
패스트캠퍼스_비즈니스_빅데이터_분석가_양성과정_5기_이건우
BDA 5기_워크시트_이건우_220623 본문
4주차 온라인강의 학습범위(클립번호 합산기준): SQLD1~29, Business Analyst를 위한 핵심SQL실전특강, 파이썬(실전)1~30(220617~220623)
데이터베이스와 SQLD 합격패스 Online.
데이터베이스
- 컴퓨터시스템에 전자적으로 저장된 체계적 데이터의 모음
- 컴퓨터가 초기 발명된 시점에는 과학적인 연구용도(수학적계산)로 사용
- 컴퓨터과학이 발전하면서 대용량의 데이터를 저장하고 조회하는 요구가 증대
- 이런 배경에서 데이터베이스 개념이 도입
데이터베이스 사용이전의 일반적인 텍스트 파일
| first name, last name, phone John, Doe (408)-245-2345 John, Doe (508)-234-2355 |
- 데이터베이스 발명 이전에 데이터는 텍스트파일형태로 저장 및 관리됨
- 파일형태는 여라사용자가 동시에 공유하기 어렵다.
- 파일을 서로 주고받으며 데이터의 유실가능성이 항상 존재함.
모든것이 데이터베이스로 관리되는 시대(모든 것이 데이터로 관리되기 전)
- 현재는 모든 것이 데이터베이스로 관리
- 주소록, 직원관리, 매출관리, 쇼핑몰, 영화예매, 은행, 증권, 대학, 병원, 공공기관 등
- 텍스트, 그림, 동영상, 파일 등 모든 데이터가 데이터베이스로 관리
데이터베이스 관리시스템(database management system, DBMS)
다수의 사용자들이 데이터베이스 내의 데이터를 접근할 수 있도록 하는 소프트웨어 도구의 집합
DBMS는 사용자 또는 다른 프로그램의 요구를 처리하고 적절히 응답하여 데이터를 사용할 수 있도록 함.
데이터베이스시스템 구성
| 다수의 사용자 OOOOOOOOOOOOOOOOOOO |
DBMS(시스템 소프트웨어) ORACLE데이터베이스, MySQL 등 |
데이터베이스 |
데이터베이스 시스템의 특징
| 특징 | 설명 |
| 실시간 접근성 (real time accessibility) |
데이터베이스는 실시간으로 서비스된다. 사용자가 데이터를 요청하면 몇시간이나 몇 일 뒤에 결과를 전송하는 것이 아니라 수 초 내에 결과를 서비스한다. |
| 계속적인 변화 (continuous change) |
데이터베이스에 저장된 내용은 어느 한순간의 상태를 나타내지만, 데이터값은 시간에 따라 항상 변화 - 데이터베이스는 삽입, 삭제, 수정 등의 작업을 통하여 바뀐 데이터 값을 저장 |
| 동시 공유 (concurrent sharing) |
데이터베이스는 서로 다른 업무 또는 여러사용자에게 동시에 공유 동시(concurrent)는 병행이라고도 하며, 데이터베이스에 접근하는 프로그램이 여러 개 있다는 의미 |
| 내용에 따른 참조 (reference by content) |
데이터베이스에 저장된 데이터는 데이터의 물리적인 위치가 아니라 데이터 값에 따라 참조 |
데이터베이스의 기본기능?
데이터삽입, 삭제, 수정, 조회기능
| 조회 | 원하는 데이터를 조회하는 기능(ex. 영화시간표 조회) |
갱신 →→ 원하는 데이터를 저장하는 기능(ex. 영화예매)
↘→ 원하는 데이터를 삭제하는 기능(ex. 영화예매 취소)
↘→ 원하는 데이터를 수정하는 기능(ex. 영화좌석 변경)
영화예매시스템은 데이터의 삽입, 삭제, 수정, 조회기능을 모두 구현해야 운영이 가능함
동시성제어
| A | B |
| A는 강남역CGV 1관에서 2020년 4월 26일 20:30분 에 시작하는 영화의 A2 좌석을 선택 후 결제를 진행하고 있는 하는 상태 | B는 강남역CGV 1관에서 2020년 4월 26일 20:30분 에 시작하는 영화를 예매 시 A2 좌석은 선택할 수 없음 |
동시성제어의 중요성
- 데이터베이스의 동시성 제어가 보장 되지 않는다면 A2좌석에 대한 결제가 동시에 이루어 질 수 있음
- 만약 이수지와 이경오 모두 같은 영화관, 같은 시간, 같은 영화, 같은 좌석을 예매한다면 해당 좌석은 두 사람 중 그 누구의 좌석도 아닌 좌석이 됨
- 영화관은 대혼란을 맞이함
- 데이터베이스의 동시성은 한 기업의 비즈니스 성패를 좌우할 수 있을 정도로 중요함
장애대응기능
- 데이터베이스는 데이터손실이 발생한 경우 복원이 가능해야 함
- 데이터의 보호와 장애에 대한 방안이 있어야 함
보안기능
| 개인용컴퓨터 | >>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 보안에 위배되지 않는 데이터 조회 >>>> >>>>>>>>>>>>>>>>>>>>>>>>>>>>>> |
데이터베이스 서버 |
| 휴대폰 | ||
| 태블릿 |
- 데이터베이스의 보안기능은 사용자에게 보여줄 데이터만 보여주는 것
- 보안에 위배되는 데이터는 데이터베이스 서버 내에서 관리
- 사용자는 데이터베이스 내부를 알 필요가 없고 자신이 원하는 정보처리만을 수행
- 개인 정보의 유출 등은 매우 심각한 사회문제가 되므로 데이터의 보안이 중요함
데이터베이스의 종류
데이터저장방식에 따른 종류
| 종류명 | 설명 |
| 계층형 데이터베이스 | 계층 구조로 데이터 관리, 최초의 현대적 데이터베이스 |
| 관계형 데이터베이스 | 2차원 표 형식으로 데이터 관리, 가장 널리 사용됨 |
| 객체지향형 데이터베이스 | 아직 널리 사용되지 않음 |
| NOSQL 데이터베이스 | Not Only SQL, 최근에 각광을 받고 있음, 관계형 데이터베이스 기능 일부 삭제 |
관계형 데이터베이스 의 제품종류(=DBMS시스템의 제품종류)
ORACLE DATABASE, IBM DB2, MicrosoftSQL Server, PostgreSQL, TIBERO DataBase, CUBRID
데이터베이스시스템 세계순위는 아래링크 참조
https://db-engines.com/en/ranking
DB-Engines Ranking
Popularity ranking of database management systems.
db-engines.com
오라클 데이터베이스는 독보적인 관계형 데이터베이스로 알려져 있었다. 그렇게 해서 해당 강의의 모든 실습은 오라클 데이터베이스 내에서 진행하는 것으로 보임.
관계형 데이터베이스(Relational Database)
- 키(key)와 값(value)들의 간단한 관계를 테이블화한 매우 간단한 원칙의 전산정보 데이터베이스로 보통 RDB라고 함
- 2차원표를 이용한 데이터 목록화 관리를 하는 것이 주 목적임(Excel, Google 스프레드 시트)
- 실세계를 그대로 반영함으로 직관적인 이해가 가능함(주소록, 출석부, 가계부 등)
- 우리는 실생활에서 사용하는 모든정보를 관계형 데이터베이스로 관리할 수 있음
관계형모델
- 관계형 모델(relational model)은 집합론에 기반을 둔 일종의 데이터베이스 모델로 에드거 커드(Edgar Codd)에 의해 최초로 제안되고 체계화되었음
- 컬럼(열)과 로우(행)를 이루는 하나 이상의 테이블이 존재하고 테이블에 데이터가 저장됨
- 각각의 테이블은 각각의 로우를 식별하는 기본 키(Primary Key)가 있음
- 컬럼은 필드(Field) 혹은 속성(Attribute) 라고도 불림, 로우는 레코드 혹은 튜플(Tuple)로 불림
고객연락처 테이블
↓ 열, 필드, 속성
| 순번 | 고객아이디 | 고객명 | 연락처구분 | 연락처 | |
| 1 | gwl1 | ABC | 이메일 | OOOOOOOOOOOOOO@naver.com | |
| 2 | gwl1 | ABC | 휴대폰 | 010-OO12-OO34 | |
| 3 | gwl2 | DEF | 이메일 | OOOOOOOOOOOOOO@naver.com | <<< 행, 튜플, 레코드 |
| 4 | gwl2 | DEF | 휴대폰 | 010-OO56-OO78 | |
| 5 | gwl3 | GHI | 이메일 | OOOOOOOOOOOOOO@naver.com | |
| 6 | gwl3 | GHI | 휴대폰 | 010-OO90-OO12 |
컴퓨터 과학에서, 튜플은 어떤 요소의 집합, 혹은 테이블에서의 행을 가리킨다(레코드와 동일한 의미)
https://ko.wikipedia.org/wiki/%ED%8A%9C%ED%94%8C
관계형데이터베이스의 혁신성
| 특징 | 설명 |
| 역사적 혁신성 | 최초로 2차원 표를 이용한 데이터베이스 소프트웨어 |
| 기능적 혁신성 | 직관적인 방법으로 데이터를 추출할 수 있음 - SQL 언어를 이용한 간편한 데이터 추출 - 데이터베이스 사용자 층의 빠른 증가에 기여 - 개발 및 업무생산성 확대 |
기능적 혁신성
고객의 연락처 중 가운데 고객명 중 "경"자가 들어가는 고객의 이메일 주소는 무엇인가?
| 프로그래밍적인 관점 | SQL 관점 |
| ① "고객 연락처"가 저장되어 있는 파일을 연다. ② 아래와 과정을 전체 라인에 대해 반복한다. "고객명" 항목에 "경"자가 포함되어 있는지 체크 포함되어 있다면 "연락처 구분"이 "이메일" 인지 체크하여 만약 " 이메일"이라면 "연락처" 항목을 화면에 출력한다. ③ "고객 연락처" 파일을 닫는다 |
SELECT 연락처 FROM 고객연락처 WHERE 고객명 LIKE '%경%' AND 연락처구분 = '이메일' |
| - SQL을 이용한 데이터처리는 매우 직관적이고 사용자 편이성을 도모함 |
SQL(Structured Query Language)기초
https://ko.wikipedia.org/wiki/SQL
- 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
- 관계형 데이터베이스 관리 시스템에서 자료의 검색과 관리, 데이터베이스 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안되었다.
- 많은 수의 데이터베이스 관련 프로그램들이 SQL을 표준으로 채택하고 있다.
SQL의 용도
| 사용자 | >>>>>>>>> <<<<<<<<< |
SQL작성 및 명령수행 | >>>>>>>>> <<<<<<<<< |
DBMS (시스템 소프트웨어) |
>>>>>>>>> <<<<<<<<< |
데이터 베이스 |
- 관계형 데이터베이스에서 데이터를 조회 및 갱신하기 위한 언어
SQL의 장점
- 일반 프로그래밍 언어에 비해 간결함
- 모국어 말하는 것처럼 데이터 조회 및 갱신이 가능 즉 간단한 영어 문장을 사용함
- 간단한 기본조작명령어(SELECT, INSERT, UPDATE, DELETE)
테이블, 행, 열
- 관계용 데이터베이스와 SQL의 용어
- SQL의 기초를 학습하는데 있어서 반드시 이해하고 넘어가야 함
| 항목 | 설명 |
| 테이블(TABLE) | 관계형 데이터베이스의 2차원표 데이터 관리하는 유일 단위 테이블설계는 데이터베이스설계의 중요부분 |
| 행(ROW) | 테이블의 가로축 텍스트파일로 치면 한개의 라인이라고 할 수 있음 |
| 열(COLUMN) | 테이블의 세로축 |
행과 열이 교차하는 부분을 셀(CELL)이라고 함
고객연락처테이블 ↓ 열(COLUMN)
| 순번 | 고객아이디 | 고객명 | 연락처구분 | 연락처 | |
| 1 | gwl1 | ABC | 이메일 | OOOOOOOOOOOOOO@naver.com | |
| 2 | gwl1 | ABC | 휴대폰 | 010-OO12-OO34 | |
| 3 | gwl2 | DEF | 이메일 | OOOOOOOOOOOOOO@naver.com | <<< 행(ROW) |
| 4 | gwl2 | DEF | 휴대폰 | 010-OO56-OO78 | |
| 5 | gwl3 | GHI | 이메일 | OOOOOOOOOOOOOO@naver.com | |
| 6 | gwl3 | GHI | 휴대폰 | 010-OO90-OO12 |
SELECT문(고객연락처테이블 참조)
고객의 연락처 중 연락처 구분이 이메일인 행 중에서 이메일형식에 맞지 않는 값이 있는가?
| SELECT * FROM 고객연락처 WHERE 연락처구분 = '이메일' AND 연락처 NOT LIKE '@%' AND 연락처 NOT LIKE '%@' AND 연락처 LIKE '%@%' ; |
INSERT문(고객연락처테이블 참조)
고객의 연락처에 새로운 정보를 입력
| INSERT INTO 고객연락처 (순번, 고객아이디, 고객명, 연락처구분, 연락처) VALUES (7, 'lucky4', '강윤희', '이메일', 'kangyoonhee@naver.com') ; |
UPDATE(고객연락처테이블 참조)
고객의 연락처 중 순번이 1번인 행의 이메일주소를 dbmsexpert7@naver.com 으로 변경
| UPDATE 고객연락처 SET 연락처 = 'dbmsexpert7@naver.com' WHERE 순번 = 1 ; |
DELETE(고객연락처테이블 참조)
고객의 연락처 중 순번이 1번인 행을 삭제
| DELETE FROM 고객연락처 WHERE 순번 = 1 ; |
관계형 데이터베이스 소프트웨어(=DBMS)
- 관계형 데이터베이스를 사용하기 위해서는 DBMS를 설치
- 대표적인 관계형데이터베이스 소프트웨어는 Oracle, MySQL, SQL Server, PostgreSQL 등
데이터베이스와 DBMS의 차이
| 항목 | 특징 |
| 데이터베이스 | 추상적개념 |
| DBMS | 실체적개념 기능 및 구조실현을 위한 구체적 소프트웨어 |
Oracle은 DBMS이고 데이터베이스 자체는 아니다.
| 데이터베이스 | >>>>>>>>>>>>>> 구체화 |
DBMS(Oracle) |
일반적인 IT시스템이 탄생하는 과정
- DBMS와 여러 소프트웨어의 연동으로 IT시스템이 구축됨
- 보통 이러한 과정을 SI(System Integration) 과정이라고 부름
| 사용자 | >>>>>>>>> 네트워크 |
WEB서버 | >>>>>>>>> 네트워크 |
WAS서버 | >>>>>>>>> 네트워크 |
DBMS서버 |
| OS(운영체제) | OS(운영체제) | OS(운영체제) |
- 단 한가지시스템이라도 동작하지 않으면 IT시스템은 장애상황이 될 수 있음
- 중요하지 않은 시스템이 없지만 가장 중요한 한 계층을 꼽자면 DBMS라고 할 수 있음
운영체제의 종류
| 종류 | 특징 |
| Windows | GUI(Graphic User Interface)에 의한 직관적 조작 소비자용 데스크톱에서 가장 널리 사용 |
| Linux, Unix | 비즈니스용으로 주로 사용 IT 시스템의 서버용으로 많이 사용됨 |
| iOS, Android | 모바일용 운영체제임 |
DBMS와 운영체제
DBMS는 다양한 운영체제와의 조합으로 구축가능
- Red hat Linux - Oracle
- AIX Unix - IBM DB2, TIBERO DataBase
- Windows Server - Microsoft SQL Server, MySQL
IT예산, 제품의 기능 및 용도, 개발자와 엔지니어의 기술스펙 등 고려해야할 요소가 많음
DBMS의 마이그레이션
| Oracle | >>> | Oracle | DBMS제품은 동일하고 OS만 바뀌는 경우 - DBMS의 수정이 적음 - 공수가 많이 들지 않음 |
| Red hat Linux | Solaris |
| Oracle | >>> | SQL Server | OS 제품은 동일하고 DBMS만 바뀌는 경우 - DBMS의 관련 작업이 많음 - 보통의 공수가 들어 감 |
| Windows Server | Windows Server |
| Oracle | >>> | TIBERO | OS제품 및 DBMS가 모두 바뀌는 경우 - DBMS의 관련 작업이 많음 - 매우 많은 공수가 들어가고 리스크가 큼 |
| Windows Server | AIX Unix |
애플리케이션(Application)
- 비즈니스처리 기능을 가진 소프트웨어라고 할 수 있음
- 보통의 경우 WAS서버에서 동작함
- 일반적으로 JAVA, C 등의 프로그래밍언어를 이용하여 구현함
- 애플리케이션으로 DBMS에 연동하여 각종 프로그램을 구축함(ex. 영화예매시스템)
애플리케이션의 구현방식
| 방식 | 특징 |
| 직접개발 | - JAVA, C 등의 프로그래밍 언어로 직접 프로그래밍으로 구현 - 개발비용이 매우 높음 - 고객(사용자)의 디테일한 요구사항을 수용 가능 |
| 솔루션 구매 | - 솔루션 등의 기존 소프트웨어를 구매 - 개발비용이 절감되지만 소프트웨어 구매비용이 들어 감 - 고객(사용자)의 디테일한 요구사항 수용불가 - 커스터마이징을 위해서는 추가비용이 들어 감 |
테이블설계
테이블이란?
- 관계형 데이터베이스에서 데이터를 관리 및 저장하는 장소
② 데이터의 효율적인 관리 및 적절한 조작이 매우 중요함
③ 실생활에서 광범위하게 사용되는 2차원 표와 유사함

