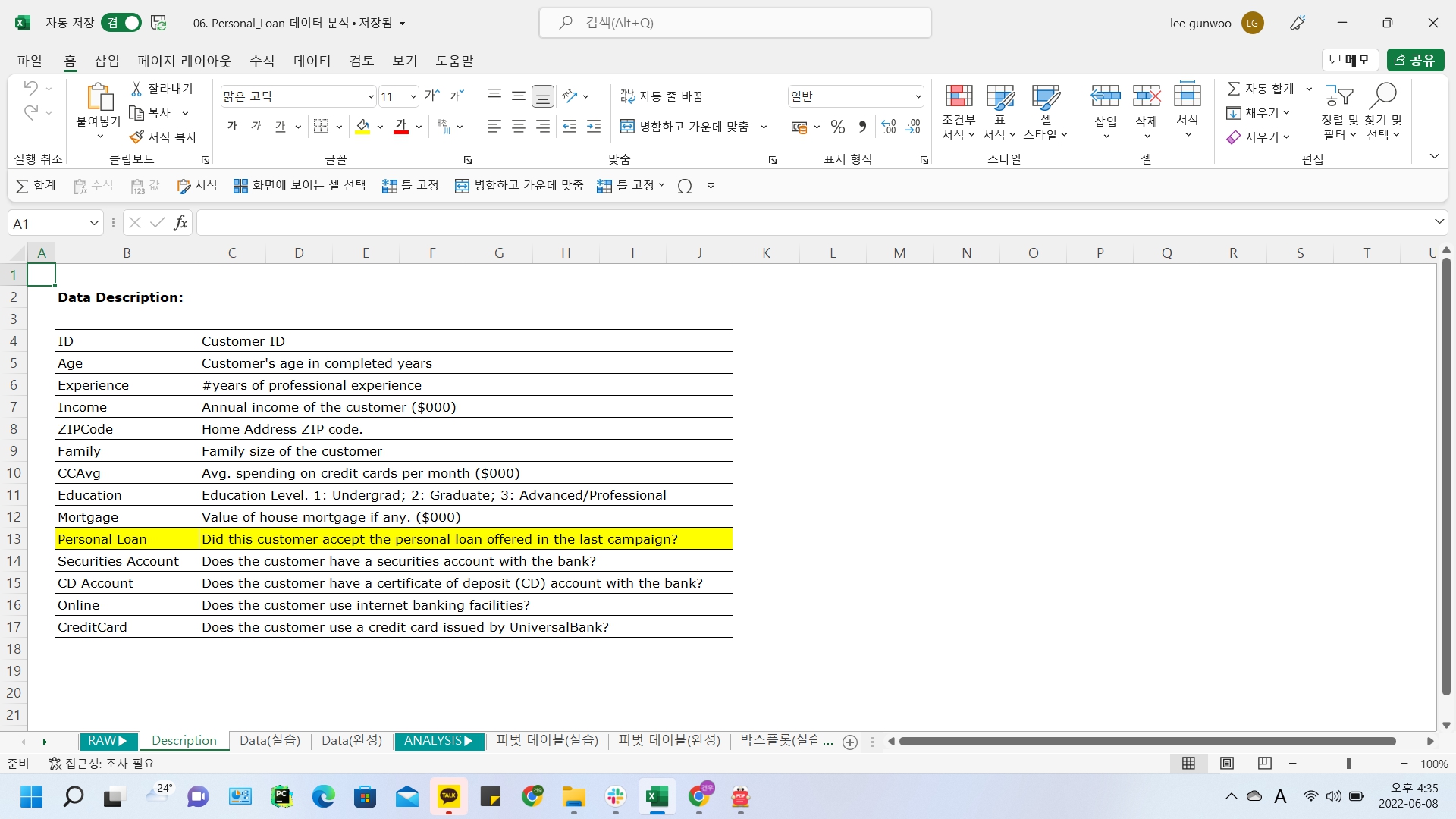
데이터소개

데이터전처리











박스플롯과 산점도그리기









첫번째 개요이름은 (NO)Income, x축은 (NO)Income의 값, y축은 (NO)CCavg값이고 두번째 개요이름은 (YES)Income, x축은 (YES)Income의 값, y축은 (YES)CCavg값이다.
상관분석과 시각화