- 테이블은 현실세계를 반영함
- 개념이나 집합에 대응하는 형식으로 존재
- 완두콩, 토마토, 옥수수 등은 행은 될 수 있어도 집합은 될 수 없음
집합을 나누는 방법
집합을 나누는 방법에 따라 한개 혹은 여러개의 테이블이 될 수 있음
데이터베이스 VS 자바
| 데이터베이스 | 자바 |
| 테이블 | 클래스 |
| 열 | 속성 |
| 행 | 인스턴스 |
| - | 메소드 |
기본키의 중요성
- 기본키는 특정 집합에서 특정 행을 유일하게 식별할 수 있는 속성의 집합(EX. 학번, 카드발급번호, 주민등록순번)
- 현실 세계에 2명의 같은 사람은 없다, 기본키는 중복되면 안된다. 기본키의 값은 한번 정해지면 가급적 변경 안됨
- 반드시 기본키를 설정해야 함(한 개 테이블 내에서 중복 행은 허용하지 않음), 기본키는 NULL값 허용 안됨
- 단, 업무상의 이유로 기본키가 없는 테이블이 운영되는 곳도 있음
| 회원명 | 나이 | 성별 | 회원구분 |
↓
정규형
- 테이블을 정의하는 기본형태
- 즉, 제대로 된 형태를 뜻함 -> 테이블 갱신시 부정합이 발생하기 어려운 형태
- 정규형을 제대로 지키는 행위를 정규화 위반이라고 부름 -> 정규화가 제대로 되지 않아 관리의 어려움을 겪는 시스템이 다수 존재함
제1정규형(1NF) 위반
테이블의 셀에 여러 개의 값을 포함하지 않는다.
| 회원아이디 | 나이 | 성별 | 회원구분 | 연락처 |
| sujilee | 30 | 여 | 프리미엄 | 010-1234-1235, sujilee@naver.com |
| kolee | 36 | 남 | 프리미엄 | 010-1234-1236, kolee@naver.com |
| yhyoon | 34 | 여 | 일반 | 010-1234-1237, yhyoon@naver.com |
| boralee | 38 | 여 | 일반 | 010-1234-1238, boralee@naver.com |
| ijlee | 42 | 남 | 프리미엄 | 010-1234-1239, ijlee@naver.com |
- 회원테이블의 연락처컬럼에 두가지 값이 들어가 있는 경우 제1정규형 위반임
제1정규형(1NF) 위반해소
기존의 회원테이블에서 회원연락처테이블을 추가하여 제1정규형을 만족
| 회원아이디 | 나이 | 성별 | 회원구분 |
| sujilee | 30 | 여 | 프리미엄 |
| kolee | 36 | 남 | 프리미엄 |
| yhyoon | 34 | 여 | 일반 |
| boralee | 38 | 여 | 일반 |
| ijlee | 42 | 남 | 프리미엄 |
회원테이블에서 연락처컬럼을 삭제한 후 회원연락처 테이블을 추가
| 회원아이디 | 연락처구분 | 연락처 |
| sujilee | 휴대폰 | 010-1234-1235 |
| sujilee | 이메일 | sujilee@naver.com |
| kolee | 휴대폰 | 010-1234-1236 |
| kolee | 이메일 | kolee@naver.com |
| yhyoon | 휴대폰 | 010-1234-1237 |
| yhyoon | 이메일 | yhyoon@naver.com |
| boralee | 휴대폰 | 010-1234-1238 |
| boralee | 이메일 | boralee@naver.com |
| ijlee | 휴대폰 | 010-1234-1239 |
| ijlee | 이메일 | ijlee@naver.com |
테이블=함수
- 테이블은 함수와 같다. 기본키의 값을 입력하면 특정 출력 값이 나오는 구조
- 입력X의 경우 반드시 한개의 출력 Y결정
원/통화 환율테이블
환율 = F(통화)
| 통화 | 환율 |
| 달러 | 1211.23 |
| 유로 | 1131.24 |
| 파운드 | 1031.89 |
| 위안 | 1131.13 |
| 스위스 프랑 | 1136.33 |
| 엔 | 1031.90 |
- 함수종속성(Functional Dependency)
| • 통화 --> 환율 • 사원아이디 --> 사원명 • 사원아이디 --> 사원나이 • 주민등록번호 --> 성명 • 학번 --> 소속학과 • 회원아이디 --> 연락처는 복합 값이 포함되어 성립 안됨 |
제2정규형(2NF) 위반
- 부분함수 종속성을 허용하지 않음
- 기본키를 구성하는 열의 일부에만 함수종속이 존재하는 것
- 주문테이블
| 고객아이디 | 주문순번 | 주문일자 | 고객명 | 고객등급 |
| - 올바른 집합 단위에 기초하고 있지 않음 - 갱신 시에 갱신 이상이 발생할 가능성 존재 - 주문 시마다 고객정보를 저장해야 함 - 고객 정보의 중복이 발생할 수 있음 - 고객 정보를 모르면 주문이 불가능 함 |
- 함수종속성(Functional Dependency) 분석
| 분석 | 결과 |
| 주문일자는 고객아이디와 주문순번으로 결정 | 부분함수 종속아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
| 고객명은 고객아이디로만 결정 | 부분함수 종속임, 즉 기본키를 구성하는 열의 일부에만 함수종속이 존재하는 것(제2정규형 위반) |
| 고객등급은 고객아이디로만 결정 | 부분함수 종속임, 즉 기본키를 구성하는 열의 일부에만 함수종속이 존재하는 것(제2정규형 위반) |
제2정규형(2NF) 위반해소
- 전체 열이 기본키만으로 함수종속 가짐
- 기본키의 일부에만 종속하는 열 없음
- 고객주문테이블
| 고객아이디 | 주문순번 | 주문일자 |
- 고객테이블
| 고객아이디 | 고객명 | 고객등급 |
- 함수종속성(Functional Dependency) 분석
| 분석 | 결과 |
| 주문일자는 고객아이디와 주문순번으로 결정 | 부분함수 종속 아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
| 고객명은 고객아이디로 결정 | 부분함수 종속 아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
| 고객등급은 고객아이디로 결정 | 부분함수 종속 아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
제3정규형(3NF) 위반
- 기본키를 제외한 일반컬럼끼리 함수종속이 발생
- 기본키 이외의 키 간 발생하는 함수의 종속
- 고객테이블
| 고객아이디 | 고객명 | 나이 | 직업코드 | 직업명 |
- 함수종속성(Functional Dependency) 분석
| 분석 | 결과 |
| 고객명은 고객아이디로 결정 | 부분함수 종속 아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
| 나이는 고객아이디로 결정 | 부분함수 종속 아님, 즉 기본키를 구성하는 열 전부에 함수종속이 존재 |
| 직업명은 직업코드로 결정 | 일반칼럼인 직업코드에 함수종속이 존재함(제3정규형 위반) |
제3정규형(3NF) 위반해소
- 고객테이블과 직업테이블로 테이블을 분리
- 직업명은 직업코드에만 종속되므로 별도의 테이블로 분리해야 함
- 고객테이블
| 고객아이디 | 고객명 | 나이 | 직업코드 |
- 직업테이블
| 직업코드 | 직업명 |
제4, 5정규형
- 제4정규형 및 5정규형의 경우 실무에서 거의 쓰이지 않으므로 제3정규형까지는 완벽히 이해하기
DA# 설치 및 데이터모델링 실습
DA#
- 데이터전문회사 ㈜엔코아에서 개발 및 출시한 데이터모델링도구
- 교육용(비상업용)으로는 무료인데 사내비즈니스에 도입시 라이선스구매
- 외산 툴에 비해서 배우기 쉽고 다양한 기능을 가지고 있어서 최근 현업에서 많이 쓰이고 있는 추세
- 최근에 각광받고 있는 데이터모델링표기법 중 하나인 바커표기법을 채택한 도구
DA# 설치 및 실행
https://drive.google.com/file/d/1w6vy4AG4vg4hkZ552SWE1QnlZ_5UpBrV/view?usp=sharing













DA# 모델링실습
새 프로젝트만들기




새 엔터티(테이블)생성










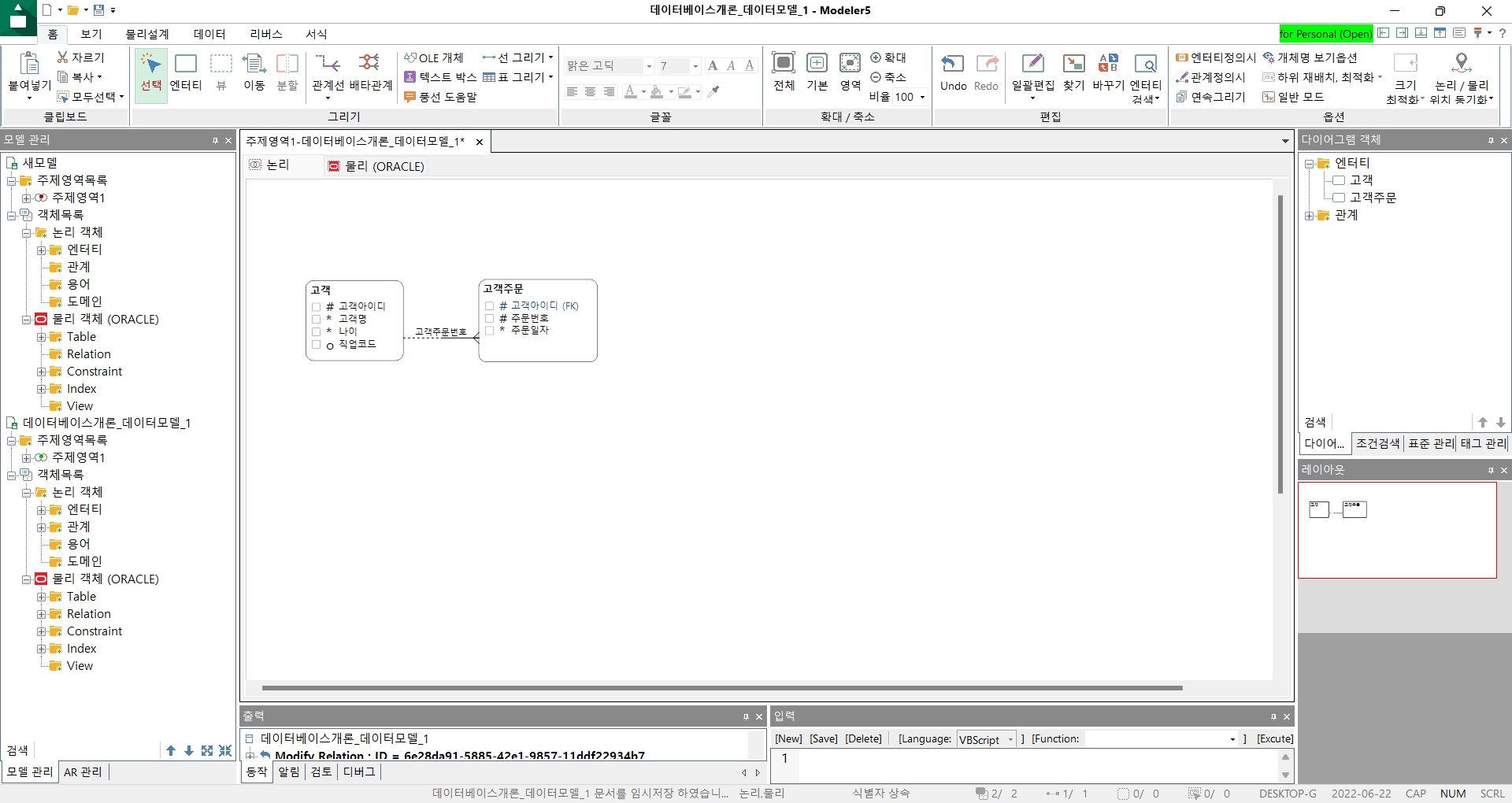
ER다이어그램(Entity-Relationship Diagram)
- 데이터모델링분야에서 개체-관계모델이란 구조화된 데이터에 대한 일련의 표현이다.
- "구조"화된 데이터를 저장하기 위해 데이터베이스를 쓴다. 이 데이터의 "구조" 및 그에 수반한 제약조건들은 다양한 기법에 의해 설계될 수 있다. 그 기법 중 하나가 개체-관계모델링(Entity-Relationship Modelling)이다. 줄여서 ERM이다.
- ERM프로세스의 산출물을 가리켜 개체-관계다이어그램(Entity-Relationship Diagram)이라 한다. 줄여서 ERD라 일컫는다. 데이터모델링과정은 데이터모델을 그림으로 표현하기 위해 표시법을 필요로 한다.
https://ko.wikipedia.org/wiki/%EA%B0%9C%EC%B2%B4-%EA%B4%80%EA%B3%84_%EB%AA%A8%EB%8D%B8
Barker 표기법
- 1986년에 영국컨설팅회사 CACI에서 근무하던 Richard Barker 등에 의해 개발
- 이후 지속적으로 개선되어, 오라클 사에서 기본표기법으로 채택하고 사용하고 있음.
-엔터티(테이블)
| 1) 테이블과 유사하다고 할 수 있음 2) #으로 시작하는 것은 식별자(기본키) 3) *로 시작하는 것은 NOT NULL 4) °로 시작하는 것은 NULL 5) 끝에 (FK)로 끝나는 것은 외래키 |
릴레이션십(Relationship)
- 엔터티(테이블)과 엔터티(테이블) 사이의 관계를 말한다.
- 정의된 엔터티(테이블)은 대부분이 혼자서는 존재할 수 없음 관계가 정의되어야만 비로소 그역할을 해낼 수 있음
- 정리하자면 엔터티 간의 관련성을 표현한 것이고 핵심사항은 FK인 컬럼은 부모테이블의 기본키를 참고하고 있다는 것이다.
백업 및 복구
지속성과 성능이 양립하는 구조
로그선행기입기법
- 로그 선행 기입(write-ahead logging, WAL)을 사용하는 시스템에서 모든 수정은 적용 이전에 로그에 기록된다. 일반적으로 redo 및 undo 정보는 둘 다 로그에 저장된다.
② 한 예로 어느 프로그램이 특정 작업을 수행하는 동안 컴퓨터에 정전이 일어났다고 하자. 다시 시작할 때 프로그램은 어느 작업이 수행을 성 공적으로 마쳤는지, 절반 성공했는지, 아니면 실패했는지를 잘 알고 있어야 한다. 로그 선행 기입이 사용된다면 프로그램은 이러한 로그를 검사하여 예기치 않은 정전 시 해야 할 일과 실제로 했던 일을 비교하게 된다.
https://ko.wikipedia.org/wiki/%EB%A1%9C%EA%B7%B8_%EC%84%A0%ED%96%89_%EA%B8%B0%EC%9E%85
| - 데이터베이스의 데이터 파일을 로그 레코드 사용하여 동기화 - 디스크에 연속해서 쓰기 때문에 무작위로 쓰는 것보다 성능 좋음 - 디스크에 쓰는 용량과 횟수 감소 - 데이터베이스 버퍼 이용해 데이터 파일 변경을 효율적으로 수행 |
데이터베이스 버퍼
- 데이터파일로의 입력을 데이터베이스 버퍼경유로 일원화
- 트랜잭션마다 버퍼를 취할 경우 로그와 데이터 파일간 일관성 저하
- 효율적인 데이터일관성 유지
| 갱신대상의 데이터 포함한 블록이 버퍼 풀에 있는지 확인 | >>>>>> | 없을 경우 데이터파일로부터 해당블록을 읽어 들임 | >>>>>> | 버퍼풀 내에 해당블록을 갱신수행 | >>>>>> | 갱신내용이 Commit과 함께 로그에 기록 |
| ↓↓↓↓↓↓ | ||||||
| 갱신과 더불어 위 순서반복 | <<<<<< | 체크포인트 이전로 그 파일은 불필요하게 됨 | <<<<<< | 갱신된 데이터블록은 나중에 정리되어 데이터파일에 적용됨 (체크포인트) | <<<<<< | 갱신되었지만 데이터파일에 쓰이지 않은 블록은 Dirty 블록이 됨 |
Crash복구에 필요한 항목
- WAL, 데이터베이스 버퍼, 데이터베이스 파일
Crash발생시 복구과정
- WAL: 마지막으로 Commit된 트랜잭션의 갱신정보 가짐
- 데이터베이스 버퍼: Crash로 내용이 전부 소실
- 데이터베이스 파일: 최후 체크포인트까지의 갱신정보 가짐
Crash이후 DBMS서버 재시작
- 데이터베이스 파일을 Crash전 최신 Commit상태로 수정
- 즉, 롤포워드단계가 완성됨
- !!! 논리적, 물리적파괴에는 대응불가 - 정상동작하는 동안 주기적 백업필요
백업의 3가지 관점
- 핫백업과 콜드백업
- 논리백업과 물리백업
- 풀백업과 부분(증분/차등)백업
| - 장애발생에 대비해 현재 이용하는 데이터를 복제하여 다른 곳에 저장 - 백업한 데이터를 이용해서 장애발생시 복원작업 |
핫백업
- 온라인 백업 / 데이터베이스 기능 이용
- 백업대상의 데이터베이스 정지하지 않고 가동한 상태로 백업데이터 얻음
콜드백업(Cold Backup)
- 오프라인 백업 / OS 기능 이용
- 백업대상 데이터베이스 정지한 후 백업데이터 얻음
- 서버 Shutdown, 데이터디렉터리의 파일전부를 OS 명령으로 복사
| DB운영 |
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> |
| 핫 백업 |>>>>>>>>>>>>>>DB 가동>>>>>>>>>>>>>>| 콜드 백업 |>>>>>>>>>>>>>>>DB 정지>>>>>>>>>>>>>>| |
논리백업
- SQL기반 텍스트형식으로 백업데이터 기록
물리백업
- 데이터 영역을 그대로 덤프하는 이미지로 바이너리형식 기록
| 구분 | 장점 | 단점 |
| 논리백업 | - 편집가능 - 텍스트변경을 통한 백업내용 수정가능 - 이식성 우수, 이기종간의 DB이행에 유리 |
- 물리백업보다 용량이 큼 - 백업과 복원의 속도가 느림 |
| 물리백업 | - 최소크기로 데이터 얻음 - 백업 및 복원의 속도가 빠름 |
- 복원단위는 각기 다르며, 일부데이터의 내용수정은 불가능 - 호환성이 좋지 않음(바이너리 한계) |
풀백업(전체백업)
- 데이터베이스 전체데이터를 매일 백업
부분백업
- 풀백업 이후 갱신된 데이터를 백업
- 차등(Differential) 백업
- 증분(Incremental) 백업
| 구분 | 장점 | 단점 |
| 풀백업 | - 백업데이터가 한군데 있음 - 복원처리가 단순함 |
- DB전체 백업으로 시간이 오래걸림 - 과도한 용량을 사용할 수 있음 |
| 부분백업 | - 갱신한 데이터만 대상, 백업의 시간이 짧고 용량도 작음 | - 복원절차가 복잡함 |
데이터베이스 관리 시 주의
- 백업파일들은 떨어진 곳에 각각 보관해야
- 장치를 지리적으로 서로 멀리 위치시켜 장소 자체장애로부터 보호
- 장애발생시 신속한 복구가 가능하도록 운영조건 및 방법 고려해야함
성능
- 성능은 클라이언트 요청에 대한 응답시간(Response Time)과 시간당 처리 할 수 있는 처리량(Throughput)이다.
성능용어
| Concurrent User | |
| || | |
| Active User | 대상 서버에 부하를 발생시키고 있는 사용자 |
| + | |
| Inactive User | 현재 서버에 요청을 보내고 있지 않은 사용자 |
| TPS(Transaction Per Second) | 서버가 일정 시간(초) 내에 처리한 트랜잭션의 양 |
| Response Time | 요청 한 후부터 응답을 받을 때 까지 소요된 시간 |
| Resource | 한정된 값을 가진 시스템의 구성 요소를 의미 |
성능의 특성
- 경합부하 구간에서 Response Time이 급격하게 늘어나게 된다.
성능측정대상
- 목표 TPS를 산정하고 정해진 응답시간 이내에 모든 요청이 처리되는지 확인
| TPS | |
| 건수 기준 | 처리건수/초 |
| Active User기준 | Active User/초 |
| Concurrent User 기준 | Concurrent User/초 |
| Response Time | 3초 이내, 3초 이상부터 느리다고 느끼며, 6초가 한계 |
| Resources | |
| CPU 사용률 | 70%이하 사용 |
| Memory 사용률 | 100%이하 사용, Swap현상 없어야 함 |
| 디스크 사용률 | 100%미만, 디스크소요시간 2~3ms |
데이터베이스 병목의 원인
- 취급하는 데이터 양이 가장 많다
- 시스템에서 처리하는 데이터는 영속적으로 보유해야 하는 데이터일 확률이 크다.
- 데이터의 총 크기는 지속적으로 증가한다.
- 동시성을 보장하는 등의 문제로 무조건 적인 자원 증가 통한 성능 문제해결이 어렵다(저장소 확장이 어려움)
- DBMS 내부 I/O 병목으로 인해 대기 시간이 길어 질 수 있다.
DBMS서버 <<>> I/O Channel <<>> 스토리지
- DBMS I/O 병목으로 인한 성능 문제를 해결하기 위해서는 절대적인 블록 I/O를 줄여야 함
- 블록 I/O를 줄이기 위한 모델 설계, DBMS 환경 구축, SQL 튜닝 등의 기술이 발달함
프로세스생성주기
| new | >>>>>>> admitted |
ready | interrupted <<<<<<<< |
running | >>> exit |
terminated |
| >>>>>>>> dispached |
||||||
| ↓ ↘ I/O완료 또는 이벤트완료 → |
↓ ↙ ← I/O요청 또는 이벤트대기 |
|||||
| waiting | ||||||
- 여러 프로세스가 하나의 CPU를 공유 할 수 있지만, 특정 순간에는 하나의 프로세스만 CPU를 사용하기 때문에 이러한 프로세스 메커니즘이 필연적으로 존재
- interrupted 없이 일하던 프로세스도 디스크에서 데이터를 읽어야할 땐 CPU를 OS에 반환하고 잠시 수면(waiting)상태에서 I/O가 완료되기를 기다린다. (정해진 OS함수를 호출하고 CPU를 반환한채 알림을 설정하고 대기큐에서 기다림)
- 즉, SQL문에서 발생하는 절대적인 I/O의 횟수를 줄이는 것이 성능개선의 핵심
성능을결정하는 요인
SQL문의 특성
- SQL은 기본적으로 구조적이고 집합적이고 선언적인 질의 언어
- 결과 집합을 만드는 과정은 절차적이며, 각각의 프로시저를 만드는 역할을 옵티마이저가 담당
| 사용자 | → | 옵티마이저 | → | 프로시저 |
SQL(Structured Query Language)
- SQL is designed for a specific purpose : to query data contained in a relational database
- SQL is set-based, declarative query language, not an imperative language such as C or BASIC
SQL문의 실행과정
| SQL 파싱 | 사용자로부터 SQL을 전달받으면 가장 먼저 SQL Parser가 Parsing을 진행 |
| - 파싱 트리 생성 : SQL문을 이루는 개별 요소를 분석하여 Parsing Tree 생성 - Syntax 체크 : 문법적 오류가 있는지 확인 (예:WHERH) - Semantic 체크 : 의미상 오류가 없는지 확인 (예:존재하지 않는 테이블 등) |
|
| SQL 최적화 | 옵티마이저의 역할임. 미리 수집한 시스템 및 오브젝트 통계정보를 바탕으로 다양한 실행 경로를 생성해서 비교 후 가장 효율적인 하나를 선택함 (DBMS성능의 가장 핵심적인 요소) |
| 로우 소스생성 | 옵티마이저가 선택한 실행경로를 실제 실행가능한 코드 또는 프로시저 형태로 포맷팅 하는 단계 (Row-Source Generator가 그 역할을 맡음) |
옵티마이저
- SQL옵티마이저는 사용자가 원하는 작업을 효율적으로 수행할 최적의 데이터 액세스 경로를 선택해주는 DBMS의 핵심엔진
- 후보군이 될 만한 실행계획을 찾아낸 후, 통계정보를 이용해 각 실행계획의 예상비용을 산정한 후 최저비용을 나타내는 실행계획을 선택
옵티마이저가 참조하는 통계정보(Statistics)
- 테이블의 데이터를 샘플링 추출하여 통계정보 획득
- 효율적인 참조 데이터 수집
통계정보가 가지고 있는 데이터
| - 테이블의 행수 및 열수 - 각 열의 길이와 데이터형 - 테이블의 크기 - 열에 대한 기본키나 NOT NULL 제약 정보 - 열 값에 대한 통계 - 인덱스에 대한 통계(선택도, NULL값의 개수 등) |
| SQL 파싱 | ||
| ↓ | ||
| 실행계획 작성 | ←←←←←←←←← 통계정보 활용 |
통계정보 |
| ↓ | ||
| 실행계획 선택 | ||
| ↓ | ||
| SQL 실행 |
실행계획은 어떻게 실행되는가?
인덱스를 이용한 성능개선
- 인덱스는 큰 테이블에서 소량의 데이터를 검색할 때 사용한다. 대부분의 시스템은 소량의 데이터를 주로 검색하므로 인덱스 튜닝이 무엇보다 중요하다.
- 인덱스 튜닝의 시작은 효율적인 인덱스 컬럼으로 인덱스를 구성하는 것이다.
인덱스스캔 효율화
- 예) 시력이 1.0~1.5인 이정민 학생을 찾는 경우
랜덤엑세스 최소화
- 인덱스 스캔 후 추가 정보를 가져오기 위해 Table Random Access를 수행한다.
- 해당 작업은 DBMS 성능 부하의 주 요인이 되며 SQL튜닝은 곧 Random I/O와의 전쟁이라 할 수 있다.
인덱스구조
- 인덱스를 이용하면 데이터 일부만 읽고 멈출 수 있다.
- 범위 스캔이 가능하며, 범위 스캔이 가능한 이유는 인덱스가 정렬된 상태로 저장되어 있기 때문이다.
| 루트 | ||||||
| 브랜치 | ||||||
| 리프 |
인덱스구조 - 계속
인덱스구조 상세
| - 루프와 브랜치블록에 있는 각 레코드는 하위블록에 대한 주소값을 갖는데 키 값은 하위블록에 저장된 키값의 범위 - LMC가 가리키는 주소로 찾아간 블록에는 키 값을 가진 첫번째 레코드보다 작거나 같은 레코드가 저장돼 있다. - 리프블록에 저장된 각 레코드는 키값 순으로 정렬돼 있을 뿐만 아니라 테이블레코드를 가리키는 주소값 즉 ROWID를 가짐 - 인덱스 키 값이 같으면 ROWID 순으로 정렬 - 인덱스를 스캔하는 이유는 검색조건을 만족하는 소량의 데이터를 빨리 찾고 거기서 ROWID를 얻기 위해서이다. - ROWID는 Data Block Address와 Row Number로 구성 |
ROWID의 구성
| 항목 | 구성 |
| ROWID | 데이터 블록 주소 + 로우번호 |
| 데이터블록 주소 | 데이터 파일 번호 + 블록번호 |
| 블록번호 | 데이터 파일 내에서 부여한 상대적 순번 |
| 로우번호 | 블록 내 순번 |
인덱스의 특장점
- 인덱스는 데이터베이스의 성능향상수단
- SQL문을 변경하지 않아도 성능개선가능
- 테이블 데이터에 영향주지 않는다. (인덱스는 테이블과 별도의 객체임)
- 일정하게 성능을 빠르게 하고 종종 극적인 성능향상이 될 수도 있다.
- 비용 대비 높은 성능향상을 이뤄낸다.
- 특정 SQL문이 사용하기에 비효율적인 인덱스인 경우 오히려 테이블 풀 스캔보다 느릴 수 있으므로 무조건 적인 사용은 지양하자.
인덱스는 B* Tree의 데이터구조를 가지는데...
- 데이터를 유지하기 위해 자주 사용하는 구조
- 효율적이고 빠른탐색 가능
- 데이터를 정렬(Sort)된 상태로 유지
| 구분 | 설명 |
| 균일성 | - 어떤 값에 대해서도 같은 시간에 결과 얻을 수 있음 |
| 이진탐색 | - 정렬 마친 데이터 구조 탐색에 효과적 - 정렬하지 않은 데이터를 선형 탐색 시 성능 불균형 발생 |
| 밸런스 | - Balanced-tree의 특성 - 루트로부터 리프까지의 거리가 일정 → 성능 안정화 - 정기적으로 재구성 통해 균형 회복 필요 |
SQLD
데이터모델링의 정의
- 복잡한 현실세계를 단순화시켜 표현
- 사물 또는 사건에 관한 양상(Aspect)이나 관점(Perspective)을 연관된 사람이나 그룹을 위하여 명확하게 한 것
- 현실세계의 추상화된 반영
현실세계->추상화,단순화,명확화->데이터모델
복잡한 현실세계를 일정한 표기법에 의해 표현하는 일
모델링의 특징
① 추상화(모형화, 가설적)는 현실세계를 일정한 형식에 맞추어 표현을 한다는 의미
② 단순화는 복잡한 현실세계를 약속된 규약에 의해 제한된 표기법이나 언어로 표현
③ 명확화는 누구나 이해하기 쉽게 하기 위해 대상에 대한 애매모호함을 제거하고 정확(正確)하게 현상을 기술
모델링의 세가지관점
모델링 |
→→→→ ↓ ↓ →→ ↓ ↓ →→ |
데이터 관점 (Data, What) |
업무가 어떤 데이터와 관련이 있는지 또는 데이터간의 관계 는 무엇인지에 대해서 모델링하는 방법 |
| 프로세스 관점 (Process, How) |
업무가 실제하고 있는 일은 무엇인지 또는 무엇을 해야 하는 지를 모델링하는 방법 | ||
| 상관 관점 (Data vs Process) |
업무가 처리하는 일의 방법에 따라 데이터는 어떻게 영향을 받고 있는지 모델링하는 방법 |
데이터모델링의 정의
- 정보시스템을 구축하기 위한 데이터관점의 업무분석기법
- 현실세계의 데이터에 대해 약속된 표기법에 의해 표현되는 과정
- 데이터베이스를 구축하기 위한 분석 및 설계의 과정
데이터모델이 제공하는 기능
- 시스템을 현재 또는 원하는 모습으로 가시화
- 시스템의 구조와 행동을 명세화
- 시스템을 구축하는 구조화된 틀을 제공
- 시스템을 구축하는 과정에서 결정한 것을 문서화
- 다양한 영역에 집중하기 위해 다른 영역의 세부사항은 숨기는 다양한 관점을 제공
- 특정목표에 따라 구체화된 상세수준의 표현방법을 제공
데이터모델링의 중요성 및 유의점
| 중요성 | 설명 |
| 파급효과(Leverage) | 시스템구축작업 중에서 다른 어떤 설계과정보다 데이터설계가 중요 |
| 복잡한 정보요구사항의 간결한 표현(Conciseness) | 데이터 모델은 구축할 시스템의 정보 요구사항과 한계를 가장 명확하고 간결하게 표현할 수 있는 도구 |
| 데이터 품질(Data Quality) | 데이터의 중복, 비 유연성, 비 일관성이 발생할 수 있음 |
데이터모델링의 3단계진행
| 현실세계 | >>>>개념 데이터 모델링(추상적)>>>> | 개념적 구조 |
| ↓ 논리데이터 모델링 | ||
| 물리구조(데이터베이스) | <<<<물리 데이터 모델링(구체적)<<<< | 논리적구조 |
| 단계명 | 설명 |
| 개념적데이터모델링 | 추상화 수준이 높고 업무 중심적이고 포괄적인 수준의 모델링 진행. 전사적 데이터 모델링, EA수립시 많이 사용 |
| 논리적데이터모델링 | 시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현, 재 사용성이 높음 |
| 물리적데이터모델링 | 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계 |
프로젝트생명주기(Life Cycle)에서 데이터모델링
- 프로젝트 생명 주기는 정보전략계획 -> 분석 -> 설계 -> 개발 -> 테스트 -> 전환/이행 단계가 있음
- 정보전략계획/분석 단계: 개념적 데이터 모델링
- 분석 단계: 논리적 데이터 모델링
- 설계 단계: 물리적 데이터 모델링
데이터독립성의 필요성
- ① 지속적으로 증가하는 유지보수 비용을 절감하고 데이터 복잡도를 낮추며 중복된 데이터를 줄이기 위한 목적이 있음
② 끊임없이 요구되는 사용자 요구사항에 대해 화면과 데이터베이스 간에 서로 독립성을 유지하기 위한 목적으로 데이터 독 립성 개념이 출현
| 유지보수비용증가 | → ↓ →→ ↑ → ↑ → |
||
| 데이터중복성증가 | 데이터독립성 필요 |
→→→→→→→→→↘ ↓ |
|
| 데이터복잡도증가 | |||
| 요구사항대응저하 | 데이터독립성확보 | ||
| - 각 View의 독립성을 유지하고 계층별 View에 영향을 주지 않고 변경이 가능 - 단계별 Schema에 따라 데이터 정의어(DDL)와 데이터 조작어(DML)가 다름을 제공 |
|||
데이터베이스 3단계 구조
ANSI/SPARC의 3단계 구성의 데이터독립성 모델은 외부 단계와 개념적 단계, 내부적 단계로 구성된 서로 간섭 되지 않 는 모델을 제시하고 있다.
| 외부단계 | External Schema #1 | External Schema #2 | External Schema #3 |
| ↘ 논리적데이터독립성 ↓ ↙ | |||
| 개념적단계 | 개념스키마 | ||
| ↓ 물리적데이터독립성 | |||
| 내부적단계 | 내부스키마 | ||
엔터티의 개념
- 엔터티는 사람, 장소, 물건, 사건, 개념 등의 명사
- 엔터티는 업무상 관리가 필요한 관심사
- 엔터티는 저장이 되기 위한 어떤 것(Thing)
엔터티와 인스턴스