농수산물 가격 데이터 분석
데이터탐색과 전처리





농수산물 품목별 상관분석





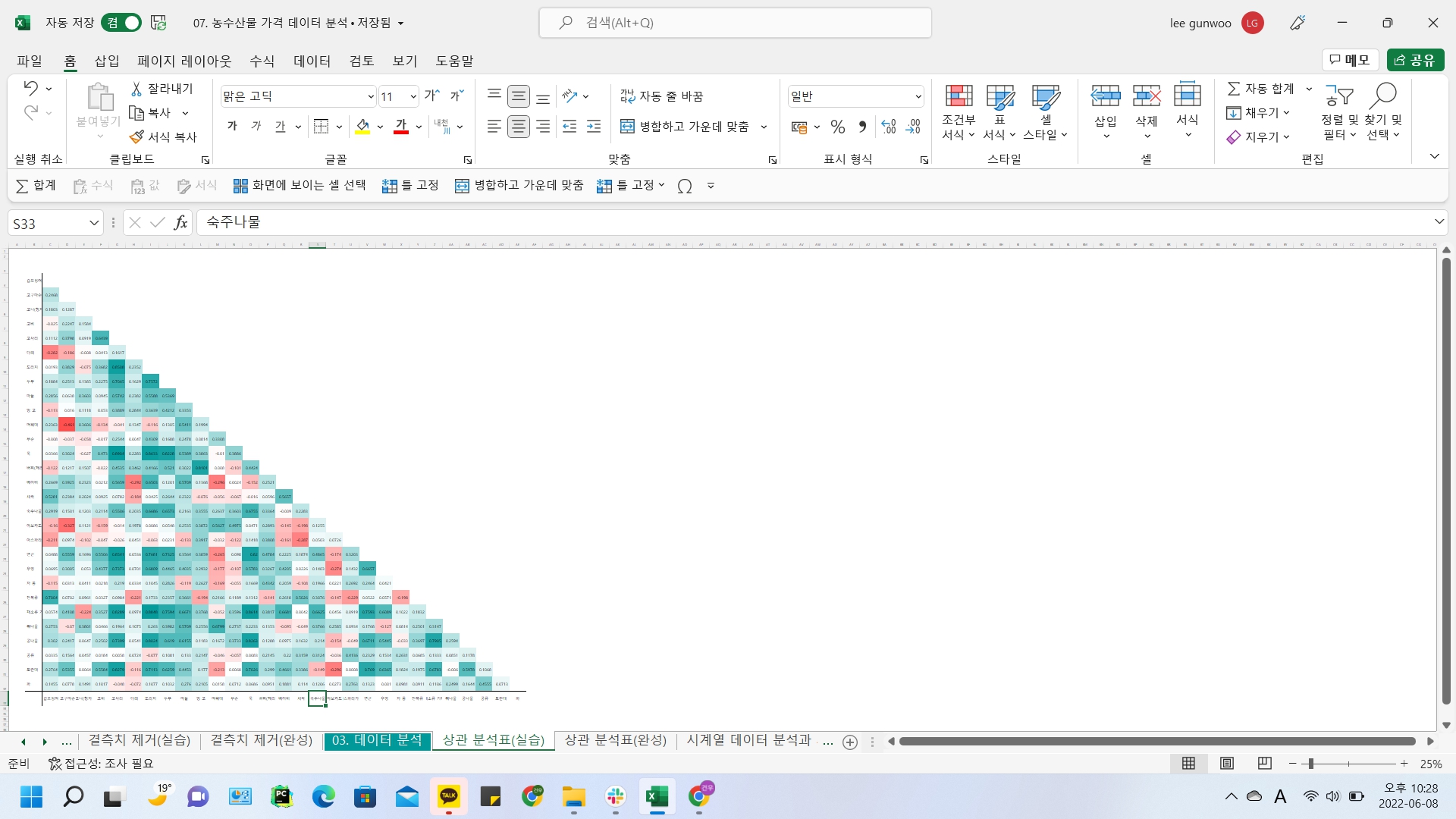
농수산물 미래가격 예측








게임리뷰데이터분석
리뷰데이터에서 키워드발굴












리뷰데이터 키워드분석


























코로나19 확진자 데이터분석
데이터소개와 탐색
데이터전처리
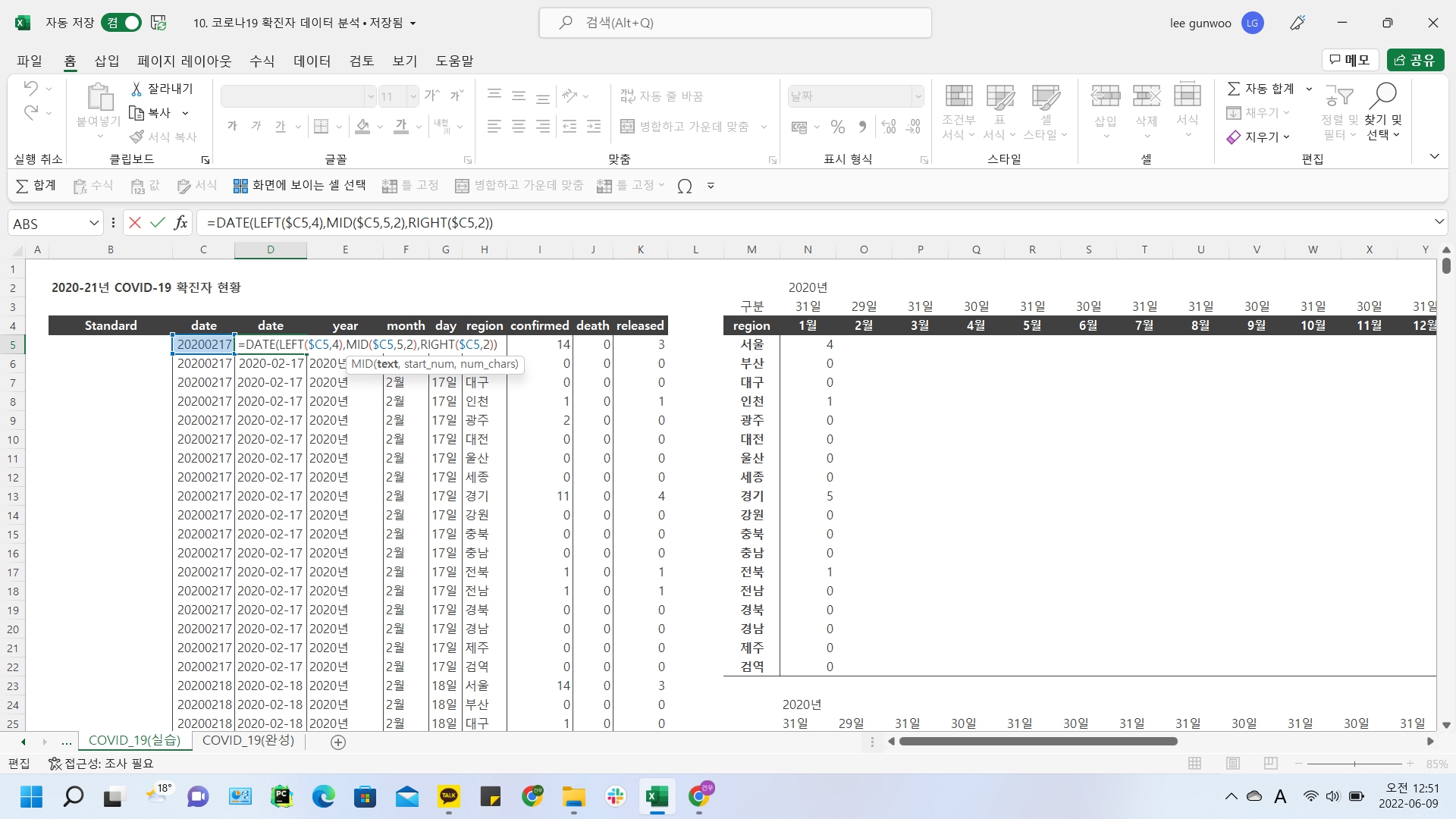







코로나19 확진자지도에 표현하기






KDT(MGS BDA 5기) - 가장 쉽게 시작하는 데이터 분석, SQL 유치원 Online.
오리엔테이션
MySQL을 언어로 하며 Workbench툴을 사용하고 8.0.27버전으로 Windows기준이다.
(단, 8.0버전이하에서는 일부 함수가 작동되지 않을 수 있다.)
데이터,데이터베이스 그리고 DBMS
데이터의 정의는 (네이버, 구글)국어사전 및 백과사전 참조하며 컴퓨터가 처리할 수 있는 문자, 숫자, 소리, 그림 등의 형태로 된 정보이다.
데이터베이스는 데이터저장소로 불리며 여러사람이 공유하고 사용할 목적으로 통합관리도며 이 기능을 제공하는 프로그램은 DBMS이다.
데이터베이스의 특징
- 자료를 구조화해서 저장하기에 효율적 관리가능
- 여러 업무에서 여러 사용자가 동시에 사용가능
- 사용자가 데이터베이스의 기능을 사용하려면 응용프로그램 활용 필요
데이터베이스 언어와 SQL은...
데이터베이스와 대화하기 위해 사용하는언어
데이터베이스와 대화하기 위해 사용하는 약속의 언어
Structured Query Language의 약자
예)
사용자가 직원목록을 보여달라고 하면 데이터베이스언어SQL로 DBMS에 전달하고 데이터베이스를 거쳐 다시 DBMS로 재전달하고 실행결과를 사용자에게 보여준다.
쿼리는 SQL로 쓰인 데이터베이스에 명령을 내리는 문장으로 정의한다.
MySQL, MySQL Workbench설치 및 구성(window기준)


실습 환경 설정 | One-day SQL
보통 직장인에게 꼭 필요한 것만 간단히 하루만에 배우는 SQL
dataartproject.com
위의 하이퍼링크에 접속해서 매뉴얼을 준수하면서 설치해준다.
데이터베이스다루기
데이터 종류
많이 사용하는 MySQL데이터타입
| 숫자형 | 정수형 | 예)1127 |
| 실수형 | 예)0.1127 | |
| 문자형 | 예)문자형 | |
| 날짜형 | 예)1990-11-27 | |
데이터타입을 알아야 하는 이유
MySQL에서 데이터를 저장하기 전에 저장공간의 데이터타입을 미리 지정해야 합니다.
저장공간에는 날짜형, 문자형, 숫자형데이터이다.
만약 MySQL에서 해당저장공간에서 미리 정한 데이터타입이 아닐 경우 저장 불가능합니다.
예)
123-->> 숫자형데이터저장공간 <<-- "ABC"면 ERROR!
숫자형 데이터타입
정수형
| 데이터타입 | 바이트수 | 표현가능한 숫자범위 |
| TINYINT | 1 | -128~127 |
| SMALLINT | 2 | -32,768~32,767 |
| MEDIUMINT | 3 | 약-838백만~838백만 |
| INT | 4 | 약-21억~+21억 |
| BIGINT | 8 | 약-900경~+900경 |
실수형
| FLOAT | 4 | 소숫점 아래 7자리까지 |
| DOUBLE | 8 | 소숫점 아래 15자리까지 |
예)
100--->>> TINYINT저장공간 <<<--- 300이면 ERROR!
문자형 데이터타입
문자형
| 데이터타입 | 최대 바이트수 | 특징 |