엔터티 표기법

엔터티의 특징
| 특징 | 설명 |
| 업무에서 필요로 하는 정보 | 업무에서 필요로 하고 관리하고자 하는 정보 |
| 식별이 가능해야 함 | 인스턴스 각각을 구분하기 위해 유일한 식별자가 존재 |
| 인스턴스의 집합 | 한개가 아닌 두개 이상 |
| 업무프로세스에 의해 이용 | 업무 프로세스(Business Process)가 그 엔터티를 반드시 이용 |
| 속성을 포함 | 엔터티에는 반드시 속성(Attributes)이 포함 |
| 관계의 존재 | 최소 한 개 이상의 관계가 존재 해야 |
엔터티의 분류
| 유무형의 분류 | ||
| 유형 | 사원, 물품, 강사 | 물리적인 형태 |
| 개념 | 조직, 보험상품 | 개념적 정보 |
| 사건 | 주문, 청구, 미납 | 업무를 수행함에 따라 발생 |
| 발생시점 분류 | ||
| 기본(키) | 고객, 상품 | 업무에 원래 존재하는 정보 |
| 중심(메인) | 주문, 배송 | 중심적인 역할 |
| 행위(액션) | 주문변경이력 | 두 개 이상의 부모엔터티로부터 발생 |
엔터티의 명명
- 현업업무에서 사용하는 용어만 사용
- 약어를 사용하지 않는다.
- 단수명사 사용
- 모든 엔터티에서 유일하게 이름을 부여
- 엔터티 생성 의미대로 이름을 부여
속성(Attribute)의 개념
업무에서 필요하며 더 이상 분리되지 않으며 인스턴스의 구성요소이다.
엔터티, 인스턴스, 속성, 속성값의 관계
- 한개의 엔터티는 두개 이상의 인스턴스집합
- 한개의 인스턴스는 두개이상의 속성
- 한개의 속성은 한개의 속성값
- 이름, 주소, 생년월일이 속성
- 홍길동, 서울시 강서구, 1967년 12월 31일은 속성값(VALUE)
속성의 표기법
- 속성명을 기재하고 해당속성이 식별자인지 표시하며 필수값(*)인지 선택값(O)인지 표시
- 속성의 표기법은 엔터티 내에 이름을 포함하여 표현
속성의 특징
- 해당업무에서 필요하고 관리하고자 하는 정보(ex. 강사의 강사명)
- 주식별자에 함수적종속성
- 하나의 속성에는 한개의 값만 가짐
속성의 분류 중 특성에 따른 분류
- 기본속성은 업무분석을 통해 정의함(ex. 제품번호, 이름, 일시, 원가)
- 설계속성은 설계를 해서 도출하는 것(ex. 제조사코드)
- 파생속성은 다른속성으로부터 계산이나 변형되어 생성(ex. 판매금액합계)
속성의 분류 중 엔터티구성방식에 따른 분류
- PK(Primary Key)는 식별할 수 있는 속성(ex. 부서(부서번호), 사원(사원번호))
- FK(Foreign Key)는 다른 관계에 포함된 속성(ex. 사원(부서번호))
- 일반속성은 PK와 FK에 포함되지 않음(ex. 부서(부서명), 사원(사원명, 우편번호, 주소, 전화번호))
도메인
학점이라는 속성의 도메인은 0.0~4.0의 실수값
주소속성은 길이가 20자리이내인 문자열
속성의 명명
- 해당업무에서 사용하는 이름부여
- 서술식 속성명은 안됨
- 약어사용은 제한
- 전체 데이터모델에서 유일성 확보
관계의 정의
엔터티간의 상호연관성, 논리적인 연관성, 존재에 의한 관계와 행위에 의한 관계로 구분
관계의 페어링(Relationship Paring)
엔터티에서 인스턴스들은 자신이 관련된 인스턴스들과 관계 내의 어퍼런스(발생, 사건)로 참여하는 형태
관계의 분류 중 존재에 의한 관계
"소속된다" 즉, 존재의 형태에 의해 관계가 형성
관계의 분류 중 행위에 의한 관계
"주문한다" 관계는 행위에 의한 관계
관계의 표기법
| 개념 | 설명 |
| 관계명 | 관계의 이름 |
| 관계차수 | 1:1, 1:ㅁ M::M |
| 관계선택사양 | 필수관계, 선택관계 |
관계의 표기법 중 관계명
관계에 참여하는 형태로 두개의 관계명에 의해 두가지의 관점으로 표현
관계시작점과 끝점 모두 관계이름을 가져야 하며 참여자의 관점에 따라 관계이름이 능동적이거나 수동적으로 명명됨
관계의 명명규칙 중 애매한 동사를 피하고 현재형으로 표현
| O "수강 신청한다" "강의를 한다" | X "수강을 신청했다" "강의를 할 것이다" |
관계의 표기법 중 관계차수
두개의 엔터티간 관계의 참여자수 표현으로 1:1, 1:M, M:M이다.
1:1 관계에 참여하는 각각의 엔터티는 관계를 맺는 다른 엔터티에 대해 단지 하나의 관계만을 가짐
1:M 한 명의 사원은 한 부서에 소속되고 한 부서에는 여러 사원을 포함
M:M 관계에 참여하는 각각의 엔터티는 관계를 맺는 다른 엔터티에 대해 하나 혹은 그 이상의 수와 관계를 가짐
관계의 표기법 중 관계선택사양(Optionality)
예를 들어 지하철출발과 문닫힘은 필수적이므로 필수참여관계
선택참여관계 지하철의 출발과 방송은 정보와 관계가 있지만 필수적관계가 아니므로 선택적인관계가 됨
관계정의시 체크사항
연관규칙(두 엔터티사이에서 관심있는), 정보의 조합(두 엔터티사이), 규칙서술(관계연결), 동사(관계연결)
관계읽기
기준엔터티를 한개 또는 각으로 함
대상 엔터티의 관계참여개수(하나, 하나이상)로 읽음
관계선택사양(필수/선택)과 관계명 읽기
식별자(Identifiers) 개념
각 인스턴스를 개별적으로 식별하기 위한 식별자이다
식별자의 특징
유일하게 구분되며 최소의 수가 되며 자주 변하지 않는 것과 값이 반드시 있어야 함
| 특징 | 내용 | 비고 |
| 유일성 | 주식별자에 의해 모든 인스턴스를 유일하게 구분 | 주식별자가 모든 직원들에게 개인별로 고유하게 부여 |
| 최소성 | 유일성을 만족하는 최소의 수 | 사원분류코드와 사원번호를 더한 식별자로 구성되면 부적절 |
| 불변성 | 그 식별자의 값은 변하지 않아야 함 | 이전기록이 말소되고 새로운 기록이 발생 |
| 존재성 | 데이터 값이 존재해야 함(Null X) | 사원번호 없는 회사직원은 있을 수 없음 |
식별자 분류
| 분류 | 식별자 | 설명 |
| 대표성 여부 | 주식별자 | 엔터티 내에서 각 행을 구분할 수 있는 구분자(예. 사원번호, 고객번호) |
| 보조식별자 | 각 행을 구분할 수 있는 구분자이나 대표성은 가지지 못해서 참조관계 연결X(예. 주민등록번호) | |
| 스스로 생성여부 | 내부식별자 | 스스로 만들어지는 식별자(예. 고객번호) |
| 외부식별자 | 타 엔터티와의 관계로 타 엔터티로부터 받는 식별자(예. 주문엔터티의 고객번호) | |
| 속성의 수 | 단일식별자 | 하나의 속성으로 구성(예. 고객엔터티의 고객번호) |
| 복합식별자 | 둘 이상의 속성으로 구성(예. 주문상세엔터티의 주문번호+상세순번) | |
| 대체여부 | 본질식별자 | 업무에 의해 만들어지는 식별자(예. 고객번호) |
| 인조식별자 | 인위적으로 만든 식별자(예. 주문엔터티의 주문번호 (고객번호+주문번호+순번)) |
식별자 도출기준
- 해당업무에서 자주 이용되는 사원번호를 주식별자로 지정
- 명칭, 내역처럼 이름으로 기술되는 것은 가능하면 주식별자로 지정하지 않음(동명이인이 없어도 지정 안됨)
- 복합으로 주식별자로 구성할려면 너무 많은 속성이 포함되지 않도록 함
- 예를 들면 직원번호만으로도 충분하다고 판단되어 직원번호로만 지정해도 됨
인조식별자를 통해 단순화한 주식별자 속성 중에서...
모델상에서 표현하는 문장의 간편성이나 애플리케이션 구성에 있어서도 복잡한 소스구성을 피하려면 과도한 복합키는 배제하도록 노력필요
식별자관계와 비식별자 관계의 결정
- 다른 엔터티와의 관계를 통해 자식쪽 엔터티에 생성되는 속성을 외부식별자이며 Foreign Key
- 주식별자로 이용할 것인지(식별자관계) 또는 부모와 연결이 되는 속성으로서만 이용할 것인지 결정(비식별자관계)
- 업무특징, 자식엔터티의 주 식별자구성, SQL 전략에 의해 결정됨
식별자관계
자식엔터티의 주식별자로 부모의 주식별자가 상속이 되는 경우
비식별자관계
- 부모덴터티로부터 속성을받았지만 자식엔터티의 주식별자로 사용하지 않고 일반적인 속성으로만 사용하는 경우
- 자식엔터티에서 별도의 주식별자를 생성하는 것이 더 유리하다 판단
- 외부 식별자는 FK의 역할
식별자관계로만 설정할 경우 문제점
- 식별자 관계의 경우 주문엔터티가 고객엔터티의 고객번호를 식별자로 받음
- 비식별자 관계의 경우 주문엔터티가 주문번호라는 식별자를 별도로 이용
- 식별자관계만으로 연결된 데이터모델의 특징은 주식별자 속성이 지속적으로 증가할 수 밖에 없는 구조
- 개발의 복잡성과 오류가능성을 유발하는 주된 요인
식별자관계와 비식별자관계
- 식별자관계에서 비식별자관계를 파악하는 기술이 필요한데 다음 흐름에 따라 비식별자관계를 선정한다면 합리적으로 관계를 설정하는 모습이 됨
- 관계분석 > 관계의 강약분석 > 자식테이블 독립 PK 필요 > SQL복잡성 증가
- 관계분석을 제외하고 각각 약한관계 독립PK구성, PK속성 단순화 하는 등 비식별자관계를 고려
Business Analyst를 위한 핵심SQL실전
데이터분석가 주요 이력
지식과 경험, 역량과 아이디어로 데이터기술 전달
통계학학사 및 석사
S카드 회원마케팅
직무교육 R, Python
분석 프로젝트
- L유통의 경우 마트 및 백화점상품 추천
- H손보의 경우 유지예측, 고객 등급화, FDS 등 모형개발 코칭
- B카드의 경우 마이데이터활용 상품추천
창업컨설팅/ 컨텐츠
데이터의 위상
2012년에는 필요한 데이터를 요청해서 활용했다면,
2022년에는 데이터가 어디에서든 필요하다면 자유자재로 활용가능
소비의 디지털화
소비채널이 디지털화하면서 스마트디바이스(스마트폰)으로 더 많은 돈과 시간을 씀
이후 데이터로 표현되는 삶에서 각자의 데이터를 한 데 모으면 우리의 삶을 재구성하는 것이 가능함
데이터=빅데이터
전화기가 스마트폰으로 진화하듯 2007년식 아이폰이 2021년식 아이폰13으로 업그레이드 되었고 2012년의 데이터는 2022년의 빅데이터로 발전을 거듭하고 있다.
데이터의 가치
데이터의 또다른 이름은 금광, 새로운 석유이며 무엇을 어떻게 활용할 가능성과 얼마나 파급되는지 효과를 고려함
데이터와 데이터공간 (변수가 많을수록 빅데이터는?)
데이터공간의 변화로 변수갯수만큼 차원이 만들어지고 관측치갯수만큼 점이 표시됨
활용가능한 변수의 개수가 고객수, 계약건수, 청구건수보다 매우 중요함
데이터결합을 통한 아이디어 발굴(데이터 퓨전(융합)으로)
새로운 변수는 새로운 관계를 만들고, 새로운 아이디어를 창출함
Digital Transformation (아날로그에서 디지털로)
- 전산화로 아날로그프로세스를 디지털형태로 변환
- 디지털화로 비즈니스업무에 IT/데이터기술을 활용
- 데이터기반 의사결정 데이터에 기반한 객관적, 효율적, 고도화된 의사결정
업무태블릿과 DT
- 데이터적재고정의 전산화로 기존의 종이문서를 수기를 작성한 후 스캔해서 OCR로 정보입력하던 것을 태불릿 내 전자문를 작성함
- 공간 및 정보전달의 디지털화는 기존에 영업공간의 제약으로 인해 직원중심의 정보전달에 한계가 있었지만 변화는 공간의 제약을 극복하고 고도화된 정보(관리가 필요한 계약목록, 계약자별 추천상품목록 등)를 제공
다시 한번 "빅데이터" (이미 한번 유행이 지났다가)
1. 데이터분석을 통한 인사이트도출 및 데이터기반 의사결정
숫자를 활용한 객관적이고 합리적인 판단
목표설정(KPI)과 전략 및 실행계획을 수립한 후 실행평가와 같은 대부분의 업무에 적용함
2. RPA 및 대시보드를 활용한 분석과정의 효율화
복잡한 시장환경과 데이터 및 정보의 증가로 전산업무량 증가함
반복되는 업무의 자동화(Robotic Process Automation)로 대시보드 활용
3. 머신러닝(Machine learning)을 활용한 분석과정의 효율화
알고리즘을 활용한 데이터정보의 고도화
AI개발 및 활용을 궁극적인 목표로 설정
금융업과 데이터퓨전(융합으로 다양한 데이터 활용)
한국신용정보원에서 보험신용정보를 제공하는 보험계약현황 및 보험금 청구지급현황
주소기반의 소득추정으로 추정가구소득 및 추정개인소득정보
고객주소기반 택배품목정보
마이데이터에서 타 금융사의 거래 및 계약정보 등 통합금융정보
데이터관련법과 마이데이터 사업
데이터거래소 같은 곳에서 가명정보의 상업적목적과 제3자 제공데이터 활용가능하고,
데이터회사의 API로 고객정보 제공의무를 부여해서 정보통합조회, 맞춤형 상품추천 등 관리서비스
금융지주의 확장과 경쟁
대표 앱으로 신한은행의 신한플레이, 국민은행의 리브메이트, 네이버의 Npay 등
다양한 비즈니스 데이터 활용사례
제조업과 데이터분석(만들 때 마음대로)
- 구매과정에서 원자재수요와 원재료구매 예측으로 납품업체를 관리 -> 예측 어려움
- 생산공정설계 및 제품생산현황을 파악해서 관리불량을 잡아내는 품질관리 -> 식스시그마 활용
- 판매과정에서 생산재고를 관리하고 판매 및 유통채널 관리 -> 예측 어려움
품질관리(QC) 프로세스의 변화
다양한 데이터수집에서
- 기존 생산공정 및 측정데이터
- IoT를 활용한 외관 이미지데이터
- 원재료특성, 기상 등 외부데이터
알고리즘 활용으로
- 외관찍힘여부 판별모형 활용
- 전압 및 전류데이터를 통합적으로 활용하는데 적합하도록 불량판별모형을 수립하는데 활용
알고리즘을 활용한 효율화 전략예시
제조업의 AI주도 검사체계 - SK hynix사례
보험금지급프로세스개선체계가 앱으로 지급신청하면 자동심사프로세스를 거쳐 최종지급하도록 변화함(기존에는 지급신청을 하면 스캔으로 이메일을 전송하면 심사를 한 후 지급을 하는 방식)
이커머스업 | 콘텐츠업과 데이터분석(고객이 1이라도 더 만족하도록)
채널로 홈페이지, 모바일 웹 및 앱을 관리해서 UI, UX와 트래픽을 관리 -> 그로스해킹 -> 클라우드활용
고객유치 및 관리, 마케팅상품 추천 등 개인화마케팅에 활용 -> 고객별 맞춤상품 및 콘텐츠를 추천하는 큐레이션 -> AI활용
상품소싱과 함께 홍보하기 위한 콘텐츠제작 및 소싱 ->>>>>>↗
관계형데이터베이스(RDB)의 활용
- RDB(Relational Database)로 키(key)와 값(value)들의 관계를 구조화하고 데이터를 구성
- SQL클라이언트로 데이터를 결합하고 추출
거래데이터
| 거래ID | 회원ID | 가맹점ID | 결제일시 | 결제금액 |
회원데이터
| 회원ID | 성별 | 연령 | 거주지역 |
가맹점데이터
| 가맹점ID | 업종코드 | 주소 | 수수료율 |
데이터베이스관련 주요 키워드
DB 데이터베이스는 특수한 목적을 위한 종합적으로 관리하는 데이터의 집합
DBMS 데이터베이스 관리시스템은 데이터베이스를 효과적으로 관리하는 소프트웨어(Oracle, MySQL, Sybase, SAP)
EDW 기업데이터저장소는 기업 데이터베이스의 데이터를 공통의 형식으로 일원적으로 관리하는 데이터베이스
RDB관계형데이터베이스는?
SQL의 개념과 활용
SQL(Structured Query Language)
데이터베이스에서 필요한 데이터를 추출, 정렬, 요약하기 위한 명령어
정렬, 필터, 피벗테이블 등 EXCEL의 대표기능 역시 일종의 SQL언어
전체데이터가 아닌 분석에 필요한 부분데이터로 효율적인 모형구축가능
SQL구문(statement)을 활용한 CRUD
Create(생성)
Read(읽기): "SQL 쿼리(Query)실행"
Update(갱신)
Delete(삭제)
SQL구문의 구성
- 식별자(Identifier)로 테이블이름, 변수이름 등 DB에 사용된 개체(Object)구성
- 연산자(Operator)와 함수(function)로 특정한 연산이나 계산을 위해 역할을 정의해둔 기호나 기능
- 키워드(Keyword)로 DB에서 데이터의 위치와 조건, 추출요건 등을 정의
- 절(Clause)로 키워드와 상세요건을 합침
SQL은 생각보다?
- 키워드(KEYWORD)가 10개이내
- 함수(FUNCTION)가 20개이내
- 수십개 스키마(주제)이름 수백개 테이블이름 더많은 변수이름(IDENTIFIER)
-> SQL쿼리를 잘해야 회사의 DB구조를 이해하기가 수월함
SQL Read 권한과 주요키워드
대부분 Read 권한만 부여
SELECT/FROM/WHERE 등을 조합한 쿼리(구문) 작성하고 실행하여 필요한 데이터 추출
- SELECT 변수이름, 집계함수
- FROM 테이블이름, JOIN 키워드를 활용한 테이블 결합
- WHERE 변수를 활용한 조건
- GROUP BY 그룹변수이름
- ORDER BY 정렬변수이름
- HAVING 집계값을 활용한 조건
자세한 강의내용은 아래의 데이터베이스 특강파일 참고
하나씩 붙여가는 기본 SQL쿼리 - MySQL Workbench 실전실습
mysqlsampledatabase-sales스키마 추가


1. 연산자함수(Operators_Functions)