| CHAR(n) | 255 | n을 1부터 255까지 지정, 만약 안할 시 1 자동입력하며 고정길이로 정해진만큼 문자열 저장 예) CHAR(5)에 "ABC"저장 A|B|C| | | |
| VARCHAR(n) | 65535 | n을 1부터 65535까지 지정, 만약 안할 시 사용불가하며 변동길이로 필요한만큼 문자열 저장 예) VARCHAR(5)에 "ABC"저장 A|B|C|x|x |
| 데이터타입 | 바이트수 | 표현가능 범위 |
| TINYTEXT | 255 | 255바이트의 문자열까지 표현가능 |
| TEXT | 65535 | 65535바이트의 문자열까지 표현가능 |
| MEDIUMTEXT | 약 1600만 | 약 1600만바이트의 문자열까지 표현가능 |
| LONGTEXT | 약 42억 | 약 42억바이트의 문자열까지 표현가능 |
날짜형
| DATE | 3 | 0000-00-00 ~ 9999-12-31 |
| DATETIME | 3 | 0000-00-00 00:00:00 ~ 9999-12-31 23:59:59 |
| TIME | 4 | -838:59:59~838:59:59 |
| YEAR | 1 | 1901~2155 |
테이블? 데이터베이스에서 데이터를 형태로 정해 모아놓은 저장공간으로 행과 열로 이루어진 데이터표
| 테이블 | ||
| 컬럼1 | 컬럼2 | 컬럼3 |
| 값 | 값 | 값 |
| 값 | 값 | 값 |
| 값 | 값 | 값 |
컬럼(열)은 데이터를 저장하기 위한 틀(연회색에 세로로 4칸)
- 컬럼의 이름과 데이터타입은 테이블을 만들 때 미리 정해짐
- 컬럼의 이름은 동일한 테이블 안에서 중복X
- 테이블은 1개 이상의 컬럼이 필수
값은 컬럼에 속한 실제 데이터값으로 컬럼의 데이터타입만 값으로 가짐
로우(행)은 관계된 값의 리스트(값만 3개 포함하며 가로로 3칸)
- 하나의 행은 하나의 관계된 데이터인데 예를 들어, 하나의 행이 한사람의 데이터이다.
- 같은 테이블 안의 행은 항상 동일한 구조이다.
- 행을 단위로 데이터를 삽입
데이터삽입, 삭제, 수정
쿼리문법
INSERT INTO [테이블이름] ([컬럼1 이름], [컬럼2 이름], [컬럼3 이름]);
VALUES ([컬럼1 값], [컬럼2 값], [컬럼3 값]); # ()에는 로우(행)이 된다.
# 컬럼이 3개라고 가정한 것으로 더 있다면 이어서 적기
INSERT INTO와 VALUES의 리스트갯수는 반드시 일치해야 한다. 불일치하면 에러발생
예) INSERT INTO table (name, age,group);
VALUES ("이건우", "33", "구직자");
DELETE FROM [테이블 이름] WHERE [조건 값];
UPDATE [테이블 이름] SET [컬럼 이름] = [새 값] WHERE [조건 값];
테이블 만들고 데이터넣기 실습(CREATE, INSERT)
데이터셋: Complete Pokemon Pokedex
문제1. pokemon 데이터베이스와 mypokemon 테이블을 만들고, 캐터피, 피카츄, 이브이의 포켓몬번호, 영문이름, 데이터타입 넣기 - 쿼리순서는 1STEP당 1개의 쿼리를 만들기
- 포켓몬 데이터베이스(데이터베이스 이름: pokemon)를 만들고 그 안에 나의 포켓몬 테이블 만들기(테이블 이름: (mypokemon) 이 때 컬럼은 번호, 영문이름, 타입 등 3가지로 하고, 이름과 데이터타입을 지정하기 컬럼이름 및 데이터타입: number:INT, name: VARCHAR(20), type: VARCHAR(10)
- 포켓몬 테이블 안에 포켓몬데이터를 각각 로우(행)로 넣기