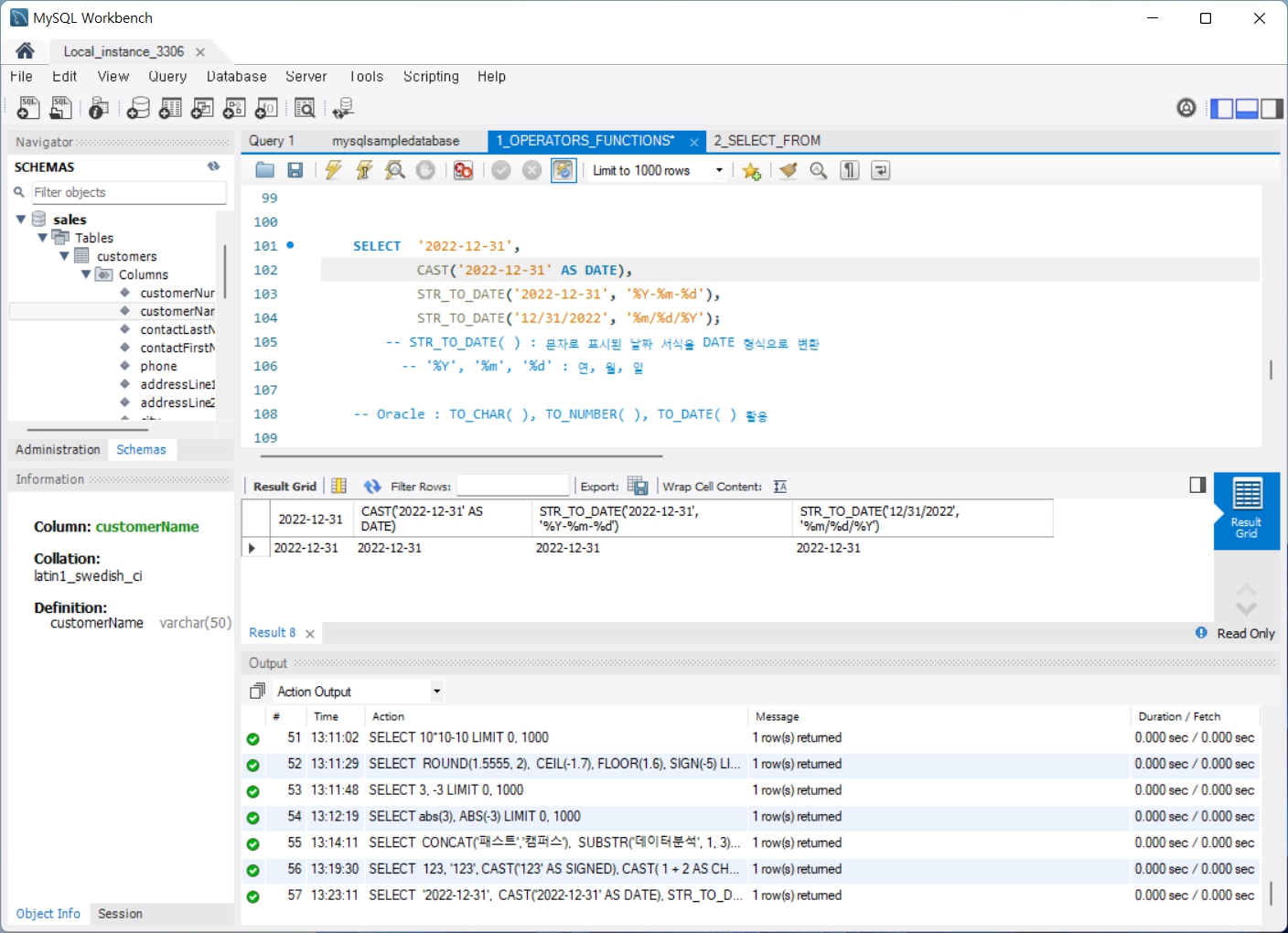




2. SELECT_FROM





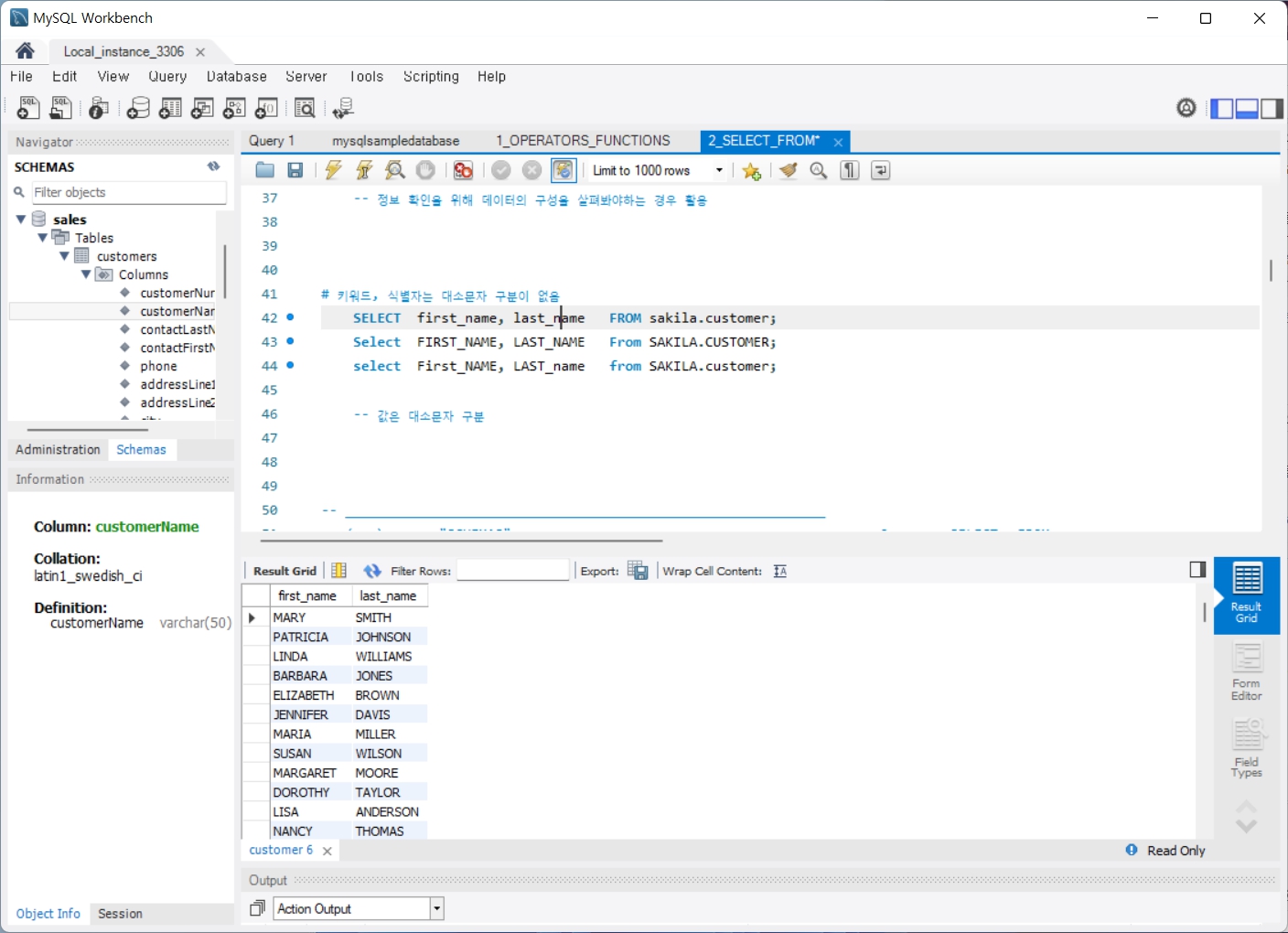





























3. SELECT_FROM_WHERE







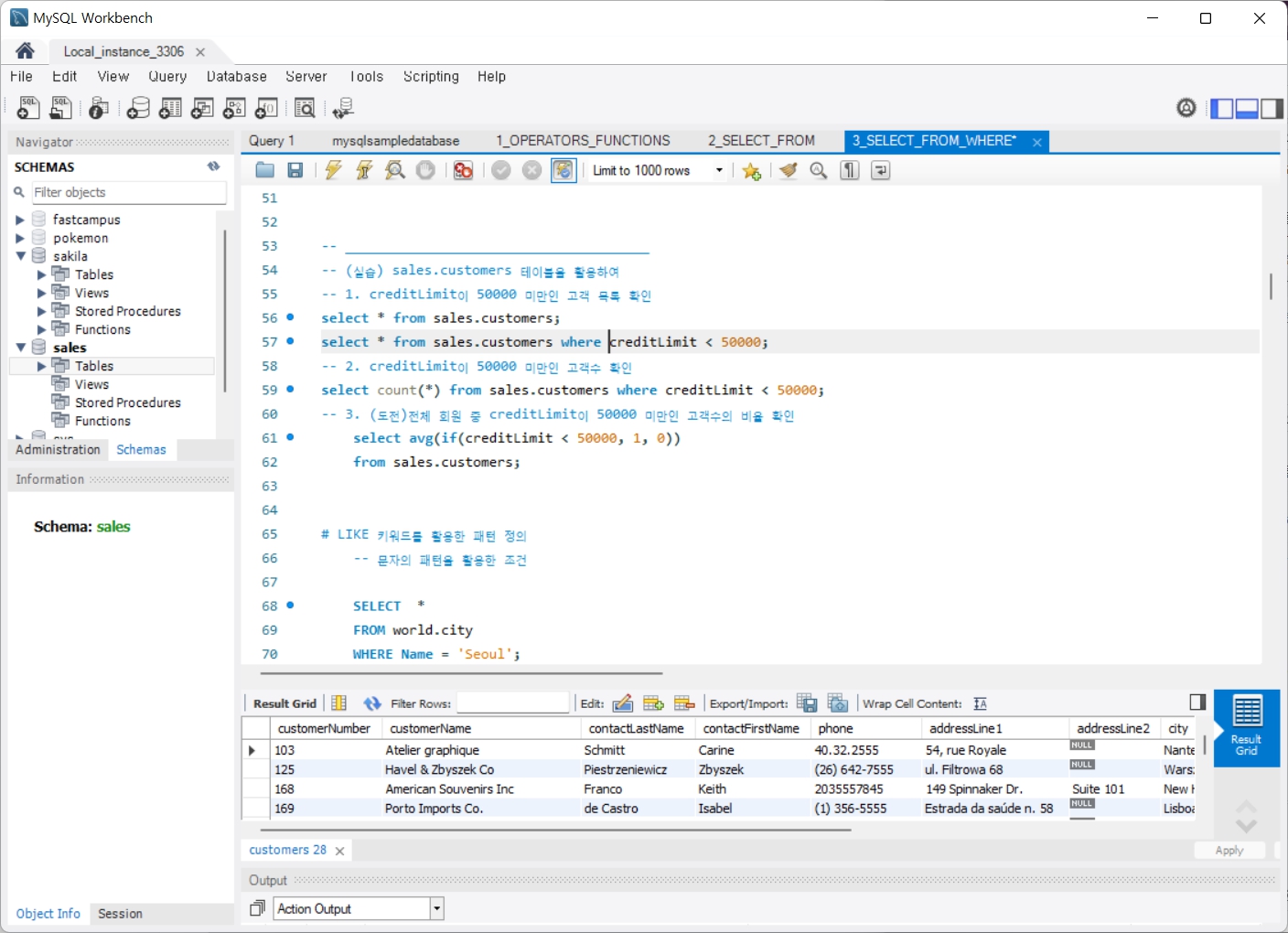







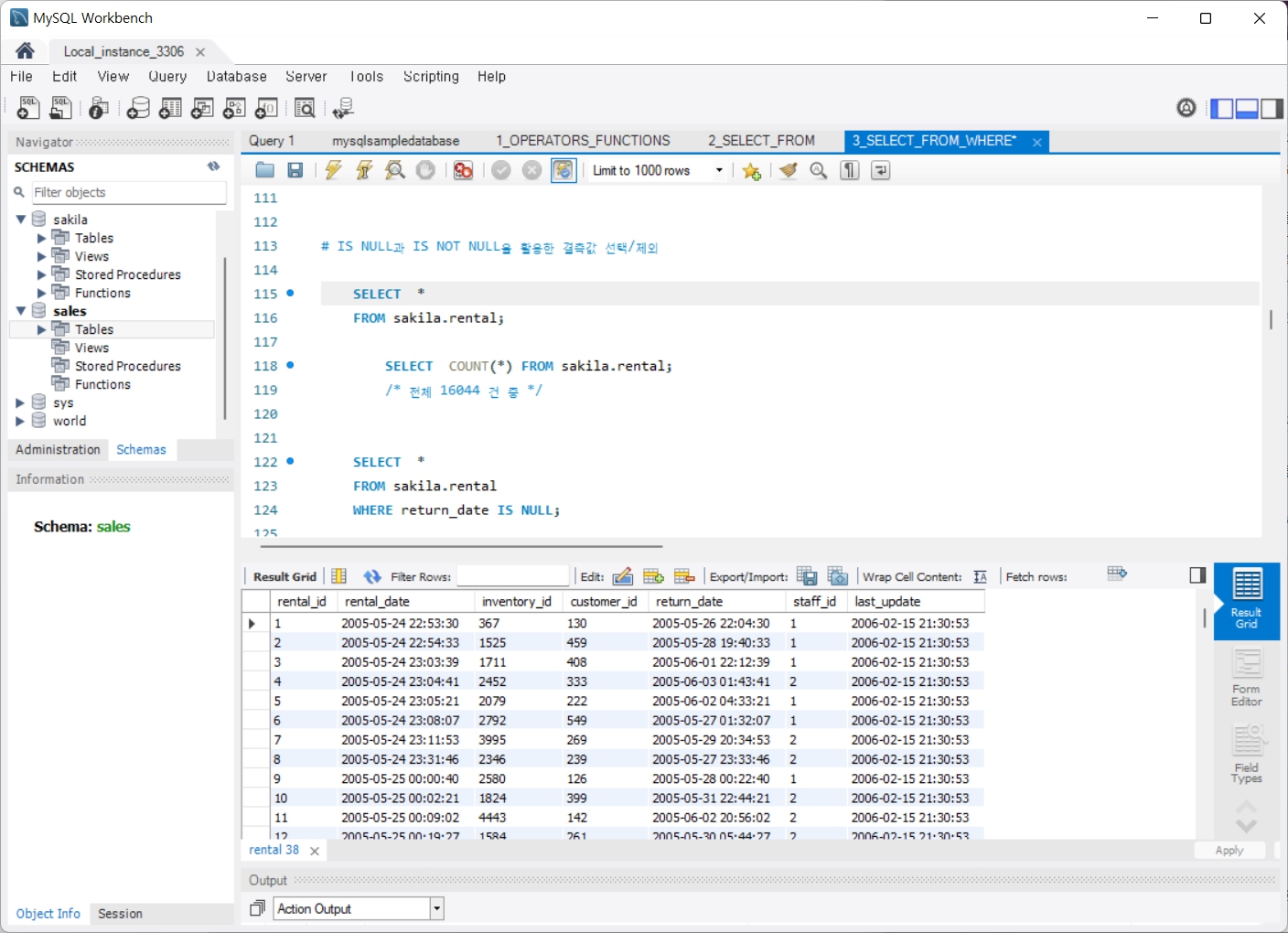
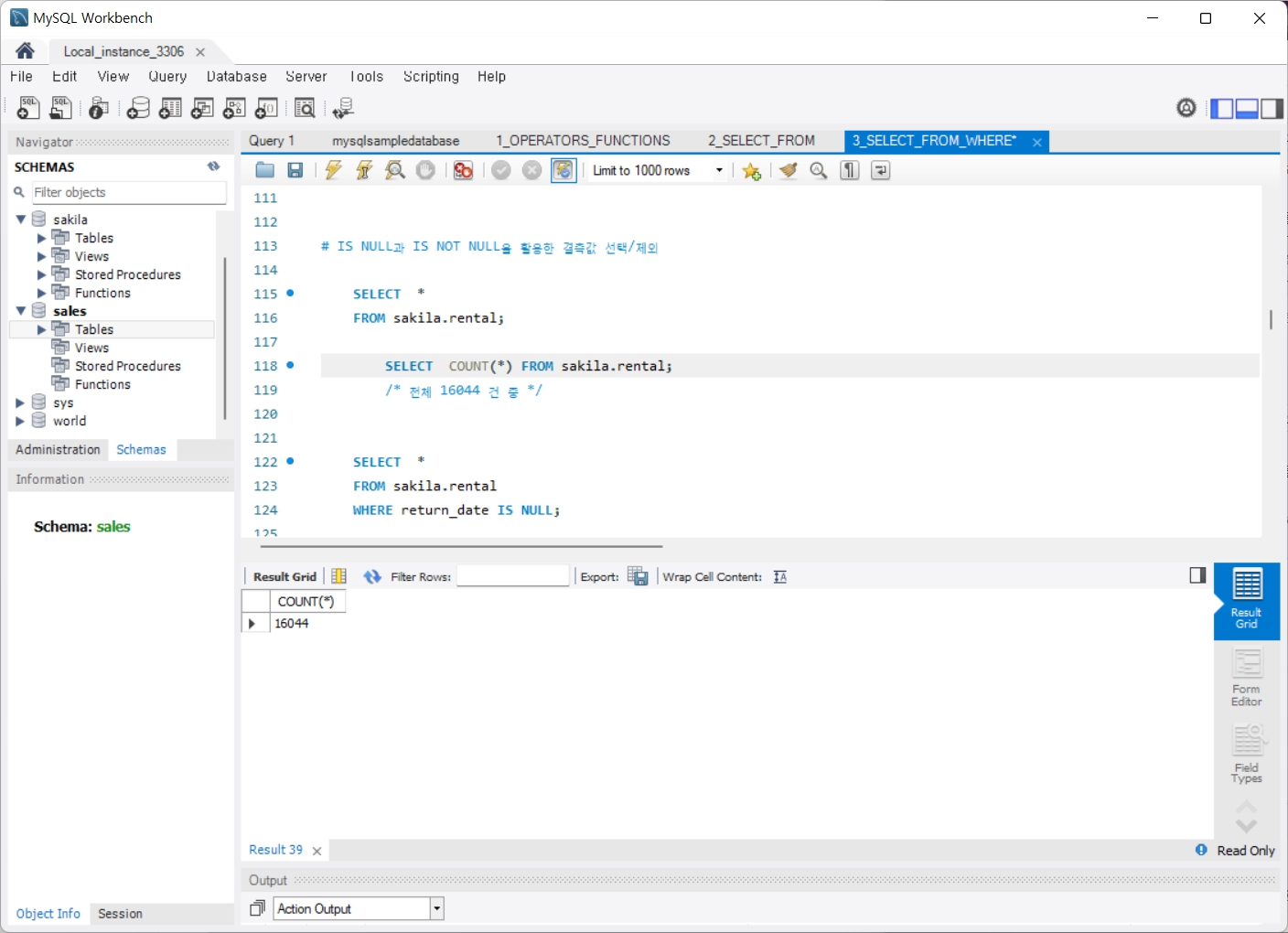