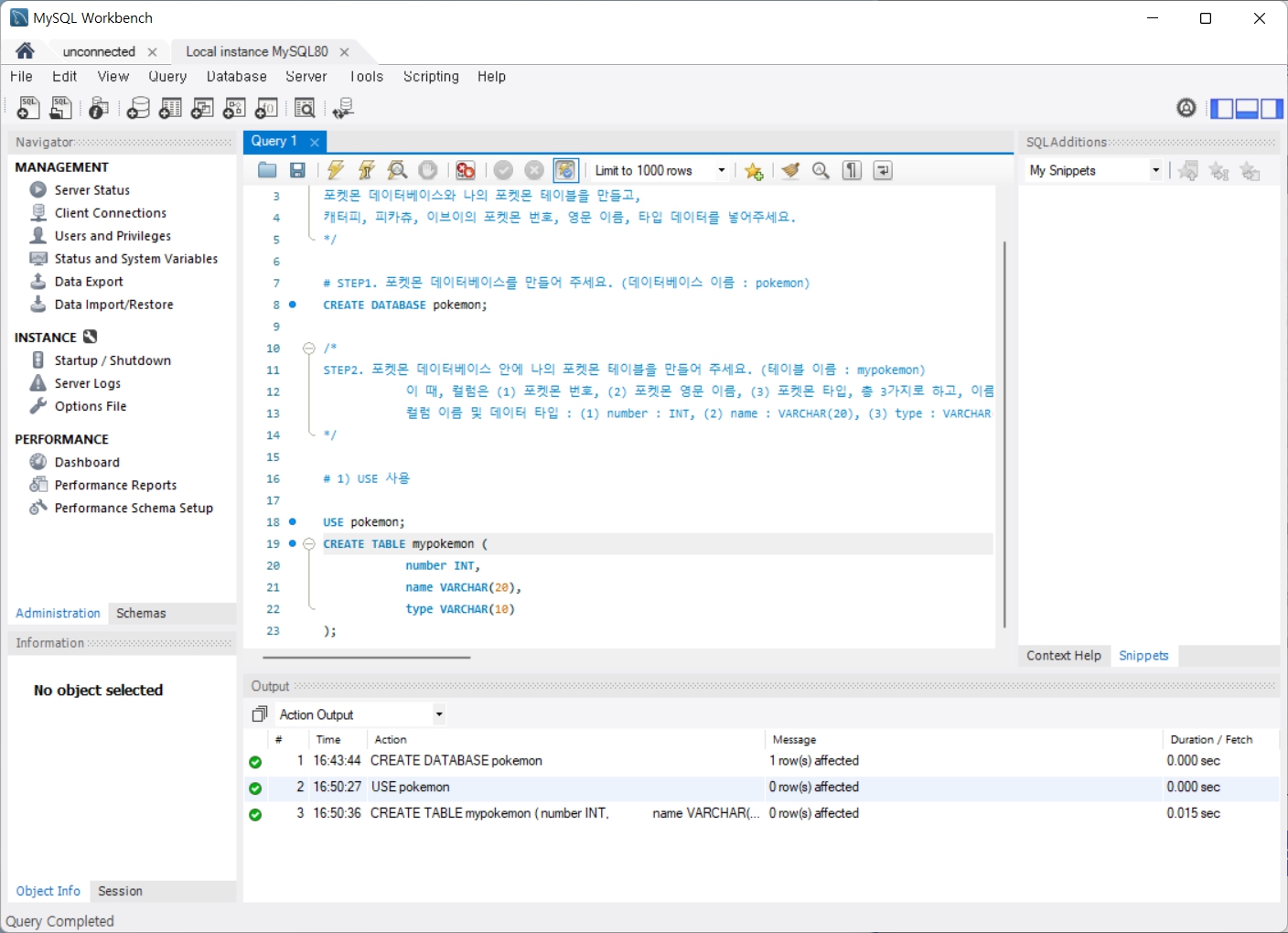


문제2. 문제1에서 만든 pokemon 데이터베이스와 mypokemon 테이블을 만들고, 포니타, 메타몽, 뮤의 포켓몬번호, 영문이름, 데이터타입 넣기 - 쿼리순서는 1STEP당 1개의 쿼리를 만들기
- 포켓몬 데이터베이스(데이터베이스 이름: pokemon) 안에 나의 포켓몬 테이블 만들기(테이블 이름: mypokemon) 이 때 컬럼은 번호, 영문이름, 타입 등 3가지로 하고, 이름과 데이터타입을 지정하기 컬럼이름 및 데이터타입은 문제1과 동일하다.
- 포켓몬 테이블 안에 포켓몬데이터를 각각 로우(행)로 넣기


테이블을 변경하고 지워보기 실습(ALTER, DROP)
문제1. pokemon 데이터베이스 안에 mypokemon 테이블과 mynewpokemon 테이블과 같이 있도록 변경 단, 기존의 테이블에서 변경하므로 테이블은 새로 생성하지 않는다. 쿼리순서는 종전의 문제1과 동일
- mypokemon테이블의 이름을 myoldpokemon으로 변경
- myoldpokemon테이블의 name컬럼의 이름을 eng_nm으로 변경(컬럼이름: eng_nm, 데이터타입: VARCHAR(20))
- mynewpokemon테이블의 name컬럼의 이름을 kor_nm으로 변경(컬럼이름: kor_nm, 데이터타입: VARCHAR(20))


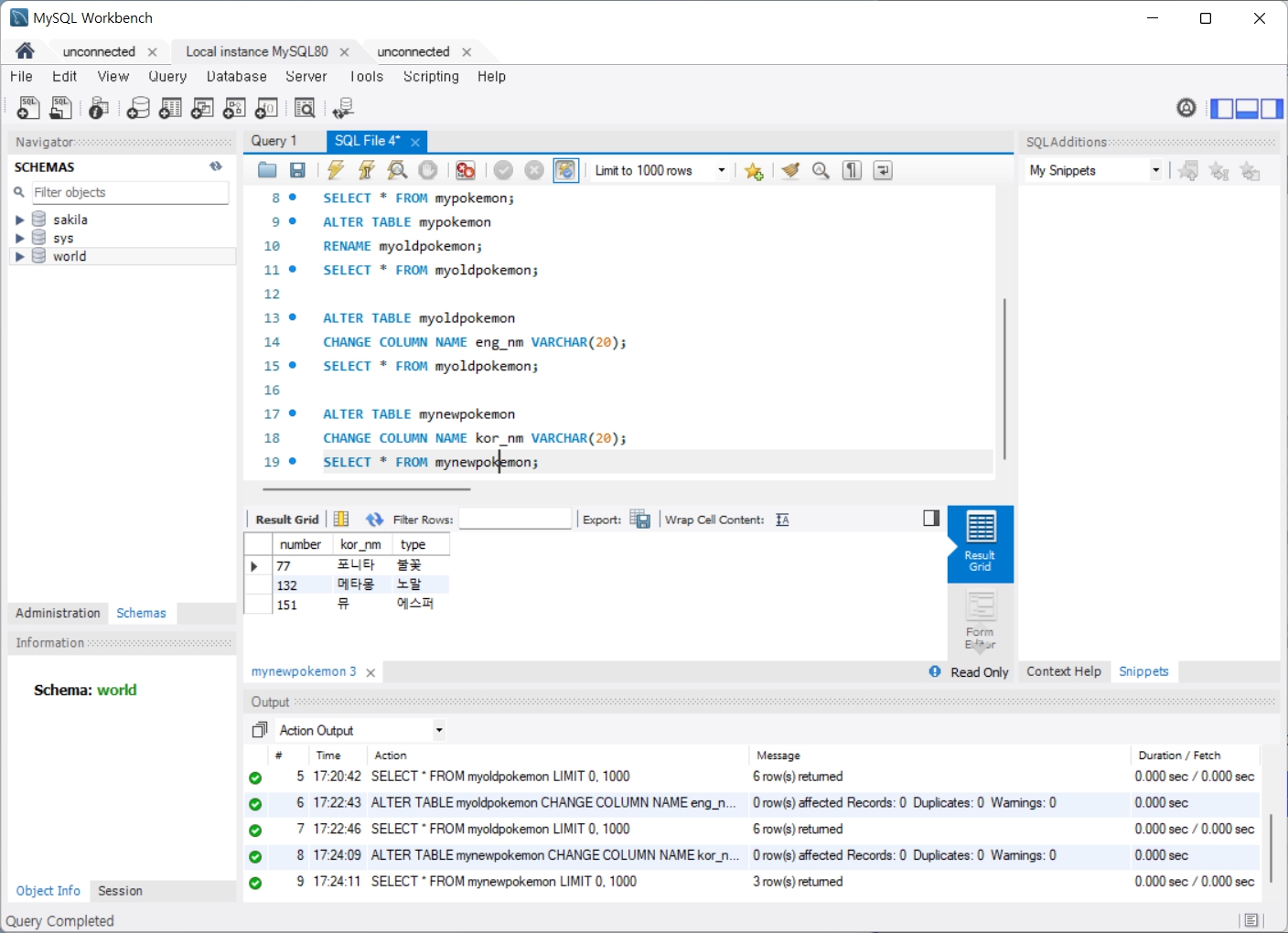
문제2. pokemon 데이터베이스 안에 myoldpokemon 테이블은 값만 지우고, mynewpokemon 테이블은 모두 지우기