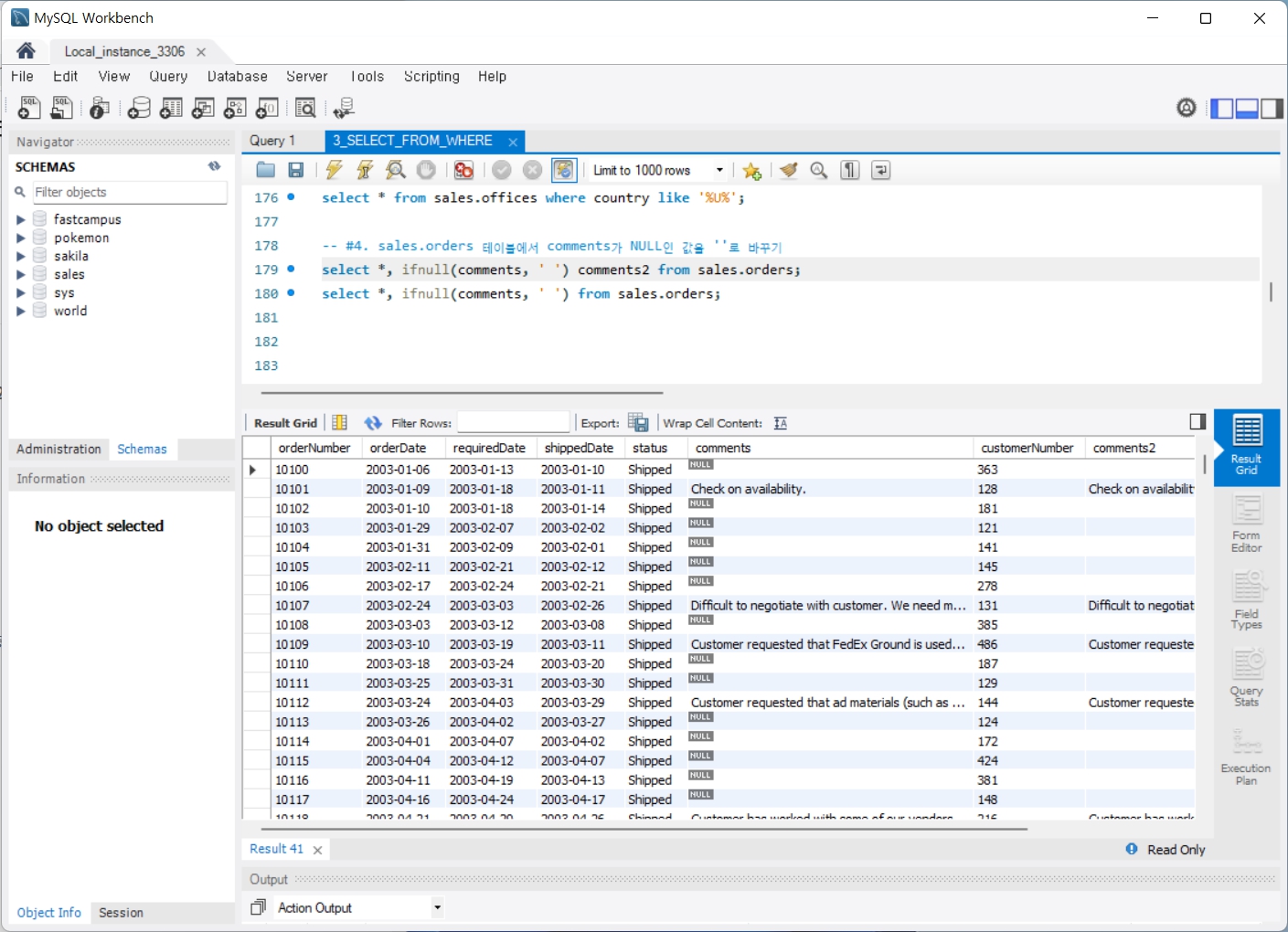


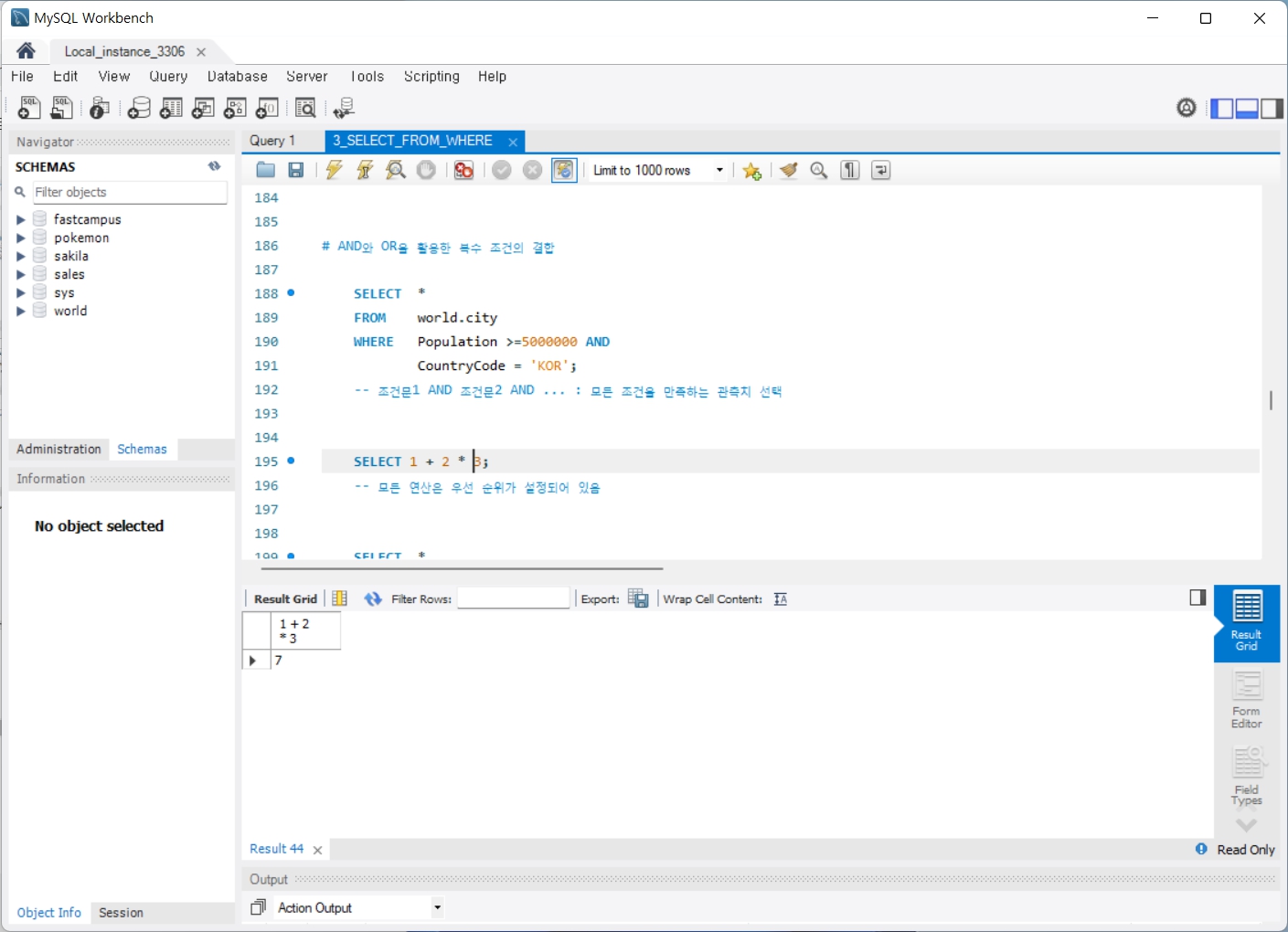

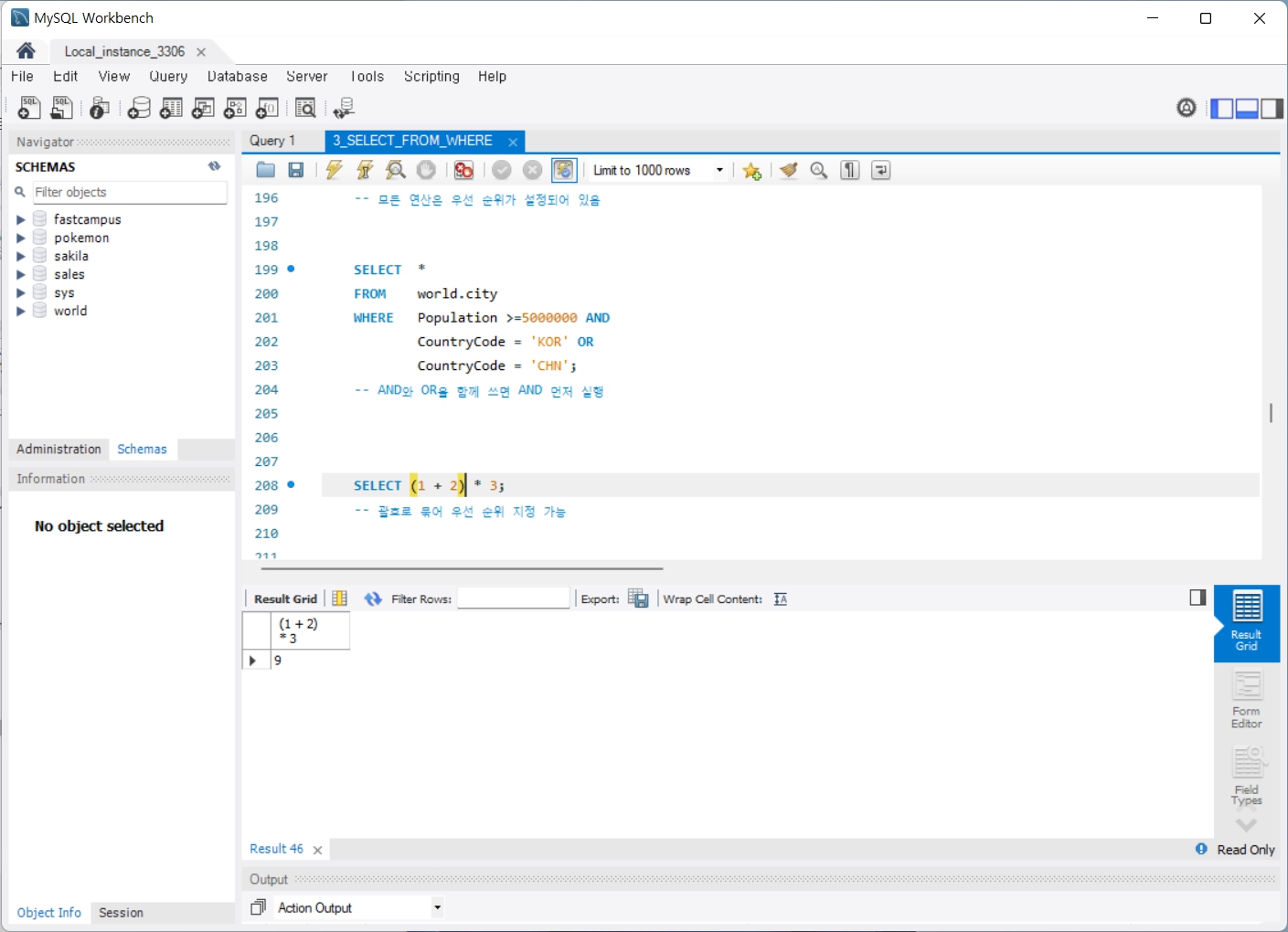
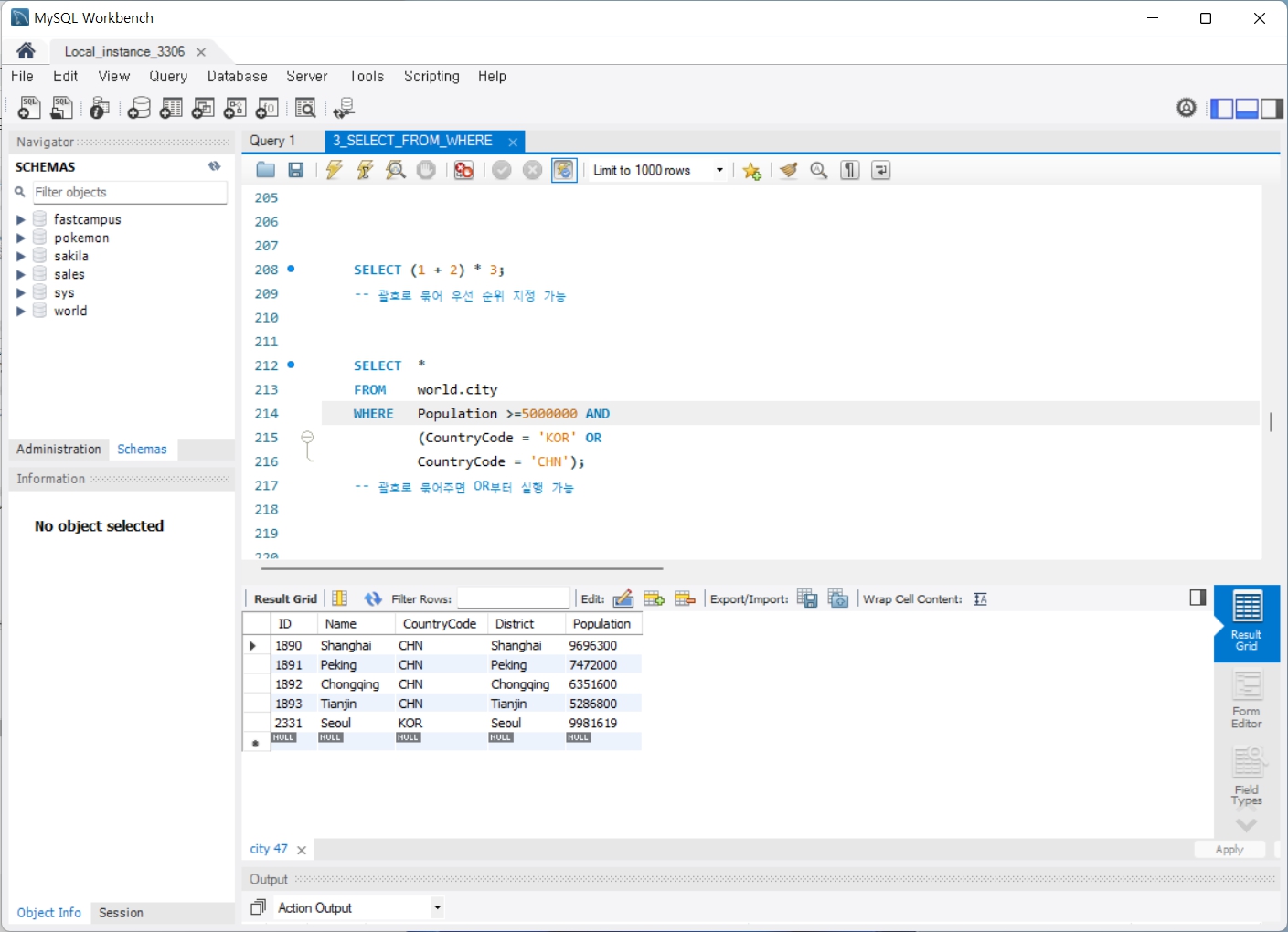
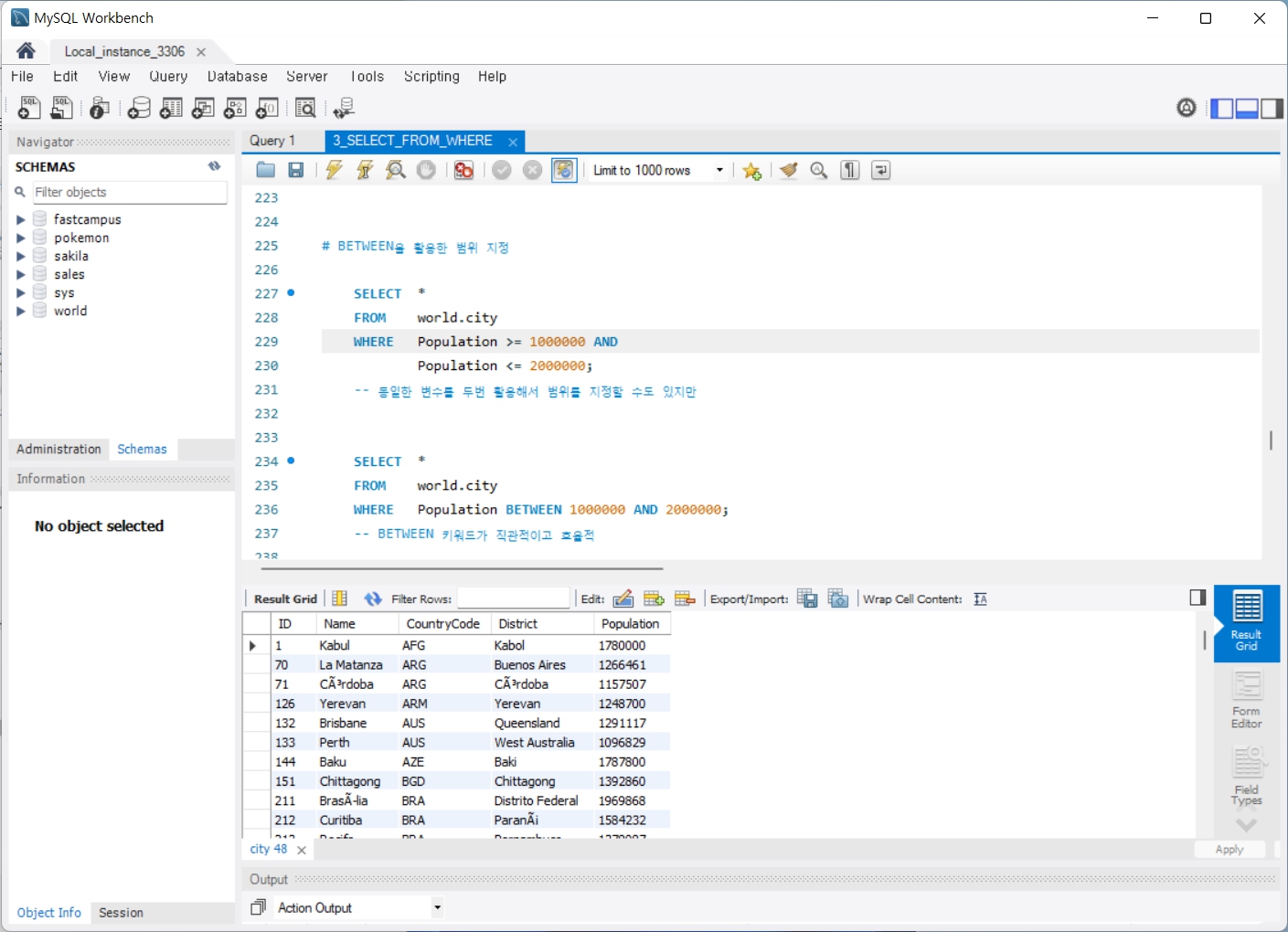