데이터 가져오기(SELECT)
가져올 데이터를 선택하거나 값을 가져올 컬럼을 선택하는 키워드 SELECT는 모든 쿼리에 필수적인 키워드
테이블을 먼저 선택해야 컬럼을 선택하는 것이 가능
SELECT 사용예제
SELECT 123; # 결과는 123
SELECT 1+2+3; # 결과는 6
SELECT "ABC"; # 결과는 "ABC"
SELECT 특징
- 숫자, 문자데이터를 가져오며 SELECT 데이터 형식으로 사용
- 컬럼을 선택해서 값을 가져오며 SELECT [컬럼이름] 형식으로 사용
- *(별표)로 컬럼 전체를 가져오며 SELECT * 형식으로 사용하고 컬럼 전체(ALL)를 의미
테이블에서 데이터가져오기
데이터를 가져올 테이블을 지정하는 키워드 FROM
FROM 특징
- FROM[테이블이름]형식으로 사용
- 테이블이 어떤 데이터베이스 안에 있는지 데이터베이스 이름도 함께 명시하되 USE키워드로 사용할 데이터베이스를 지정했다면 생략이 가능하다.
SELECT, FROM 문법 사용예제
컬럼을 하나만 선택한 경우
SELECT [컬럼이름] FROM [데이터베이스 이름].[테이블 이름];
예) SELECT name FROM pokemon.mypokemon;
컬럼을 여러개 선택하는 경우
SELECT [컬럼이름], [컬럼이름], ... [컬럼이름] FROM [데이터베이스 이름].[테이블 이름];
컬럼 전체를 선택하는 경우
SELECT * FROM [데이터베이스 이름].[테이블 이름];
예) SELECT * FROM pokemon.mypokemon;
데이터베이스를 지정하지 않는다면 테이블을 특정할 수 없다.
USE [데이터베이스 이름] SELECT [컬럼이름] FROM [테이블 이름];
별명붙이기
가져온 데이터에 별명을 지정하는 키워드 AS는 컬럼이름에 부가설명을 하거나 불필요한 내용을 제거할 때 사용
- AS [컬럼별명] 형식으로 사용
- 테이블 내의 실제컬럼이름은 불변하며, 별명은 쿼리 내에서만 유효하더라도 실제컬럼이름을 변경하려면, ALTER TABLE구문 사용필요
AS 사용예제
SELECT [컬럼이름] AS [컬럼별명] FROM [테이블 이름];
예) SELECT number AS national_number FROM pokemon.mypokemon; # 테이블 상의 실제컬럼이름은 불변
데이터 일부만 가져오기
가져올 데이터의 로우(행)의 개수를 지정하는 키워드 LIMIT는 데이터의 일부만 확인할 때 사용
- LIMIT [로우 수] 형식으로 사용
- 쿼리의 가장 마지막에 위치하며 만약 입력한 숫자가 전체 로우(행)수보다 크면, 있는 로우(행)까지만 가져오기
LIMIT 사용예제
예) SELECT number.name FROM pokemon.mypokemon LIMIT 2;
중복 제거하기
중복된 데이터는 제외하고 같은 값 한번만 가져오는 키워드 DISTINCT는 컬럼에 어떤 값들이 있는지 확인할 때 사용
- DISTINCT [컬럼이름]형식으로 사용
- SELECT 절에 위치하여 컬럼의 유일한 값들을 가져오기
DISTINCT사용예제
예) SELECT DISTINCT type FROM pokemon.mypokemon;
테이블에서 데이터를 가져오기 실습 (SELECT, FROM)
문제1. 123 곱하기 456을 가져오기
(힌트) MySQL에서 곱하기는 *로 표현(숫자*숫자)

문제2. 2310 나누기 30을 가져오기
(힌트) MySQL에서 나누기는 /로 표현(숫자/숫자)

문제3. '피카츄'라는 문자열을 '포켓몬'이라는 이름의 컬럼별명으로 가져오기

문제4. 포켓몬테이블에서 모든 포켓몬들의 컬럼과 값 전체를 가져오기
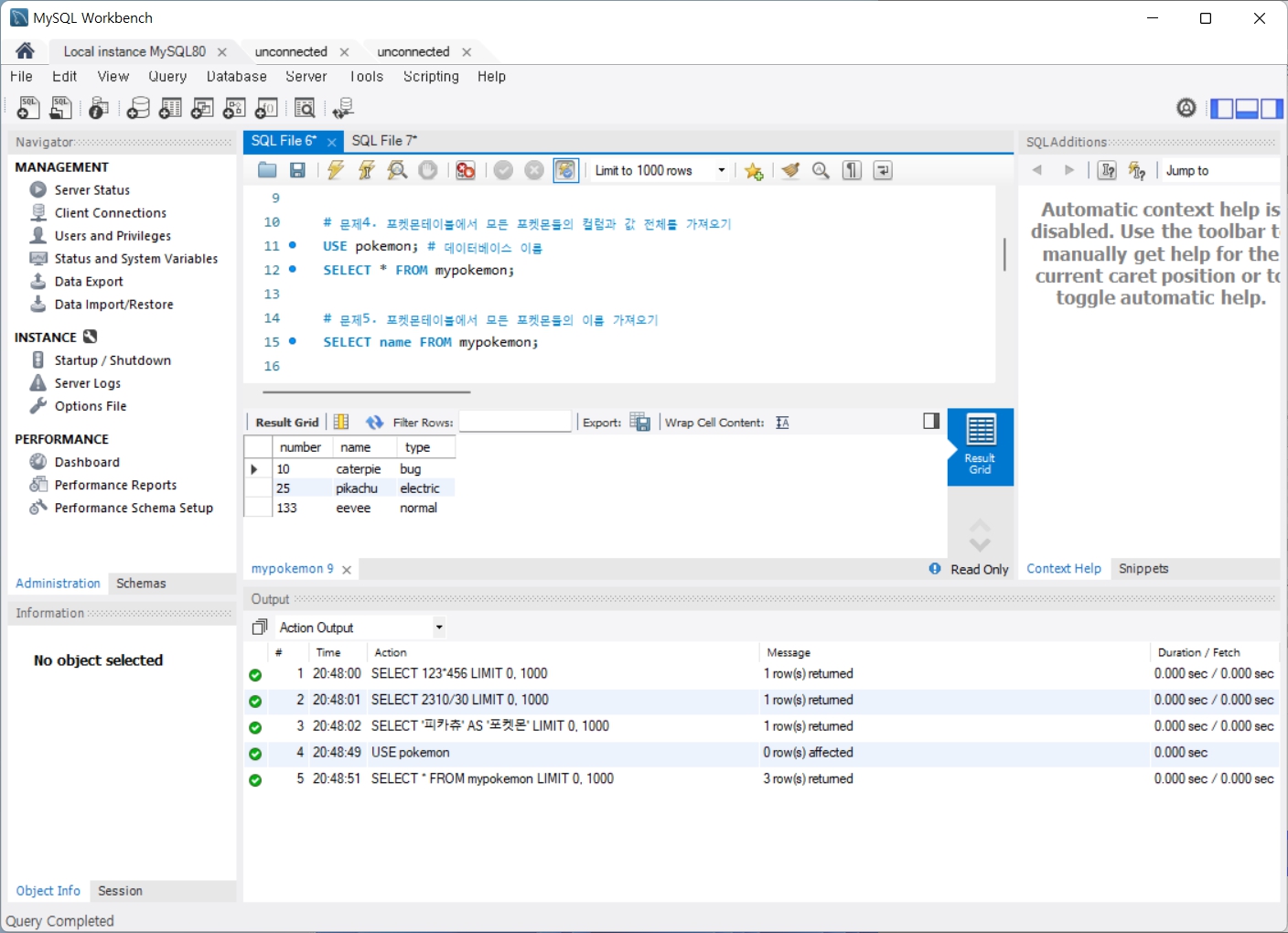
문제5. 포켓몬테이블에서 모든 포켓몬들의 이름 가져오기

문제6. 포켓몬테이블에서 모든 포켓몬들의 이름과 키, 몸무게를 가져오기

문제7. 포켓몬테이블에서 포켓몬들의 키를 중복제거하고 가져오기
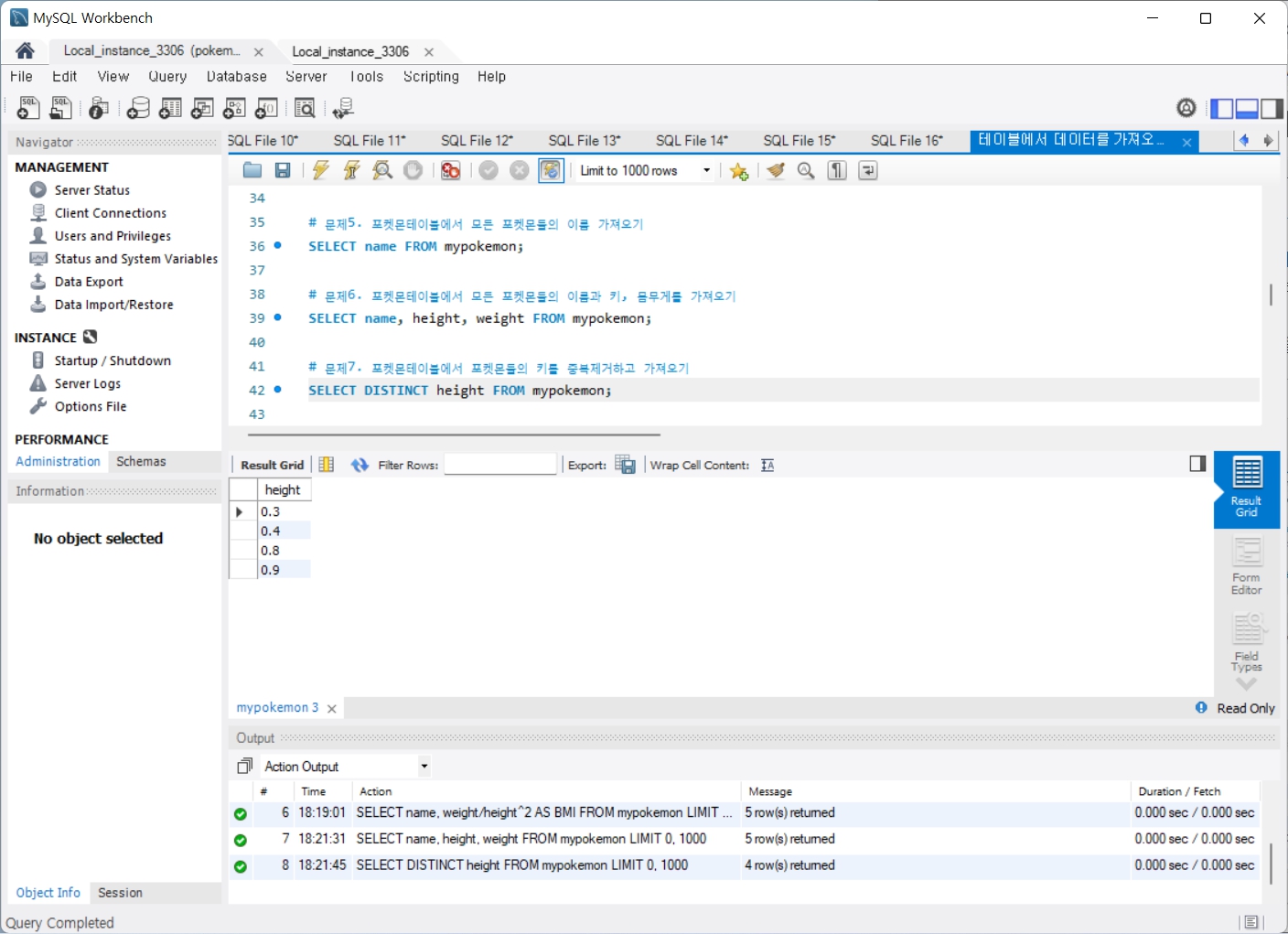
문제8. 포켓몬테이블에서 모든 포켓몬들의 공격력을 2배로 설정해 'attack2'라는 별명으로 이름과 함께 가져오기
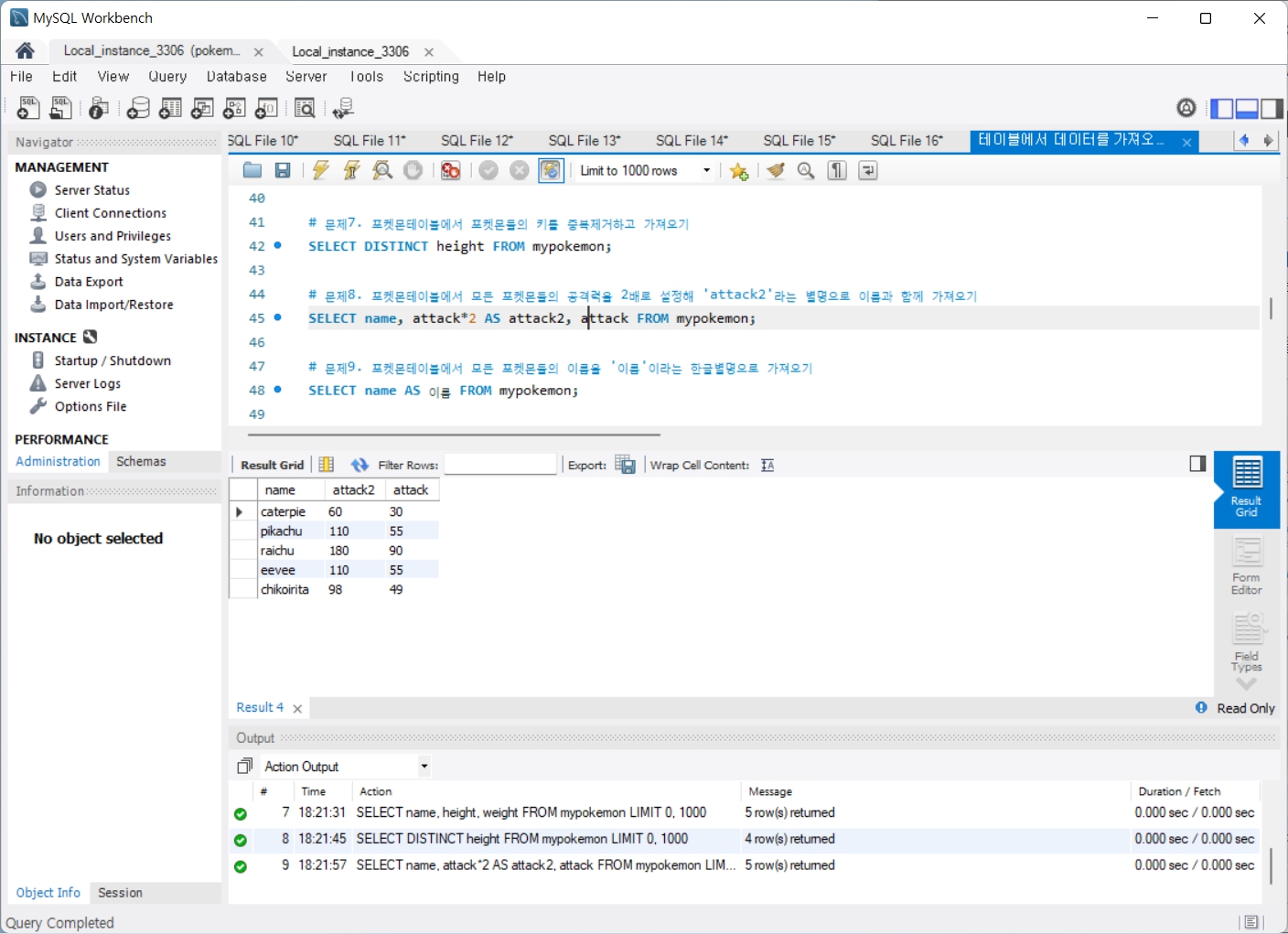
문제9. 포켓몬테이블에서 모든 포켓몬들의 이름을 '이름'이라는 한글별명으로 가져오기