4. GROUP BY













5. ORDER BY









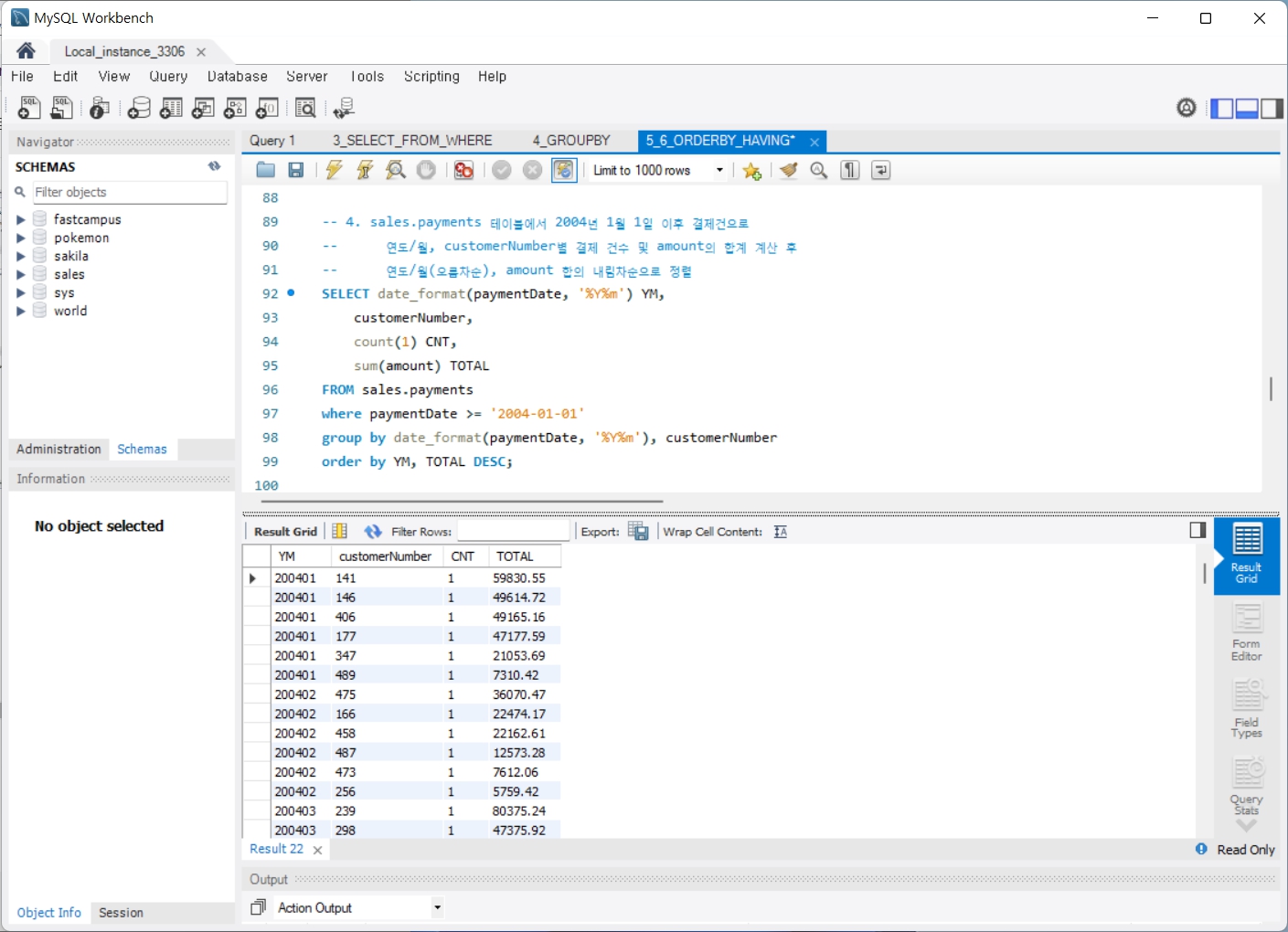

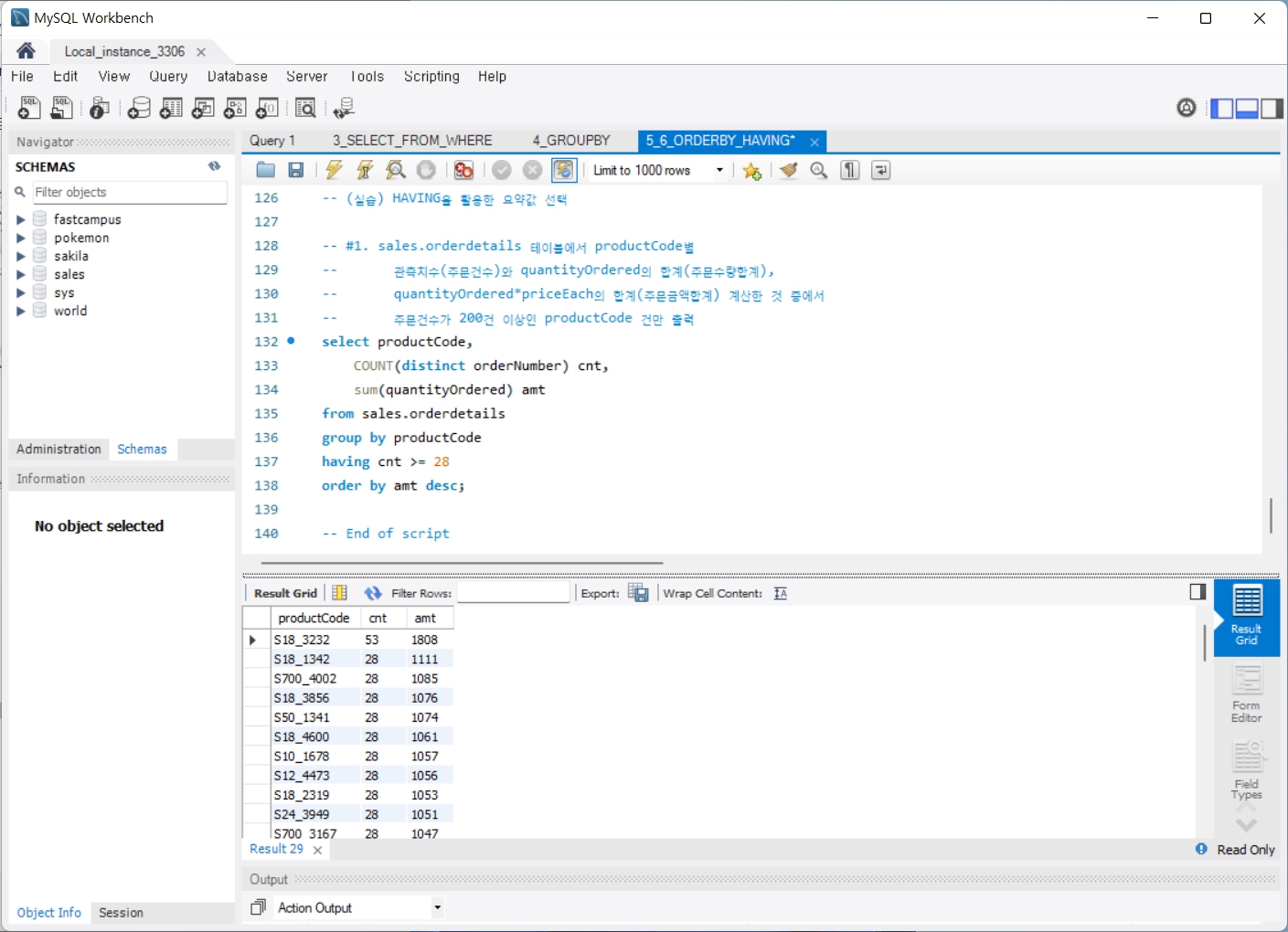
6. HAVING


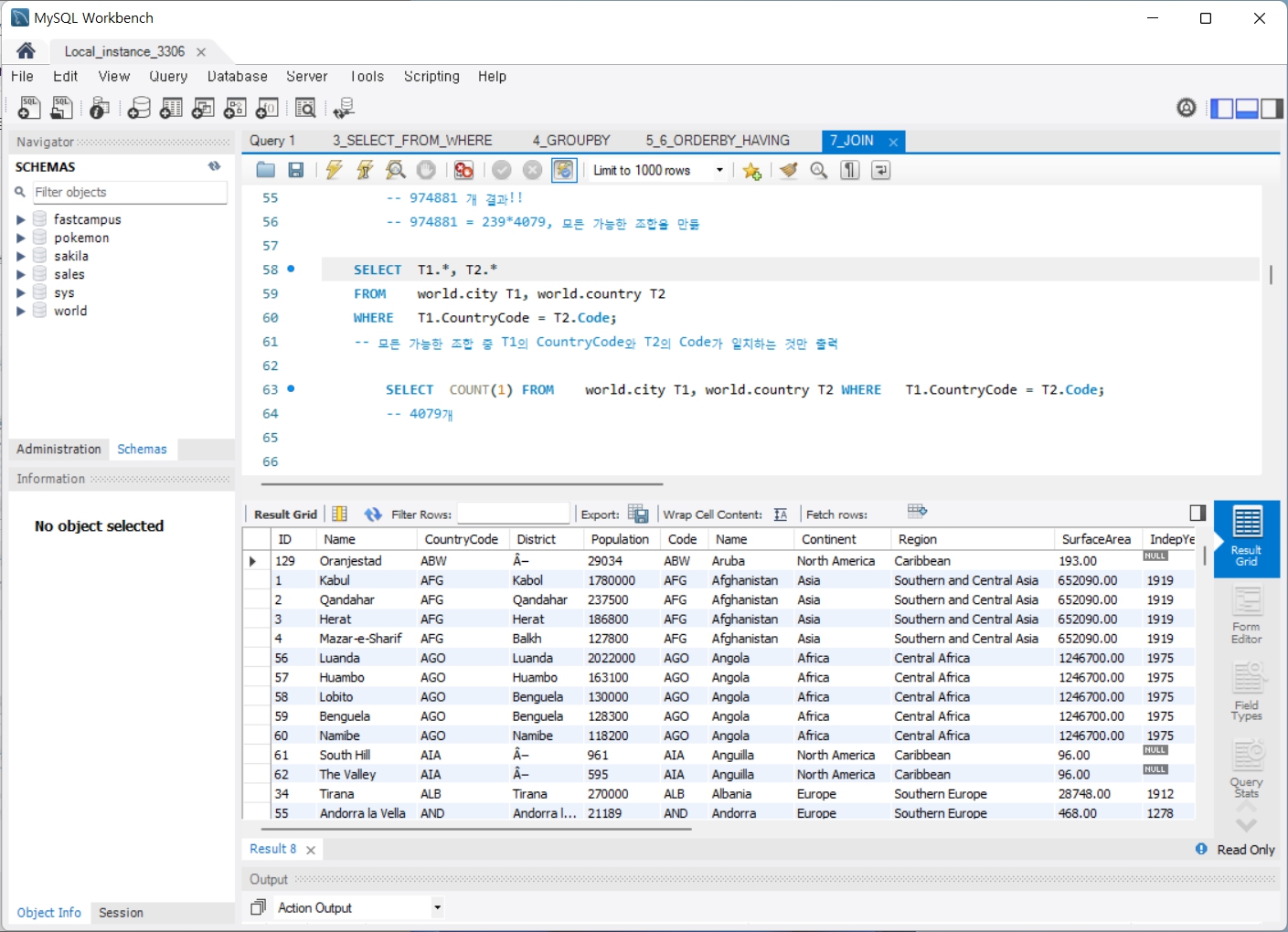
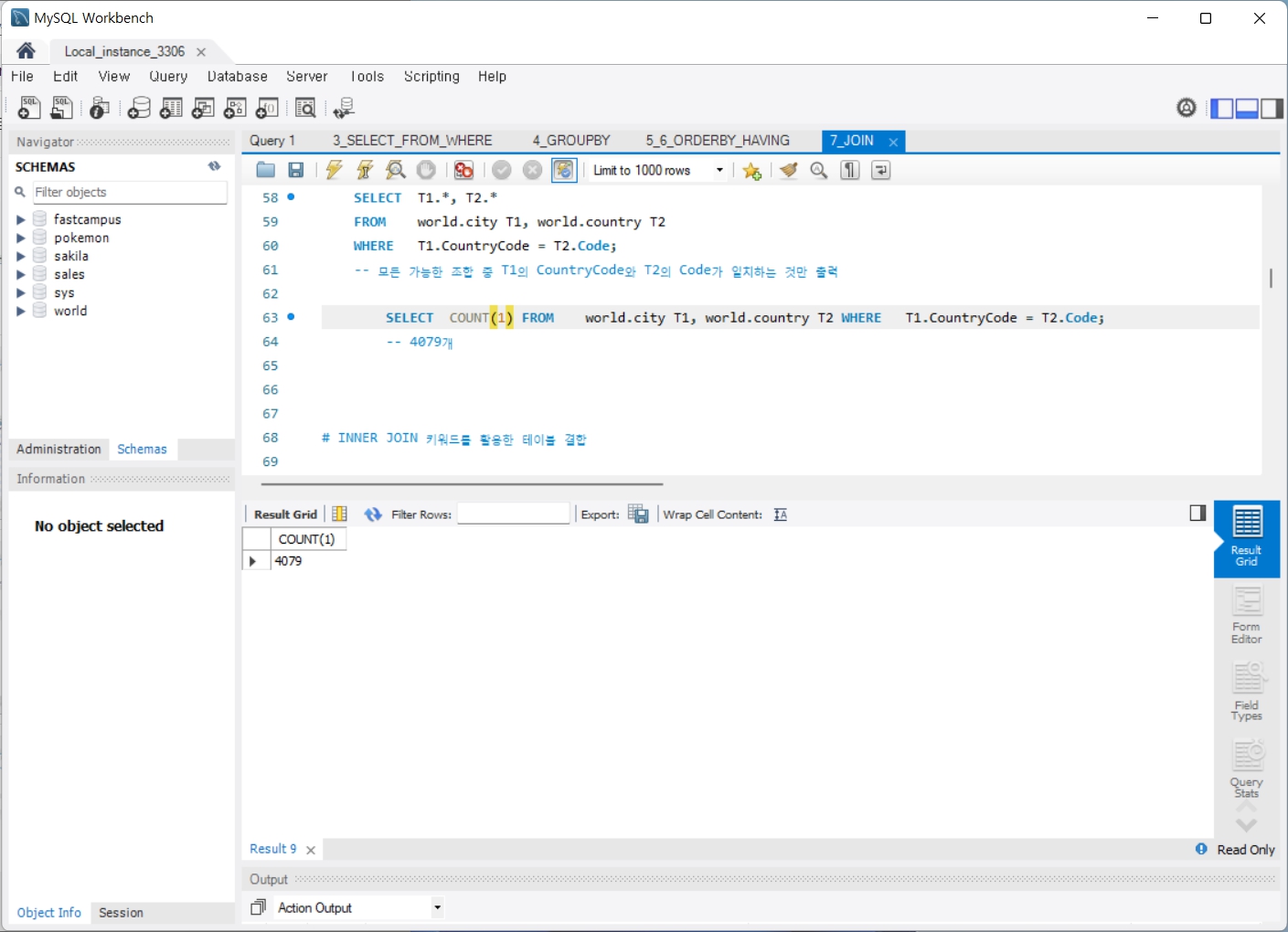
7. JOIN