문제10. 포켓몬테이블에서 모든 포켓몬들의 공격력은 '공격력'이라는 한글별명으로, 방어력은 '방어력'이라는 한글별명으로 가져오기

문제11. 현재 포켓몬테이블의 키 컬럼은 m단위입니다. (1m=100cm)
포켓몬테이블에서 모든 포켓몬들의 키를 cm단위로 환산하여 'height(cm)'라는 별명으로 가져오기
(힌트) 쿼리 내 이름에 괄호'(,)'가 있을 경우 괄호가 쿼리의 한 부분을 의미하는지 이름을 의미하는지 인지가 어려워, 따옴표('',"")로 감싸 의미를 분명하게 하기
단, FLOAT데이터타입은 입력값의 근사치를 저장하기에 소수점이 나오는 게 정상이다.

문제12. 포켓몬테이블에서 첫번째 로우에 위치한 포켓몬데이터만 컬럼 값 전체를 가져오기

문제13. 포켓몬테이블에서 2개의 포켓몬데이터만 이름은 '영문명'이라는 별명으로, 키는 '키(m)'라는 별명으로, 몸무게는 '몸무게(kg)'이라는 별명으로 가져오기
(힌트) 쿼리 내 이름에 괄호'(,)'가 있을 경우 괄호가 쿼리의 한 부분을 의미하는지 이름을 의미하는지 인지가 어려워, 따옴표('',"")로 감싸 의미를 분명하게 하기

문제14. 포켓몬테이블에서 모든 포켓몬들의 이름과 능력치의 합을 가져오고, 이 때 능력치의 합은 'total'이라는 별명으로 가져온다. 추가조건은 능력치의 합은 공격력, 방어력, 속도의 합을 의미한다.

문제15. 포켓몬테이블에서 모든 포켓몬들의 BMI지수를 구해서 'BMI'라는 별명으로 가져오기
이 때, 포켓몬을 구분하기 위해 이름도 함께 가져오기
조건1. BMI지수 = 몸무게(kg) / (키(m)//2)
조건2. 포켓몬테이블데이터의 체중은 kg단위, 키는 m단위입니다.
(힌트) MySQL에서 제곱은 ^로 표현합니다.(예시: 10//2는 10^2로 표현합니다.)
단, FLOAT데이터타입은 입력값의 근사치를 저장하기에 소수점이 나오는 게 정상이다.

[포켓몬정보표]
| mypokemon | ||||||||
| number: 포켓몬번호 name: 포켓몬이름 type: 포켓몬타입 height: 키(m) weight: 몸무게(kg) attack: 공격력 defense: 방어력 speed: 속도 |
number | name | type | height | weight | attack | defense | speed |
| 10 | caterpie | bug | 0.3 | 2.9 | 30 | 35 | 45 | |
| 25 | pikachu | electric | 0.4 | 6 | 55 | 40 | 90 | |
| 26 | raichu | electric | 0.8 | 30 | 90 | 55 | 110 | |
| 133 | eevee | normal | 0.3 | 6.5 | 55 | 50 | 55 | |
| 152 | chikorita | grass | 0.9 | 6.4 | 49 | 65 | 45 | |
'데이터분석_워크시트' 카테고리의 다른 글
| BDA 5기_워크시트_이건우_220707 (0) | 2022.07.01 |
|---|---|
| BDA 5기_워크시트_이건우_220630 (0) | 2022.06.24 |
| BDA 5기_워크시트_이건우_220623 (0) | 2022.06.17 |
| BDA 5기_워크시트_이건우_220616 (0) | 2022.06.10 |
| BDA 5기_워크시트_이건우_220602 (0) | 2022.06.03 |