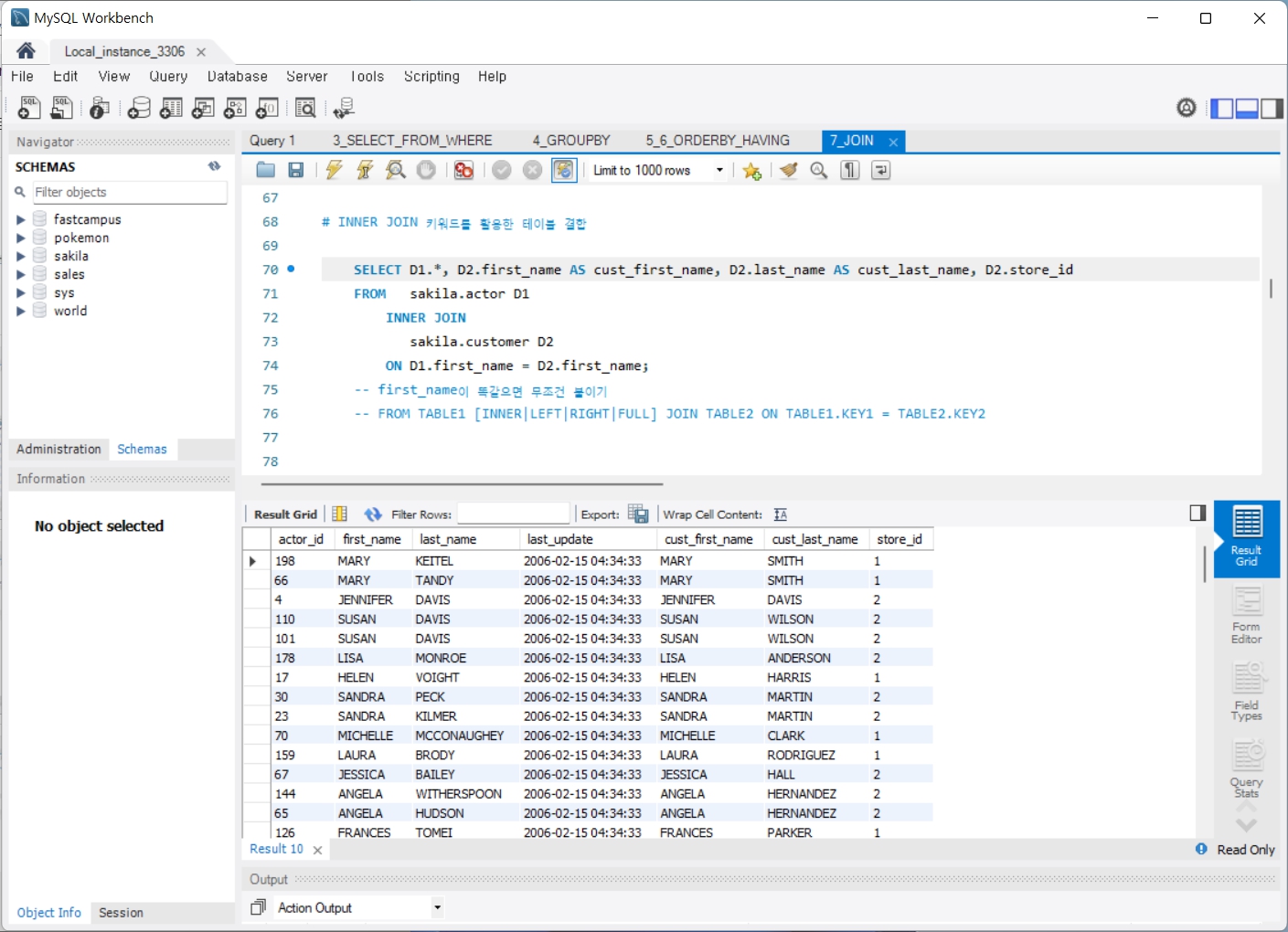












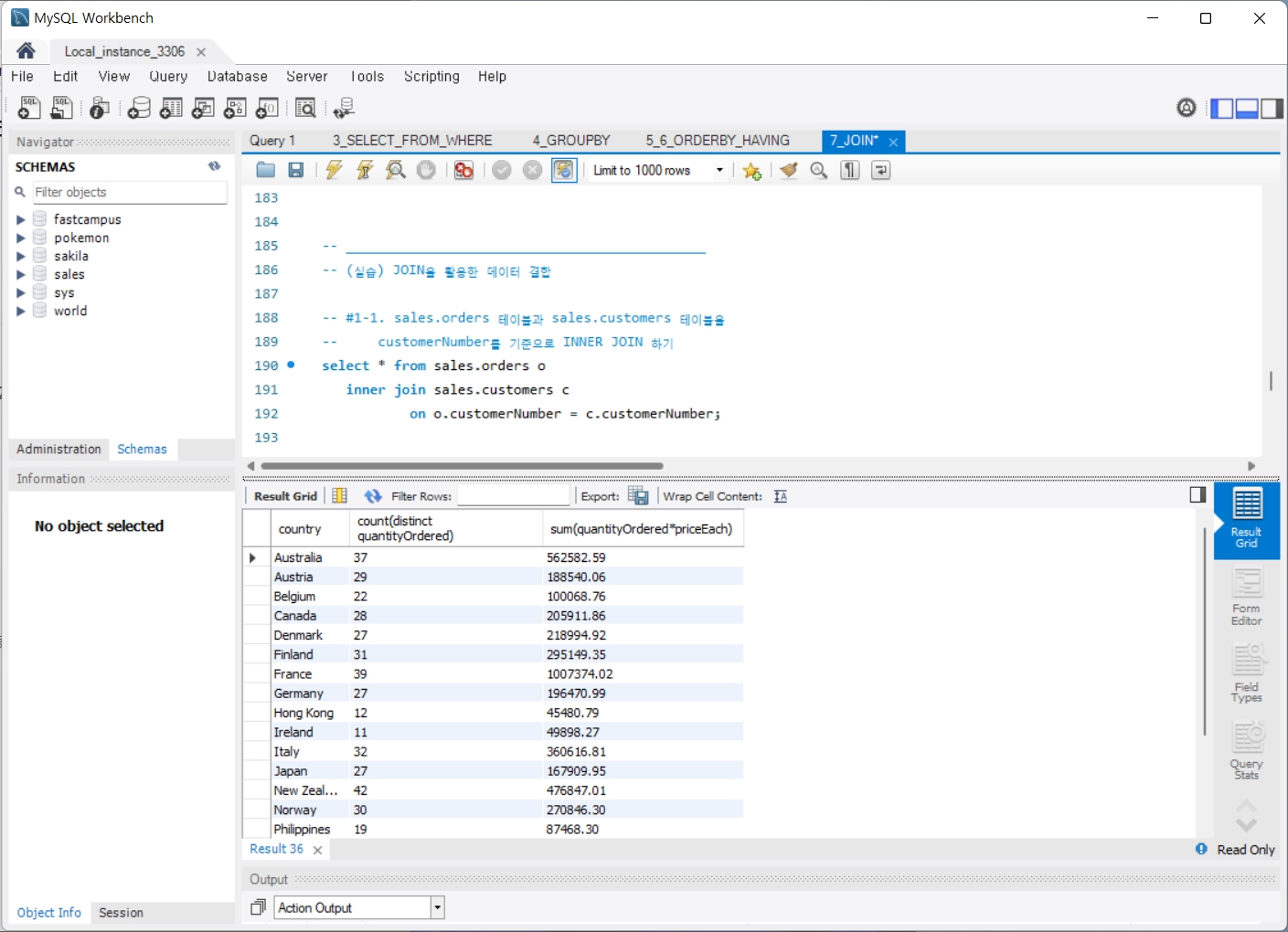




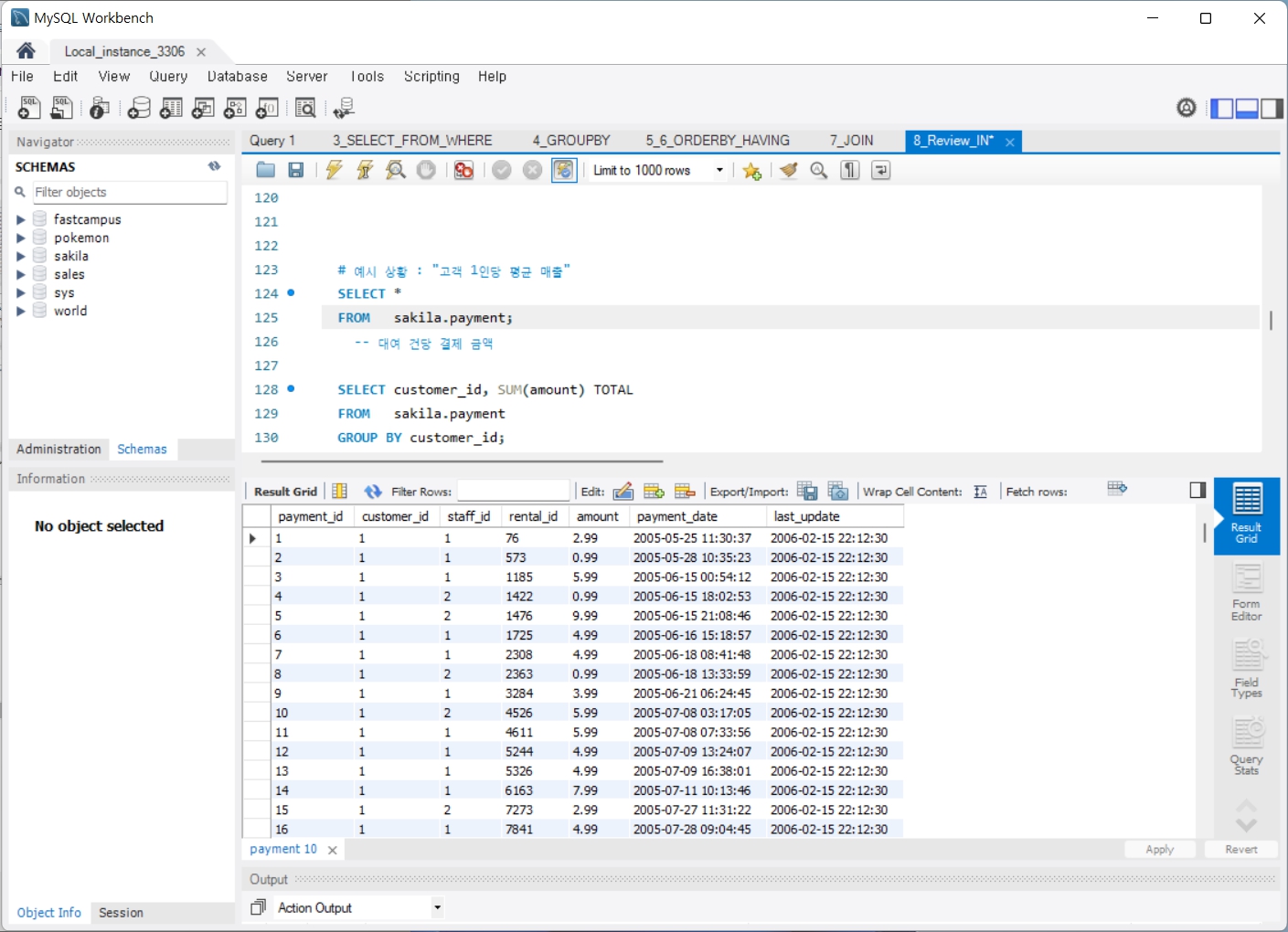
8. Review_IN
group by & order by





서브쿼리와 join





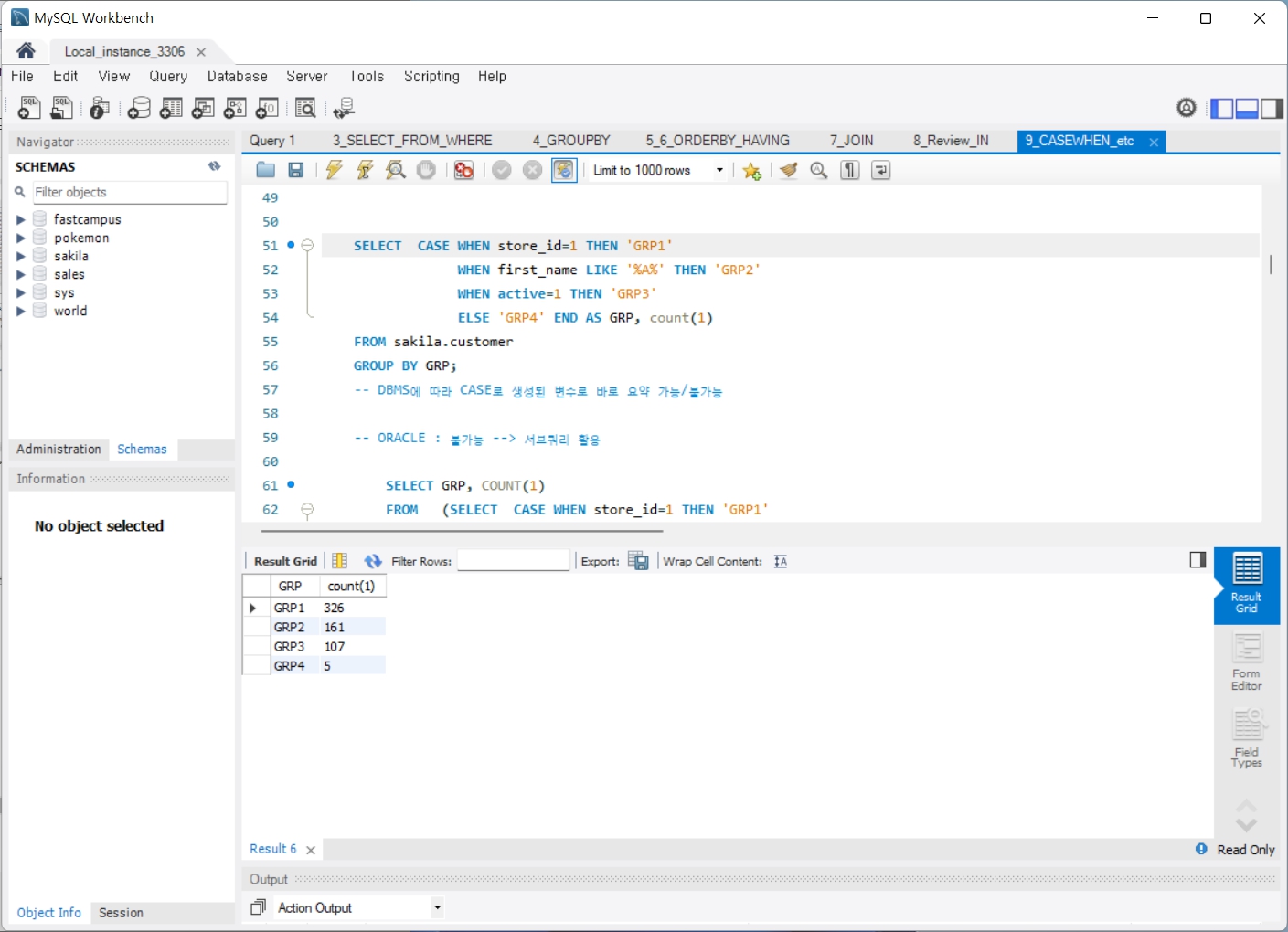
9. CASEWHEN_etc
















KDT(MGS BDA 5기) - 한 번에 끝내는 직장인을 위한 파이썬 데이터 분석 초격차 패키지 Online.
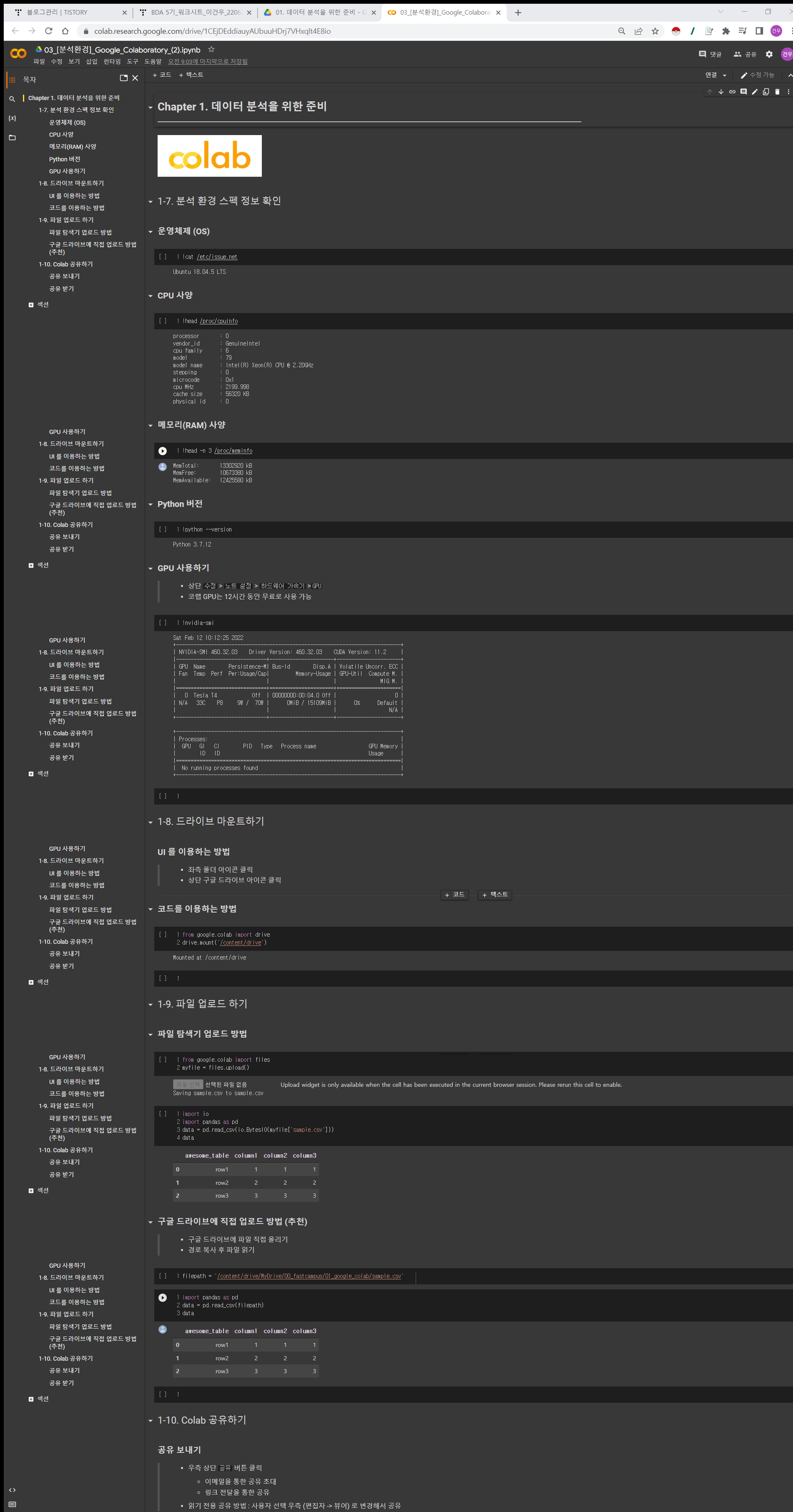
데이터 분석을 위한 준비
우리가 파이썬을 사용해야 하는 이유
Python이란
- 프로그래밍언어로 문법이 쉬워서 비전공자도 빠르게 적응해서 빠르게 성장
- 풍부한 라이브러리로 개발 생산성 상위
- 다양한 플랫폼에서 자유롭게 사용
무엇을 사용해야 할까?
- excel의 경우 자주 쓰는 기능으로 반복작업자동화에 적합하지만 문제가 복잡할수록 값을 구현 및 처리에 한계(피벗테이블을 불러오는데 시간이 걸림)
- python의 경우 대용량데이터, 복잡한처리, 고차원분석에 적합하며 엑셀의 기능까지 모두 구현이 가능(코드1줄로 0.5초 이내에 구동됨)
파이썬으로 가능한 일과 그렇지 않은 것
- 업무자동화 프로그래밍, 데이터분석, 머신러닝, 웹프로그래밍, 다른언어와 결합 등
- 시스템과 밀접한 프로그래밍(운영체제), 모바일앱개발
수강을 진행할 대상
- 코딩이나 파이썬을 처음 접하는 입문자
- 파이썬을 사용해서 번거로운 작업을 엑셀보다 효과적으로 줄이기
- 데이터사이언티스트입문 희망
- 비전공자임에도 이 강의를 들어도 되는지 망설이는 분
강의에서 다룰 내용
- 데이터분석에 필요한 파이썬핵심문법과 라이브러리학습
- 핵심라이브러리와 익숙해지기 위한 치트시트 및 실습예제제공
- 파이썬데이터분석 전과정(수집, 전처리, 예측분석, 시각화) 단계별 End to End 학습
python 데이터분석 파이프라인
| 분석환경준비>>> | 데이터전처리>>> | 데이터시각화>>> | 예측분석 |
| python+colab | numpy, pandas | matplotlib, seaborn, folium | scikit learn |
분석 환경설정-Google Collaboratory
소개 및 기본 세팅
- 코랩(colab)은 구글이 제공하는 클라우드 파이썬개발환경서비스
- 별도의 파이썬설치없이 웹브라우저에서 진행
- 분석기본패키지와 플러그인이 이미 준비
- 코드쉐어링기능으로 사람들과 동시협업
- GPU, TPU사용량을 일정부분 무료제공
- pre-installed 라이브러리
- 데이터분석환경에 적합
- 기존의 Anaconda는 수동라이브러리를 설치한 후 로컬에 저장하며 Git 등 버전관리툴 사용하며 로컬하드웨어사양에 의존하면서 개발환경에 적합
- colab과 anaconda의 장점을 합친 jupyter
- 구글계정로그인
- 구글드라이브 이동
- '새로만들기' > 더보기 > 연결할 앱 더보기 > 검색창에 Colaboratory입력 > 설치
- 'Google Colaboratory를 파일을 여는 기본앱으로 설정하세요' 체크확인
- 구글드라이브에 강의실습자료를 통째로 내 컴퓨터에 업로드
- 구글드라이브에서 노트북(.ipynb)파일을 더블클릭해서 colab환경으로 실행




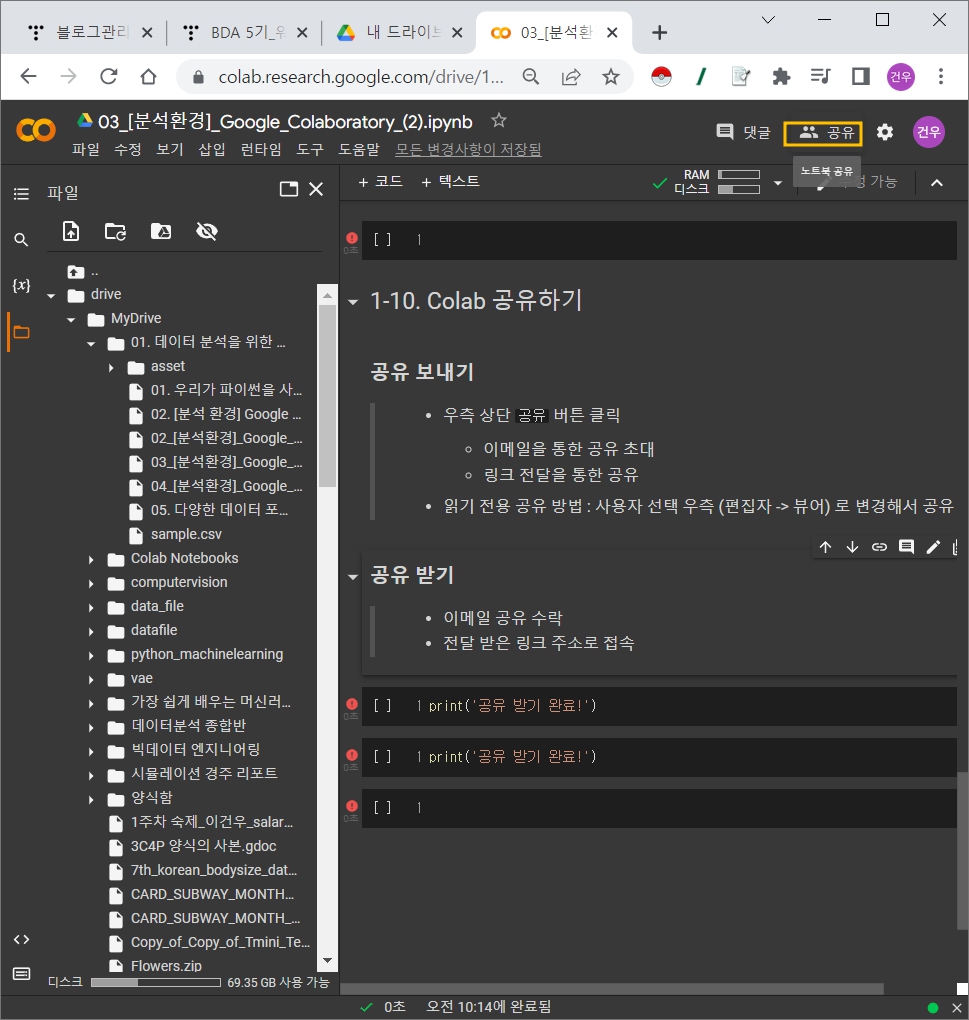
파일 업로드와 공유





















마크다운과 그밖의 기능들






























다양한 데이터 포맷 이해하기
파일형식: txt, csv, json, xml
데이터세트의 종류
정형데이터세트 (사람들이 이해하기 좋은 형태)
- 텍스트파일(txt, csv, bat 등)
- 소프트웨어 전용 파일(excel, spss 등)
- 데이터베이스파일(DB)
- 대표라이브러리는 pandas
반정형데이터세토(비정형+정형)
- json파일(key-value 쌍으로 이뤄짐)로 웹에서 데이터를 교환할 때 사용
- xml파일(tag로 대이터를 설명)로 html보다 자유로운 태그가능
- 대표라이브러리는 json(내장함수)
비정형데이터세트(행과 열의 개념이 없는 형태)
- 이미지파일(jpg, png)
- 멀티미디어파일(오디오, 동영상)
- 바이너리파일(0과 1로 이뤄짐)
- 대표라이브러리는 OpenCV
파이썬 기초 프로그래밍
노트북파일(ipynb) 불러오기


파이썬 기초 문법 따라해



파이썬 자료형





파이썬 제어문과 함수

파이썬 프로그램의 입력과 출력

고급 기능 (list comprehension, 예외처리, 모듈화)



파이썬을 활용한 데이터 전처리
numpy
numpy란?


numpy 데이터 슬라이싱과 정렬



numpy matrix(행렬) 연산과 성능



pandas
pandas란?
- 데이터조작과 분석을 위한 파이썬 소프트웨어 라이브러리
- 표(행렬) 형태의 데이터를 조작하는데 매우 특화
- 대용량데이터 셋을 이용한 다양한 통계처리기능제공
- 엑셀이 제공하는 거의 모든 기능을 구현(데이터베이스(SQL)문 포함)
- Panel Data System(=Python Data Analysis)
- 엑셀로 작성한 파일이 호환
Pandas에서 사용되는 데이터유형
- 1차원배열 시리즈(series)가 인덱스(Indes)로만 구성
- 2차원배열 데이터프레임(Dataframe)이 컬럼과 인덱스로 구성
Pandas로 가능한 일
엑셀전처리
- 데이터베이스(SQL)
- 크롤링(웹수집)
- 시각화
pandas에서 csv, excel 파일 읽기, 요약 정보 한눈에 확인하기














pandas에서 데이터슬라이싱


pandas에서 통계값계산과 정렬

pandas에서 피벗테이블과 그룹통계

pandas에서 데이터프레임 합치기 (Join 과 Merge)

pandas에서 자료형변환, 산술연산




pandas에서 결측값, 중복처리

pandas에서 고급기능 (apply, lambda, map) 알아보기

pandas에서 데이터프레임 시각화



pandas에서 실습예제



파이썬을 활용한 데이터 시각화
matplotlib
matplotlib란?
- 자료를 Chart로 Plot하는 파이썬기반 시각화라이브러리이자 표준시각화도구
- 표현할 수 없는 그래프가 없을 정도로 다양한 그래프 유형 제공
- 세부옵션조정으로 커스터마이징 가능
- Numpy, Pandas라이브러리와 유연한 연동성




데이터타입에 따른 그래프시각화
- 연속형데이터간 상관관계, 변화량측면에서 산점도(Scatter), 밀도(Densiy), 그래프로
- 범주형데이터로 항목과 그룹간 비교, 비율, 순위형 자료를 박스(Box), 바(Bar), 파이(Pie), 히트맵(Heat map)으로
- 시계열데이터로 날짜나 요일 등 시간단위데이터의 경향성, 흐름을 라인(Line), 리본(Ribbon), VEB그래프로
matplotlib의 구성요소와 기본그래프



matplotlib의 그래프 유형별 시각화




seaborn
seaborn란?
- Matplotlib에서 색상테마, 통계용차트 기능을 추가한 시각화 라이브러리로 통계데이터시각화에 최적화됨
- 매력적이고 유익한 통계그래픽을 위한 고레벨 인터페이스
- matplotlib그래프보다 예쁘게 나옴
- 실실전분석에서는 matplotlib과 seaborn을 함께 사용
| 특징 | matplotlib | seaborn |
| 사용용도 | Pandas와 Numpy를 활용해서 다양한 플롯팅 | Matplotlib의 확장버전이지만 용도는 동일함 |
| 문법 | 비교적 복잡한 문법으로 커스터마이징시 코드가길어짐 | 비교적 간단한문법으로 학습과 이해가 수월 |
| 다중 Figure | 다중그래프를 지원하지만 옵션을 세부적으로 설정필요 | 다중그래프 자동화생성기능 존재 |
| 유연성 | 커스터마이징 유연성이 매우 높음 | 자체적으로 제공하는 테마 외에는 유연성 떨어짐 |
seaborn과 matplotlib



seaborn으로 그래프 유형별 시각화


'데이터분석_워크시트' 카테고리의 다른 글
| BDA 5기_워크시트_이건우_220707 (0) | 2022.07.01 |
|---|---|
| BDA 5기_워크시트_이건우_220630 (0) | 2022.06.24 |
| BDA 5기_워크시트_이건우_220616 (0) | 2022.06.10 |
| BDA 5기_워크시트_이건우_220609 (0) | 2022.06.08 |
| BDA 5기_워크시트_이건우_220602 (0) | 2022.06.03 |



